 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower-Softmax: Towards Secure LLM Inference over Encrypted Data
Oct 12, 2024



Modern cryptographic methods for implementing privacy-preserving LLMs such as Homomorphic Encryption (HE) require the LLMs to have a polynomial form. Forming such a representation is challenging because Transformers include non-polynomial components, such as Softmax and layer normalization. Previous approaches have either directly approximated pre-trained models with large-degree polynomials, which are less efficient over HE, or replaced non-polynomial components with easier-to-approximate primitives before training, e.g., Softmax with pointwise attention. The latter approach might introduce scalability challenges. We present a new HE-friendly variant of self-attention that offers a stable form for training and is easy to approximate with polynomials for secure inference. Our work introduces the first polynomial LLMs with 32 layers and over a billion parameters, exceeding the size of previous models by more than tenfold. The resulting models demonstrate reasoning and in-context learning (ICL) capabilities comparable to standard transformers of the same size, representing a breakthrough in the field. Finally, we provide a detailed latency breakdown for each computation over encrypted data, paving the way for further optimization, and explore the differences in inductive bias between transformers relying on our HE-friendly variant and standard transformers. Our code is attached as a supplement.
Converting Transformers to Polynomial Form for Secure Inference Over Homomorphic Encryption
Nov 15, 2023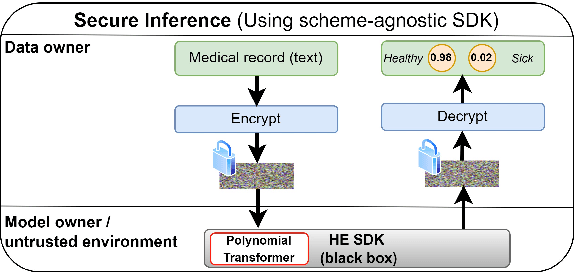
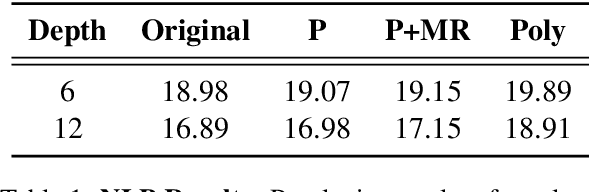
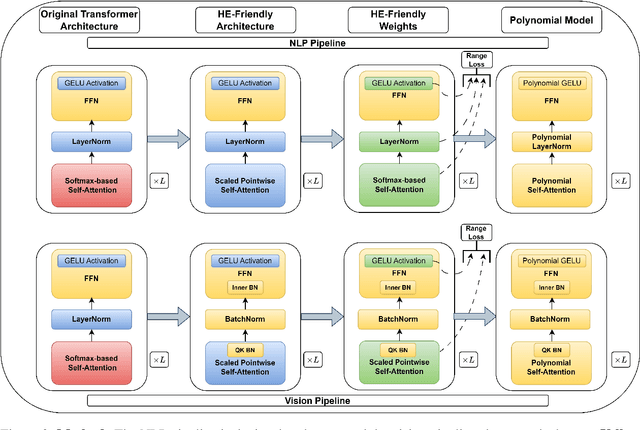

Designing privacy-preserving deep learning models is a major challenge within the deep learning community. Homomorphic Encryption (HE) has emerged as one of the most promising approaches in this realm, enabling the decoupling of knowledge between the model owner and the data owner. Despite extensive research and application of this technology, primarily in convolutional neural networks, incorporating HE into transformer models has been challenging because of the difficulties in converting these models into a polynomial form. We break new ground by introducing the first polynomial transformer, providing the first demonstration of secure inference over HE with transformers. This includes a transformer architecture tailored for HE, alongside a novel method for converting operators to their polynomial equivalent. This innovation enables us to perform secure inference on LMs with WikiText-103. It also allows us to perform image classification with CIFAR-100 and Tiny-ImageNet. Our models yield results comparable to traditional methods, bridging the performance gap with transformers of similar scale and underscoring the viability of HE for state-of-the-art applications. Finally, we assess the stability of our models and conduct a series of ablations to quantify the contribution of each model component.
Privacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.
Sensitive Tuning of Large Scale CNNs for E2E Secure Prediction using Homomorphic Encryption
Apr 26, 2023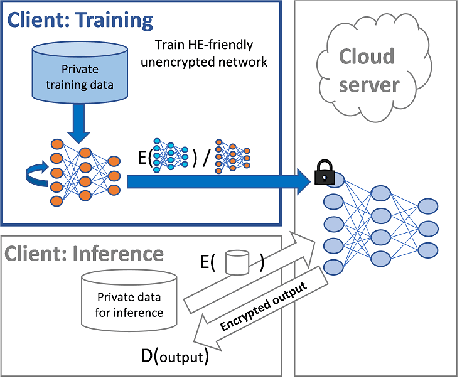

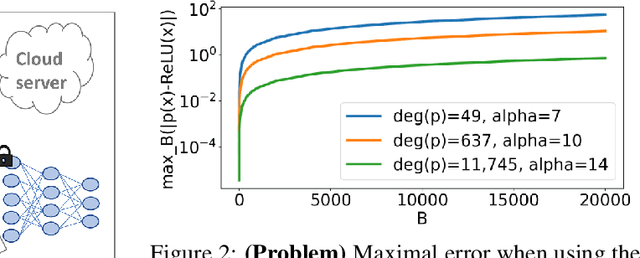
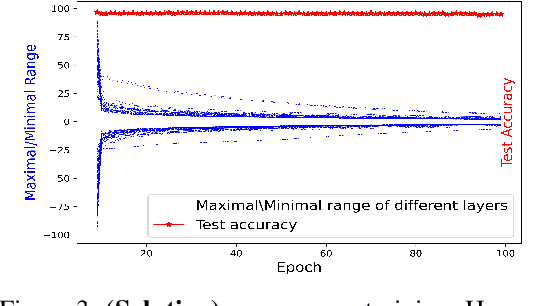
Privacy-preserving machine learning solutions have recently gained significant attention. One promising research trend is using Homomorphic Encryption (HE), a method for performing computation over encrypted data. One major challenge in this approach is training HE-friendly, encrypted or unencrypted, deep CNNs with decent accuracy. We propose a novel training method for HE-friendly models, and demonstrate it on fundamental and modern CNNs, such as ResNet and ConvNeXt. After training, we evaluate our models by running encrypted samples using HELayers SDK and proving that they yield the desired results. When running on a GPU over the ImageNet dataset, our ResNet-18/50/101 implementations take only 7, 31 and 57 minutes, respectively, which shows that this solution is practical. Furthermore, we present several insights on handling the activation functions and skip-connections under HE. Finally, we demonstrate in an unprecedented way how to perform secure zero-shot prediction using a CLIP model that we adapted to be HE-friendly.
HE-PEx: Efficient Machine Learning under Homomorphic Encryption using Pruning, Permutation and Expansion
Jul 07, 2022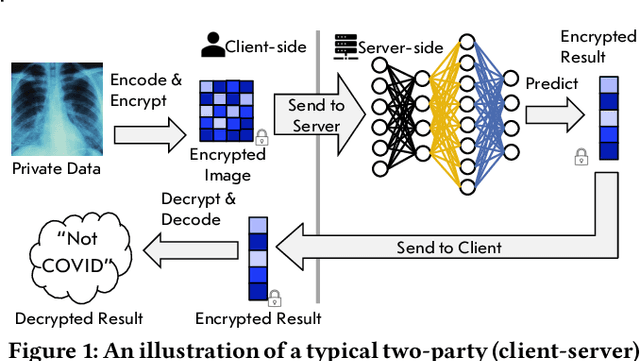

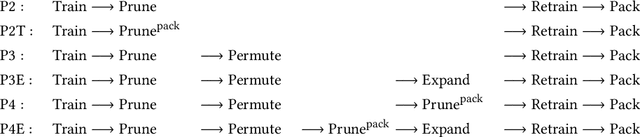
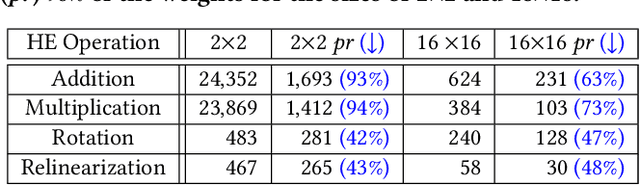
Privacy-preserving neural network (NN) inference solutions have recently gained significant traction with several solutions that provide different latency-bandwidth trade-offs. Of these, many rely on homomorphic encryption (HE), a method of performing computations over encrypted data. However, HE operations even with state-of-the-art schemes are still considerably slow compared to their plaintext counterparts. Pruning the parameters of a NN model is a well-known approach to improving inference latency. However, pruning methods that are useful in the plaintext context may lend nearly negligible improvement in the HE case, as has also been demonstrated in recent work. In this work, we propose a novel set of pruning methods that reduce the latency and memory requirement, thus bringing the effectiveness of plaintext pruning methods to HE. Crucially, our proposal employs two key techniques, viz. permutation and expansion of the packed model weights, that enable pruning significantly more ciphertexts and recuperating most of the accuracy loss, respectively. We demonstrate the advantage of our method on fully connected layers where the weights are packed using a recently proposed packing technique called tile tensors, which allows executing deep NN inference in a non-interactive mode. We evaluate our methods on various autoencoder architectures and demonstrate that for a small mean-square reconstruction loss of 1.5*10^{-5} on MNIST, we reduce the memory requirement and latency of HE-enabled inference by 60%.
Tile Tensors: A versatile data structure with descriptive shapes for homomorphic encryption
Nov 03, 2020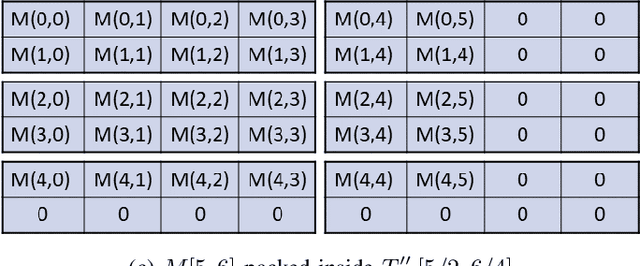

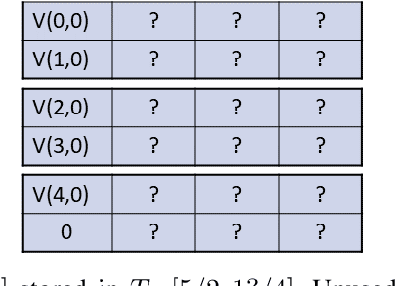
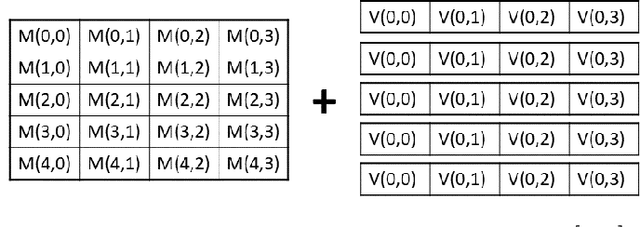
Moving from the theoretical promise of Fully Homomorphic Encryption (FHE) to real-world applications with realistic and acceptable time and memory figures is an on-going challenge. After choosing an appropriate FHE scheme, and before implementing privacy-preserving analytics, one needs an efficient packing method that will optimize use of the ciphertext slots, trading-off size, latency, and throughput. We propose a solution to this challenge. We describe a method for efficiently working with tensors (multi-dimensional arrays) in a system that imposes tiles, i.e., fixed-size vectors. The tensors are packed into tiles and then manipulated via operations on those tiles. We further show a novel and concise notation for describing packing details. Our method reinterprets the tiles as multi-dimensional arrays, and combines them to cover enough space to hold the tensor. An efficient summation algorithm can then sum over any dimension of this construct. We propose a descriptive notation for the shape of this data structure that describes both the original tensor and how it is packed inside the tiles. Our solution can be used to optimize the performance of various algorithms such as consecutive matrix multiplications or neural network inference with varying batch sizes. It can also serve to enhance optimizations done by homomorphic encryption compilers. We describe different applications that take advantage of this data structure through the proposed notation, experiment to evaluate the advantages through different applications, and share our conclusions.