 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attacks Against Time-Series Models
Jul 03, 2024



Analyzing time-series data that may contain personal information, particularly in the medical field, presents serious privacy concerns. Sensitive health data from patients is often used to train machine-learning models for diagnostics and ongoing care. Assessing the privacy risk of such models is crucial to making knowledgeable decisions on whether to use a model in production, share it with third parties, or deploy it in patients homes. Membership Inference Attacks (MIA) are a key method for this kind of evaluation, however time-series prediction models have not been thoroughly studied in this context. We explore existing MIA techniques on time-series models, and introduce new features, focusing on the seasonality and trend components of the data. Seasonality is estimated using a multivariate Fourier transform, and a low-degree polynomial is used to approximate trends. We applied these techniques to various types of time-series models, using datasets from the health domain. Our results demonstrate that these new features enhance the effectiveness of MIAs in identifying membership, improving the understanding of privacy risks in medical data applications.
SoK: Reducing the Vulnerability of Fine-tuned Language Models to Membership Inference Attacks
Mar 13, 2024Natural language processing models have experienced a significant upsurge in recent years, with numerous applications being built upon them. Many of these applications require fine-tuning generic base models on customized, proprietary datasets. This fine-tuning data is especially likely to contain personal or sensitive information about individuals, resulting in increased privacy risk. Membership inference attacks are the most commonly employed attack to assess the privacy leakage of a machine learning model. However, limited research is available on the factors that affect the vulnerability of language models to this kind of attack, or on the applicability of different defense strategies in the language domain. We provide the first systematic review of the vulnerability of fine-tuned large language models to membership inference attacks, the various factors that come into play, and the effectiveness of different defense strategies. We find that some training methods provide significantly reduced privacy risk, with the combination of differential privacy and low-rank adaptors achieving the best privacy protection against these attacks.
Tile Tensors: A versatile data structure with descriptive shapes for homomorphic encryption
Nov 03, 2020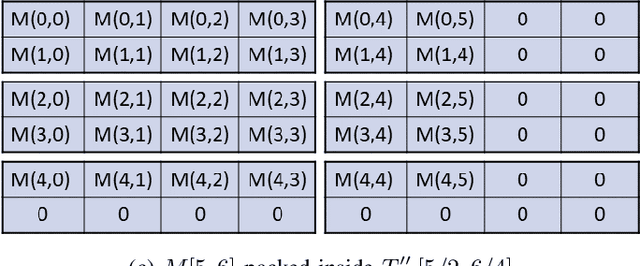

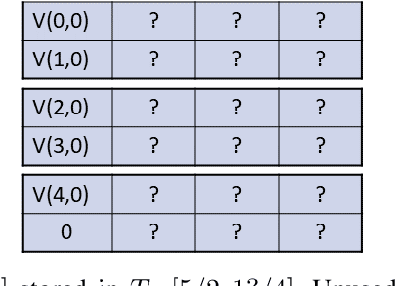
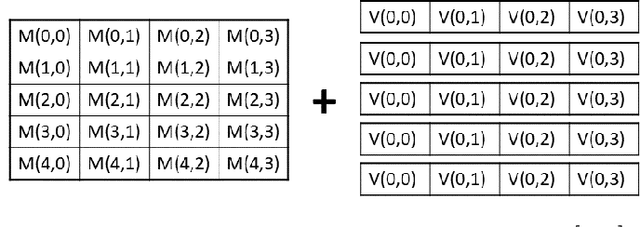
Moving from the theoretical promise of Fully Homomorphic Encryption (FHE) to real-world applications with realistic and acceptable time and memory figures is an on-going challenge. After choosing an appropriate FHE scheme, and before implementing privacy-preserving analytics, one needs an efficient packing method that will optimize use of the ciphertext slots, trading-off size, latency, and throughput. We propose a solution to this challenge. We describe a method for efficiently working with tensors (multi-dimensional arrays) in a system that imposes tiles, i.e., fixed-size vectors. The tensors are packed into tiles and then manipulated via operations on those tiles. We further show a novel and concise notation for describing packing details. Our method reinterprets the tiles as multi-dimensional arrays, and combines them to cover enough space to hold the tensor. An efficient summation algorithm can then sum over any dimension of this construct. We propose a descriptive notation for the shape of this data structure that describes both the original tensor and how it is packed inside the tiles. Our solution can be used to optimize the performance of various algorithms such as consecutive matrix multiplications or neural network inference with varying batch sizes. It can also serve to enhance optimizations done by homomorphic encryption compilers. We describe different applications that take advantage of this data structure through the proposed notation, experiment to evaluate the advantages through different applications, and share our conclusions.
Data Minimization for GDPR Compliance in Machine Learning Models
Aug 06, 2020

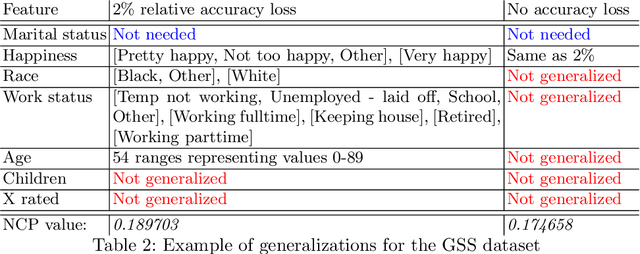
The EU General Data Protection Regulation (GDPR) mandates the principle of data minimization, which requires that only data necessary to fulfill a certain purpose be collected. However, it can often be difficult to determine the minimal amount of data required, especially in complex machine learning models such as neural networks. We present a first-of-a-kind method to reduce the amount of personal data needed to perform predictions with a machine learning model, by removing or generalizing some of the input features. Our method makes use of the knowledge encoded within the model to produce a generalization that has little to no impact on its accuracy. This enables the creators and users of machine learning models to acheive data minimization, in a provable manner.
Anonymizing Machine Learning Models
Jul 26, 2020



There is a known tension between the need to analyze personal data to drive business and privacy concerns. Many data protection regulations, including the EU General Data Protection Regulation (GDPR) and the California Consumer Protection Act (CCPA), set out strict restrictions and obligations on companies that collect or process personal data. Moreover, machine learning models themselves can be used to derive personal information, as demonstrated by recent membership and attribute inference attacks. Anonymized data, however, is exempt from data protection principles and obligations. Thus, models built on anonymized data are also exempt from any privacy obligations, in addition to providing better protection against such attacks on the training data. Learning on anonymized data typically results in a significant degradation in accuracy. We address this challenge by guiding our anonymization using the knowledge encoded within the model, and targeting it to minimize the impact on the model's accuracy, a process we call accuracy-guided anonymization. We demonstrate that by focusing on the model's accuracy rather than information loss, our method outperforms state of the art k-anonymity methods in terms of the achieved utility, in particular with high values of k and large numbers of quasi-identifiers. We also demonstrate that our approach achieves similar results in its ability to prevent membership inference attacks as alternative approaches based on differential privacy. This shows that model-guided anonymization can, in some cases, be a legitimate substitute for such methods, while averting some of their inherent drawbacks such as complexity, performance overhead and being fitted to specific model types. As opposed to methods that rely on adding noise during training, our approach does not rely on making any modifications to the training algorithm itself.
Reducing Risk of Model Inversion Using Privacy-Guided Training
Jun 29, 2020
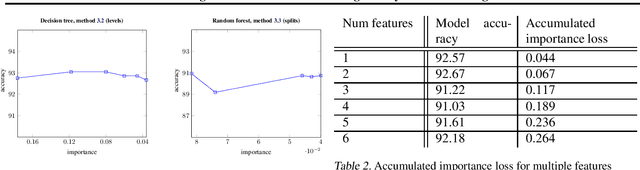
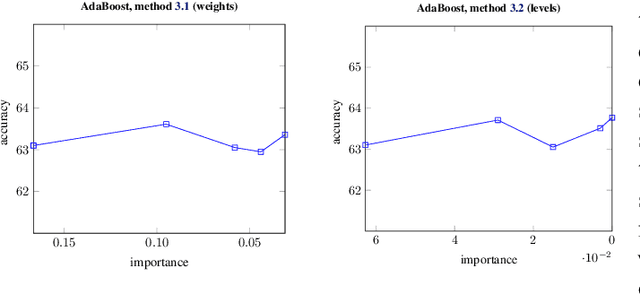
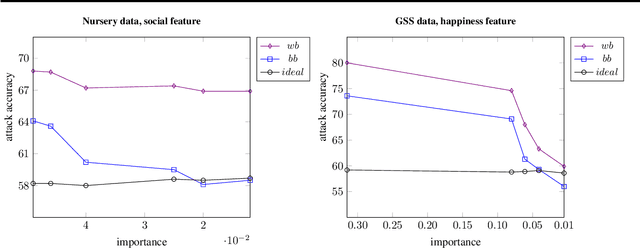
Machine learning models often pose a threat to the privacy of individuals whose data is part of the training set. Several recent attacks have been able to infer sensitive information from trained models, including model inversion or attribute inference attacks. These attacks are able to reveal the values of certain sensitive features of individuals who participated in training the model. It has also been shown that several factors can contribute to an increased risk of model inversion, including feature influence. We observe that not all features necessarily share the same level of privacy or sensitivity. In many cases, certain features used to train a model are considered especially sensitive and therefore propitious candidates for inversion. We present a solution for countering model inversion attacks in tree-based models, by reducing the influence of sensitive features in these models. This is an avenue that has not yet been thoroughly investigated, with only very nascent previous attempts at using this as a countermeasure against attribute inference. Our work shows that, in many cases, it is possible to train a model in different ways, resulting in different influence levels of the various features, without necessarily harming the model's accuracy. We are able to utilize this fact to train models in a manner that reduces the model's reliance on the most sensitive features, while increasing the importance of less sensitive features. Our evaluation confirms that training models in this manner reduces the risk of inference for those features, as demonstrated through several black-box and white-box attacks.