 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Minimization for GDPR Compliance in Machine Learning Models
Paper and Code

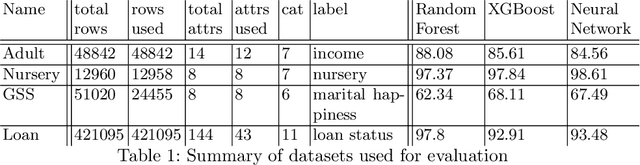

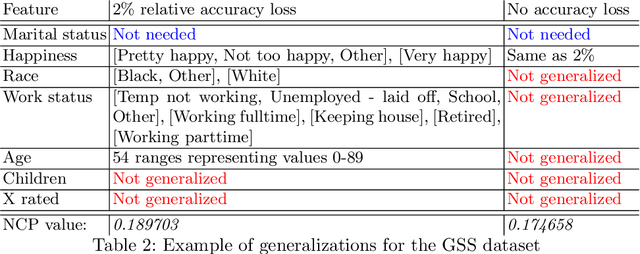
The EU General Data Protection Regulation (GDPR) mandates the principle of data minimization, which requires that only data necessary to fulfill a certain purpose be collected. However, it can often be difficult to determine the minimal amount of data required, especially in complex machine learning models such as neural networks. We present a first-of-a-kind method to reduce the amount of personal data needed to perform predictions with a machine learning model, by removing or generalizing some of the input features. Our method makes use of the knowledge encoded within the model to produce a generalization that has little to no impact on its accuracy. This enables the creators and users of machine learning models to acheive data minimization, in a provable manner.