 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating 2D and 3D Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Nov 28, 2022A master face is a face image that passes face-based identity authentication for a high percentage of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user information. We optimize these faces for 2D and 3D face verification models, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. For 2D face verification, multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network to direct the search toward promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a considerable coverage of the identities in the LFW or RFW datasets with less than 10 master faces, for six leading deep face recognition systems. In 3D, we generate faces using the 2D StyleGAN2 generator and predict a 3D structure using a deep 3D face reconstruction network. When employing two different 3D face recognition systems, we are able to obtain a coverage of 40%-50%. Additionally, we present the generation of paired 2D RGB and 3D master faces, which simultaneously match 2D and 3D models with high impersonation rates.
Generating Master Faces for Dictionary Attacks with a Network-Assisted Latent Space Evolution
Aug 19, 2021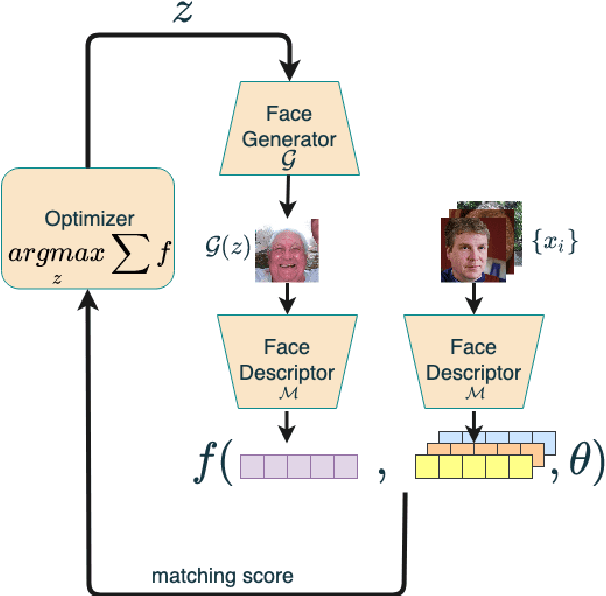
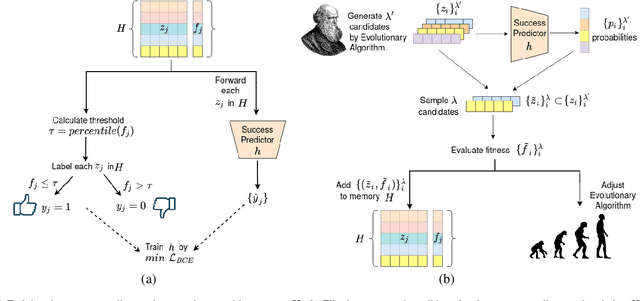


A master face is a face image that passes face-based identity-authentication for a large portion of the population. These faces can be used to impersonate, with a high probability of success, any user, without having access to any user-information. We optimize these faces, by using an evolutionary algorithm in the latent embedding space of the StyleGAN face generator. Multiple evolutionary strategies are compared, and we propose a novel approach that employs a neural network in order to direct the search in the direction of promising samples, without adding fitness evaluations. The results we present demonstrate that it is possible to obtain a high coverage of the LFW identities (over 40%) with less than 10 master faces, for three leading deep face recognition systems.
Data Minimization for GDPR Compliance in Machine Learning Models
Aug 06, 2020
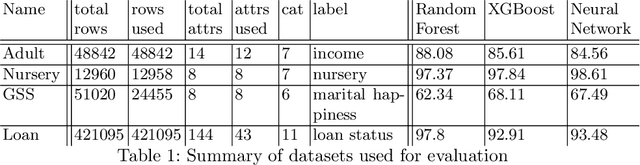

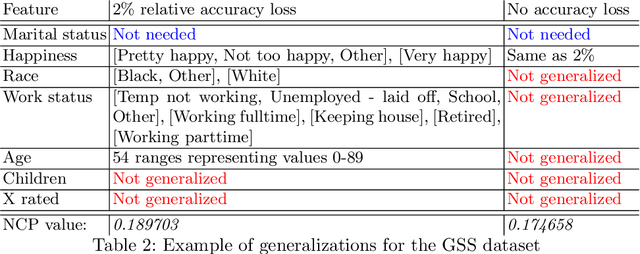
The EU General Data Protection Regulation (GDPR) mandates the principle of data minimization, which requires that only data necessary to fulfill a certain purpose be collected. However, it can often be difficult to determine the minimal amount of data required, especially in complex machine learning models such as neural networks. We present a first-of-a-kind method to reduce the amount of personal data needed to perform predictions with a machine learning model, by removing or generalizing some of the input features. Our method makes use of the knowledge encoded within the model to produce a generalization that has little to no impact on its accuracy. This enables the creators and users of machine learning models to acheive data minimization, in a provable manner.
Anonymizing Machine Learning Models
Jul 26, 2020



There is a known tension between the need to analyze personal data to drive business and privacy concerns. Many data protection regulations, including the EU General Data Protection Regulation (GDPR) and the California Consumer Protection Act (CCPA), set out strict restrictions and obligations on companies that collect or process personal data. Moreover, machine learning models themselves can be used to derive personal information, as demonstrated by recent membership and attribute inference attacks. Anonymized data, however, is exempt from data protection principles and obligations. Thus, models built on anonymized data are also exempt from any privacy obligations, in addition to providing better protection against such attacks on the training data. Learning on anonymized data typically results in a significant degradation in accuracy. We address this challenge by guiding our anonymization using the knowledge encoded within the model, and targeting it to minimize the impact on the model's accuracy, a process we call accuracy-guided anonymization. We demonstrate that by focusing on the model's accuracy rather than information loss, our method outperforms state of the art k-anonymity methods in terms of the achieved utility, in particular with high values of k and large numbers of quasi-identifiers. We also demonstrate that our approach achieves similar results in its ability to prevent membership inference attacks as alternative approaches based on differential privacy. This shows that model-guided anonymization can, in some cases, be a legitimate substitute for such methods, while averting some of their inherent drawbacks such as complexity, performance overhead and being fitted to specific model types. As opposed to methods that rely on adding noise during training, our approach does not rely on making any modifications to the training algorithm itself.