 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTsSHAP: Robust model agnostic feature-based explainability for time series forecasting
Mar 22, 2023


A trustworthy machine learning model should be accurate as well as explainable. Understanding why a model makes a certain decision defines the notion of explainability. While various flavors of explainability have been well-studied in supervised learning paradigms like classification and regression, literature on explainability for time series forecasting is relatively scarce. In this paper, we propose a feature-based explainability algorithm, TsSHAP, that can explain the forecast of any black-box forecasting model. The method is agnostic of the forecasting model and can provide explanations for a forecast in terms of interpretable features defined by the user a prior. The explanations are in terms of the SHAP values obtained by applying the TreeSHAP algorithm on a surrogate model that learns a mapping between the interpretable feature space and the forecast of the black-box model. Moreover, we formalize the notion of local, semi-local, and global explanations in the context of time series forecasting, which can be useful in several scenarios. We validate the efficacy and robustness of TsSHAP through extensive experiments on multiple datasets.
HE-PEx: Efficient Machine Learning under Homomorphic Encryption using Pruning, Permutation and Expansion
Jul 07, 2022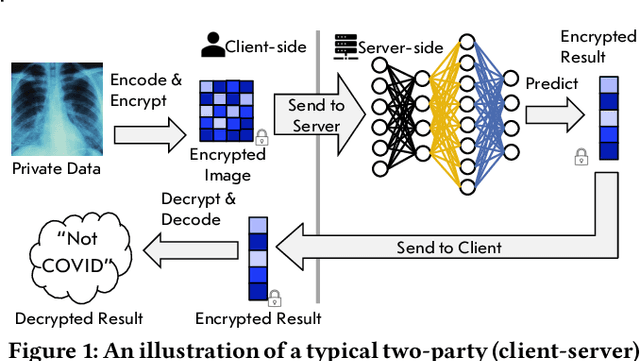

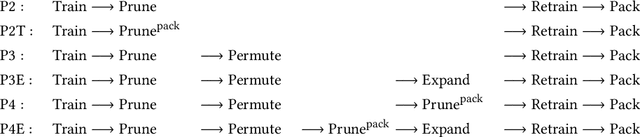
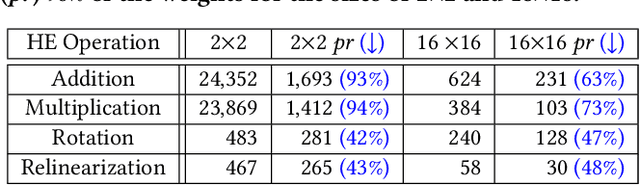
Privacy-preserving neural network (NN) inference solutions have recently gained significant traction with several solutions that provide different latency-bandwidth trade-offs. Of these, many rely on homomorphic encryption (HE), a method of performing computations over encrypted data. However, HE operations even with state-of-the-art schemes are still considerably slow compared to their plaintext counterparts. Pruning the parameters of a NN model is a well-known approach to improving inference latency. However, pruning methods that are useful in the plaintext context may lend nearly negligible improvement in the HE case, as has also been demonstrated in recent work. In this work, we propose a novel set of pruning methods that reduce the latency and memory requirement, thus bringing the effectiveness of plaintext pruning methods to HE. Crucially, our proposal employs two key techniques, viz. permutation and expansion of the packed model weights, that enable pruning significantly more ciphertexts and recuperating most of the accuracy loss, respectively. We demonstrate the advantage of our method on fully connected layers where the weights are packed using a recently proposed packing technique called tile tensors, which allows executing deep NN inference in a non-interactive mode. We evaluate our methods on various autoencoder architectures and demonstrate that for a small mean-square reconstruction loss of 1.5*10^{-5} on MNIST, we reduce the memory requirement and latency of HE-enabled inference by 60%.
Efficient Encrypted Inference on Ensembles of Decision Trees
Mar 05, 2021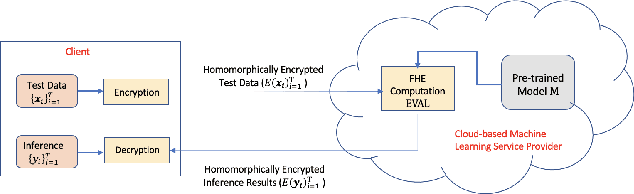

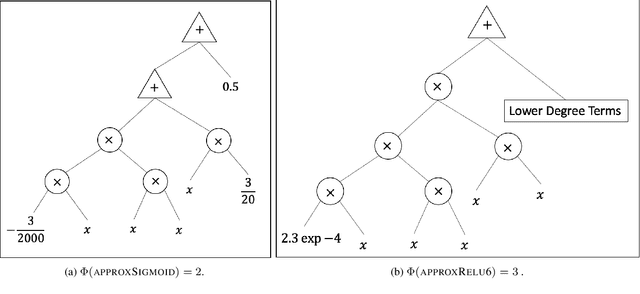
Data privacy concerns often prevent the use of cloud-based machine learning services for sensitive personal data. While homomorphic encryption (HE) offers a potential solution by enabling computations on encrypted data, the challenge is to obtain accurate machine learning models that work within the multiplicative depth constraints of a leveled HE scheme. Existing approaches for encrypted inference either make ad-hoc simplifications to a pre-trained model (e.g., replace hard comparisons in a decision tree with soft comparators) at the cost of accuracy or directly train a new depth-constrained model using the original training set. In this work, we propose a framework to transfer knowledge extracted by complex decision tree ensembles to shallow neural networks (referred to as DTNets) that are highly conducive to encrypted inference. Our approach minimizes the accuracy loss by searching for the best DTNet architecture that operates within the given depth constraints and training this DTNet using only synthetic data sampled from the training data distribution. Extensive experiments on real-world datasets demonstrate that these characteristics are critical in ensuring that DTNet accuracy approaches that of the original tree ensemble. Our system is highly scalable and can perform efficient inference on batched encrypted (134 bits of security) data with amortized time in milliseconds. This is approximately three orders of magnitude faster than the standard approach of applying soft comparison at the internal nodes of the ensemble trees.
Differentially Private Distributed Data Summarization under Covariate Shift
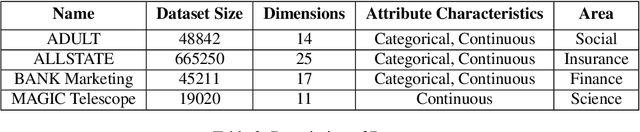
Oct 28, 2019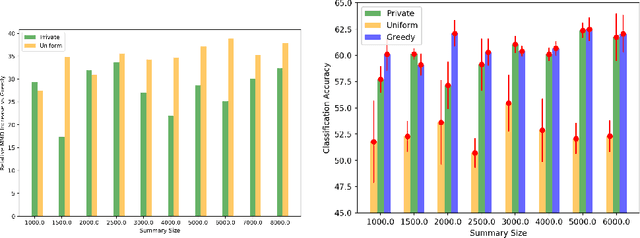
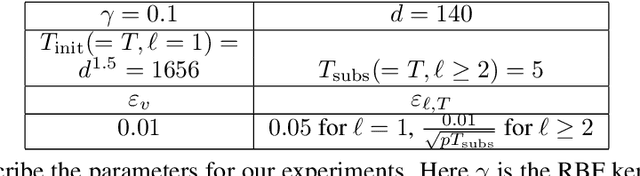
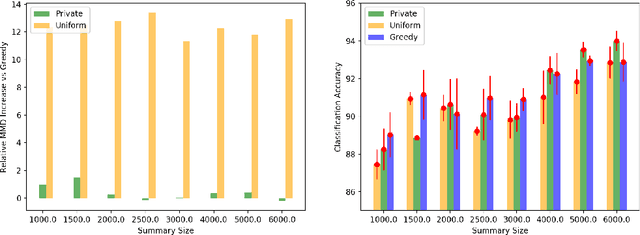
We envision AI marketplaces to be platforms where consumers, with very less data for a target task, can obtain a relevant model by accessing many private data sources with vast number of data samples. One of the key challenges is to construct a training dataset that matches a target task without compromising on privacy of the data sources. To this end, we consider the following distributed data summarizataion problem. Given K private source datasets denoted by $[D_i]_{i\in [K]}$ and a small target validation set $D_v$, which may involve a considerable covariate shift with respect to the sources, compute a summary dataset $D_s\subseteq \bigcup_{i\in [K]} D_i$ such that its statistical distance from the validation dataset $D_v$ is minimized. We use the popular Maximum Mean Discrepancy as the measure of statistical distance. The non-private problem has received considerable attention in prior art, for example in prototype selection (Kim et al., NIPS 2016). Our work is the first to obtain strong differential privacy guarantees while ensuring the quality guarantees of the non-private version. We study this problem in a Parsimonious Curator Privacy Model, where a trusted curator coordinates the summarization process while minimizing the amount of private information accessed. Our central result is a novel protocol that (a) ensures the curator accesses at most $O(K^{\frac{1}{3}}|D_s| + |D_v|)$ points (b) has formal privacy guarantees on the leakage of information between the data owners and (c) closely matches the best known non-private greedy algorithm. Our protocol uses two hash functions, one inspired by the Rahimi-Recht random features method and the second leverages state of the art differential privacy mechanisms. We introduce a novel "noiseless" differentially private auctioning protocol for winner notification and demonstrate the efficacy of our protocol using real-world datasets.