 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSPulse: Dual Space Tiny Pre-Trained Models for Rapid Time-Series Analysis
May 19, 2025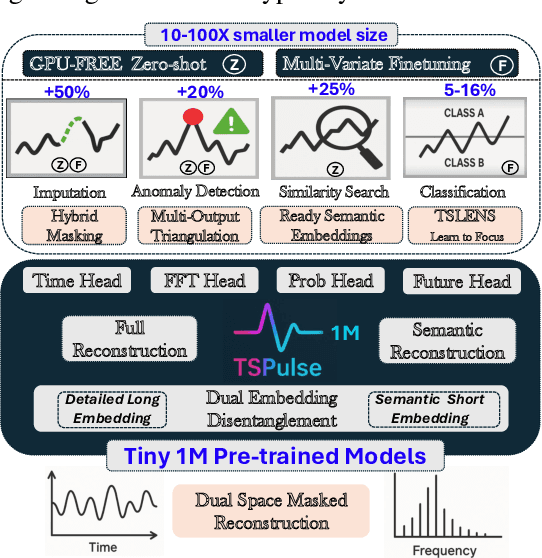

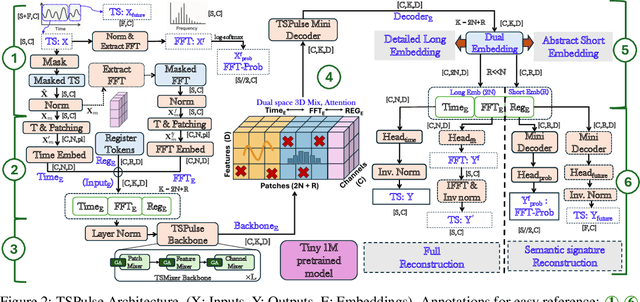

The rise of time-series pre-trained models has advanced temporal representation learning, but current state-of-the-art models are often large-scale, requiring substantial compute. We introduce TSPulse, ultra-compact time-series pre-trained models with only 1M parameters, specialized to perform strongly across classification, anomaly detection, imputation, and retrieval tasks. TSPulse introduces innovations at both the architecture and task levels. At the architecture level, it employs a dual-space masked reconstruction, learning from both time and frequency domains to capture complementary signals. This is further enhanced by a dual-embedding disentanglement, generating both detailed embeddings for fine-grained analysis and high-level semantic embeddings for broader task understanding. Notably, TSPulse's semantic embeddings are robust to shifts in time, magnitude, and noise, which is important for robust retrieval. At the task level, TSPulse incorporates TSLens, a fine-tuning component enabling task-specific feature attention. It also introduces a multi-head triangulation technique that correlates deviations from multiple prediction heads, enhancing anomaly detection by fusing complementary model outputs. Additionally, a hybrid mask pretraining is proposed to improves zero-shot imputation by reducing pre-training bias. These architecture and task innovations collectively contribute to TSPulse's significant performance gains: 5-16% on the UEA classification benchmarks, +20% on the TSB-AD anomaly detection leaderboard, +50% in zero-shot imputation, and +25% in time-series retrieval. Remarkably, these results are achieved with just 1M parameters, making TSPulse 10-100X smaller than existing pre-trained models. Its efficiency enables GPU-free inference and rapid pre-training, setting a new standard for efficient time-series pre-trained models. Models will be open-sourced soon.
TsSHAP: Robust model agnostic feature-based explainability for time series forecasting
Mar 22, 2023


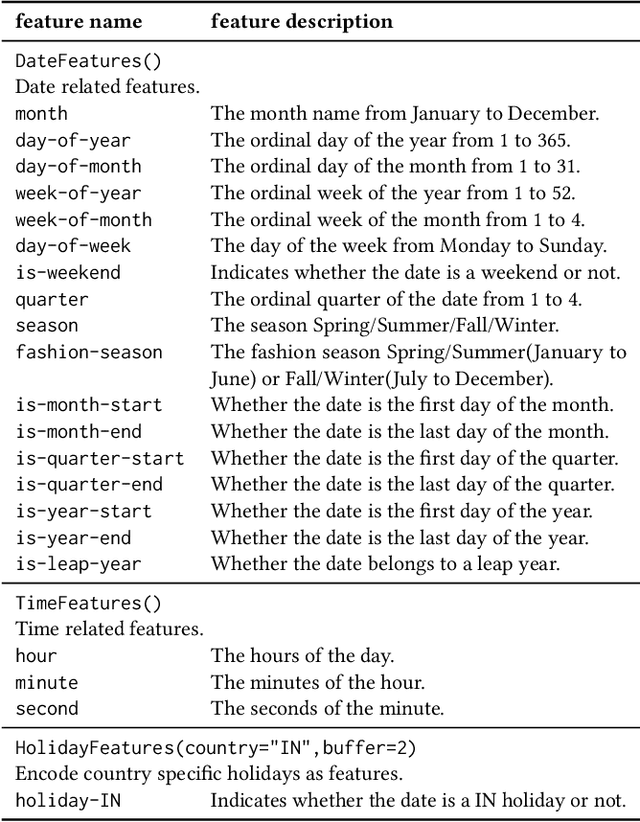
A trustworthy machine learning model should be accurate as well as explainable. Understanding why a model makes a certain decision defines the notion of explainability. While various flavors of explainability have been well-studied in supervised learning paradigms like classification and regression, literature on explainability for time series forecasting is relatively scarce. In this paper, we propose a feature-based explainability algorithm, TsSHAP, that can explain the forecast of any black-box forecasting model. The method is agnostic of the forecasting model and can provide explanations for a forecast in terms of interpretable features defined by the user a prior. The explanations are in terms of the SHAP values obtained by applying the TreeSHAP algorithm on a surrogate model that learns a mapping between the interpretable feature space and the forecast of the black-box model. Moreover, we formalize the notion of local, semi-local, and global explanations in the context of time series forecasting, which can be useful in several scenarios. We validate the efficacy and robustness of TsSHAP through extensive experiments on multiple datasets.
Semi-supervised counterfactual explanations
Mar 22, 2023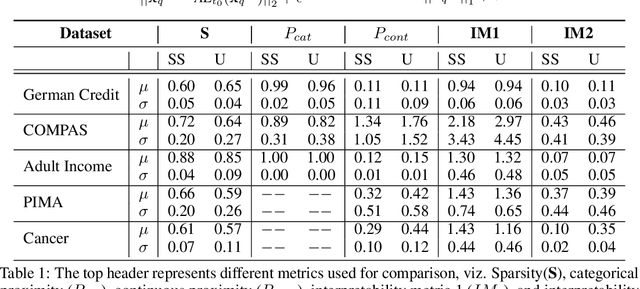
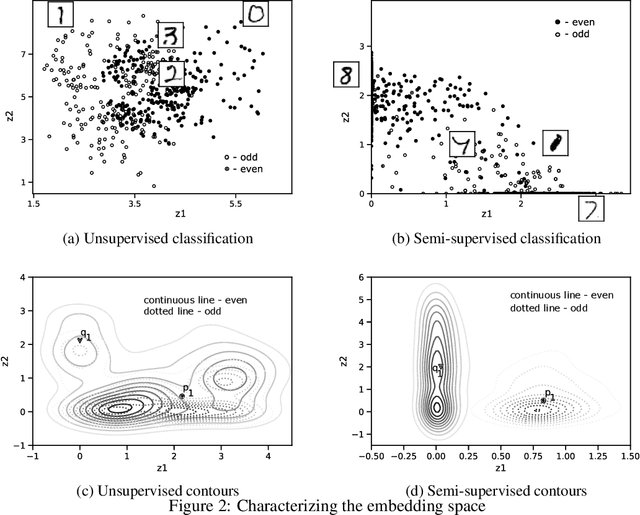

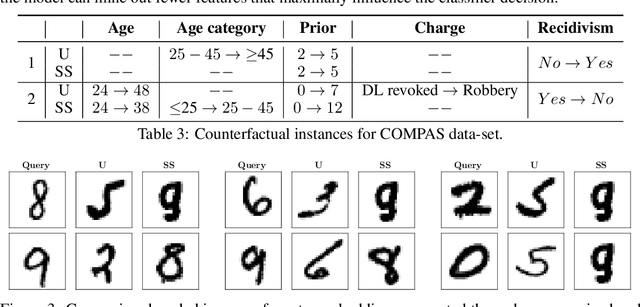
Counterfactual explanations for machine learning models are used to find minimal interventions to the feature values such that the model changes the prediction to a different output or a target output. A valid counterfactual explanation should have likely feature values. Here, we address the challenge of generating counterfactual explanations that lie in the same data distribution as that of the training data and more importantly, they belong to the target class distribution. This requirement has been addressed through the incorporation of auto-encoder reconstruction loss in the counterfactual search process. Connecting the output behavior of the classifier to the latent space of the auto-encoder has further improved the speed of the counterfactual search process and the interpretability of the resulting counterfactual explanations. Continuing this line of research, we show further improvement in the interpretability of counterfactual explanations when the auto-encoder is trained in a semi-supervised fashion with class tagged input data. We empirically evaluate our approach on several datasets and show considerable improvement in-terms of several metrics.
Hierarchy-guided Model Selection for Time Series Forecasting
Nov 28, 2022



Generalizability of time series forecasting models depends on the quality of model selection. Temporal cross validation (TCV) is a standard technique to perform model selection in forecasting tasks. TCV sequentially partitions the training time series into train and validation windows, and performs hyperparameter optmization (HPO) of the forecast model to select the model with the best validation performance. Model selection with TCV often leads to poor test performance when the test data distribution differs from that of the validation data. We propose a novel model selection method, H-Pro that exploits the data hierarchy often associated with a time series dataset. Generally, the aggregated data at the higher levels of the hierarchy show better predictability and more consistency compared to the bottom-level data which is more sparse and (sometimes) intermittent. H-Pro performs the HPO of the lowest-level student model based on the test proxy forecasts obtained from a set of teacher models at higher levels in the hierarchy. The consistency of the teachers' proxy forecasts help select better student models at the lowest-level. We perform extensive empirical studies on multiple datasets to validate the efficacy of the proposed method. H-Pro along with off-the-shelf forecasting models outperform existing state-of-the-art forecasting methods including the winning models of the M5 point-forecasting competition.
Semi-Supervised Method using Gaussian Random Fields for Boilerplate Removal in Web Browsers
Nov 08, 2019
Boilerplate removal refers to the problem of removing noisy content from a webpage such as ads and extracting relevant content that can be used by various services. This can be useful in several features in web browsers such as ad blocking, accessibility tools such as read out loud, translation, summarization etc. In order to create a training dataset to train a model for boilerplate detection and removal, labeling or tagging webpage data manually can be tedious and time consuming. Hence, a semi-supervised model, in which some of the webpage elements are labeled manually and labels for others are inferred based on some parameters, can be useful. In this paper we present a solution for extraction of relevant content from a webpage that relies on semi-supervised learning using Gaussian Random Fields. We first represent the webpage as a graph, with text elements as nodes and the edge weights representing similarity between nodes. After this, we label a few nodes in the graph using heuristics and label the remaining nodes by a weighted measure of similarity to the already labeled nodes. We describe the system architecture and a few preliminary results on a dataset of webpages.