 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE: Comprehensive Ontological Relation Evaluation for Large Language Models
Feb 06, 2026Large Language Models (LLMs) perform well on many reasoning benchmarks, yet existing evaluations rarely assess their ability to distinguish between meaningful semantic relations and genuine unrelatedness. We introduce CORE (Comprehensive Ontological Relation Evaluation), a dataset of 225K multiple-choice questions spanning 74 disciplines, together with a general-domain open-source benchmark of 203 rigorously validated questions (Cohen's Kappa = 1.0) covering 24 semantic relation types with equal representation of unrelated pairs. A human baseline from 1,000+ participants achieves 92.6% accuracy (95.1% on unrelated pairs). In contrast, 29 state-of-the-art LLMs achieve 48.25-70.9% overall accuracy, with near-ceiling performance on related pairs (86.5-100%) but severe degradation on unrelated pairs (0-41.35%), despite assigning similar confidence (92-94%). Expected Calibration Error increases 2-4x on unrelated pairs, and a mean semantic collapse rate of 37.6% indicates systematic generation of spurious relations. On the CORE 225K MCQs dataset, accuracy further drops to approximately 2%, highlighting substantial challenges in domain-specific semantic reasoning. We identify unrelatedness reasoning as a critical, under-evaluated frontier for LLM evaluation and safety.
Vehicular Wireless Positioning -- A Survey
Jan 28, 2026The rapid advancement of connected and autonomous vehicles has driven a growing demand for precise and reliable positioning systems capable of operating in complex environments. Meeting these demands requires an integrated approach that combines multiple positioning technologies, including wireless-based systems, perception-based technologies, and motion-based sensors. This paper presents a comprehensive survey of wireless-based positioning for vehicular applications, with a focus on satellite-based positioning (such as global navigation satellite systems (GNSS) and low-Earth-orbit (LEO) satellites), cellular-based positioning (5G and beyond), and IEEE-based technologies (including Wi-Fi, ultrawideband (UWB), Bluetooth, and vehicle-to-vehicle (V2V) communications). First, the survey reviews a wide range of vehicular positioning use cases, outlining their specific performance requirements. Next, it explores the historical development, standardization, and evolution of each wireless positioning technology, providing an in-depth categorization of existing positioning solutions and algorithms, and identifying open challenges and contemporary trends. Finally, the paper examines sensor fusion techniques that integrate these wireless systems with onboard perception and motion sensors to enhance positioning accuracy and resilience in real-world conditions. This survey thus offers a holistic perspective on the historical foundations, current advancements, and future directions of wireless-based positioning for vehicular applications, addressing a critical gap in the literature.
Indoor Sensing with Measurements
Sep 01, 2024



The cellular wireless networks are evolving towards acquiring newer capabilities, such as sensing, which will support novel use cases and applications. Many of these require indoor sensing capabilities, which can be realized by exploiting the perturbation in the indoor channel. In this work, we conduct an indoor channel measurement campaign to study these perturbations and develop AI-based algorithms for estimating sensing parameters. We develop several AI methods based on CNN and tree-based ensemble architectures for sensing. We show that the presence of a passive target like a person can be detected from the channel perturbation of a single link with more than 90 % accuracy with a simple CNN based AI algorithm. However, sensing the position of a passive target is far more challenging requiring more complex AI algorithms and deployments. We show that the position of the human in the indoor room can be estimated within the average position error of 0.7 m with a deployment having three links and employing complex AI architecture for position estimation. We also compare the results with the baseline algorithm to demonstrate the utility of the proposed method.
Semi-supervised counterfactual explanations
Mar 22, 2023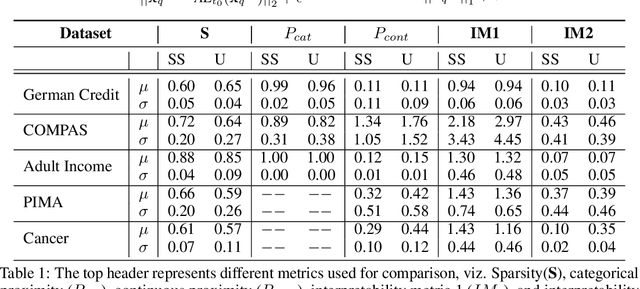
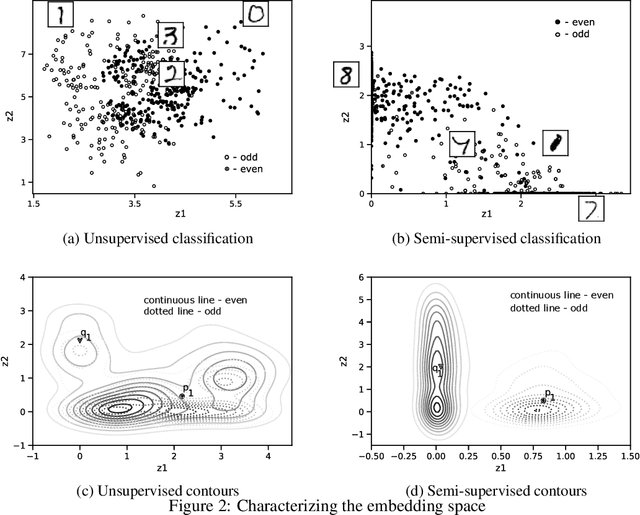

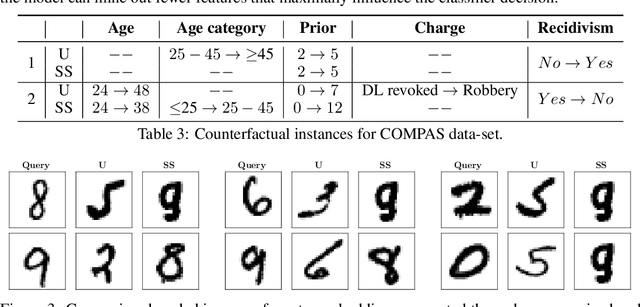
Counterfactual explanations for machine learning models are used to find minimal interventions to the feature values such that the model changes the prediction to a different output or a target output. A valid counterfactual explanation should have likely feature values. Here, we address the challenge of generating counterfactual explanations that lie in the same data distribution as that of the training data and more importantly, they belong to the target class distribution. This requirement has been addressed through the incorporation of auto-encoder reconstruction loss in the counterfactual search process. Connecting the output behavior of the classifier to the latent space of the auto-encoder has further improved the speed of the counterfactual search process and the interpretability of the resulting counterfactual explanations. Continuing this line of research, we show further improvement in the interpretability of counterfactual explanations when the auto-encoder is trained in a semi-supervised fashion with class tagged input data. We empirically evaluate our approach on several datasets and show considerable improvement in-terms of several metrics.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022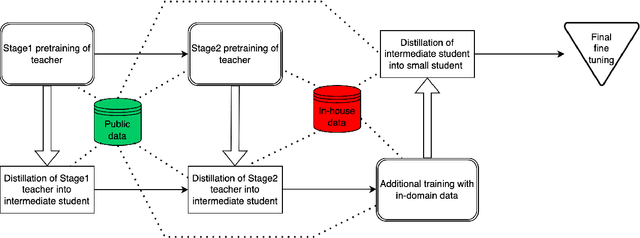
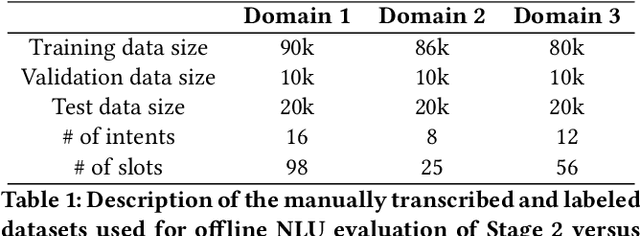
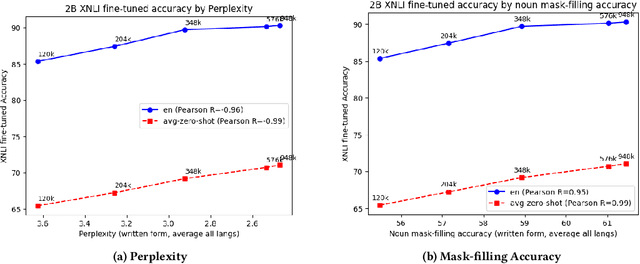
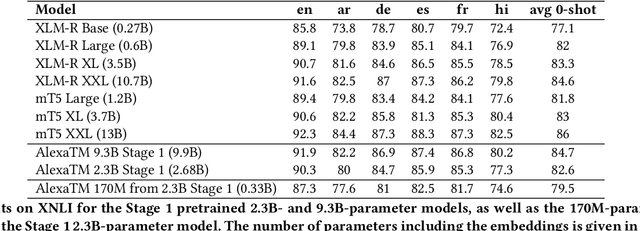
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Semi-Passive 3D Positioning of Multiple RIS-Enabled Users
Apr 25, 2021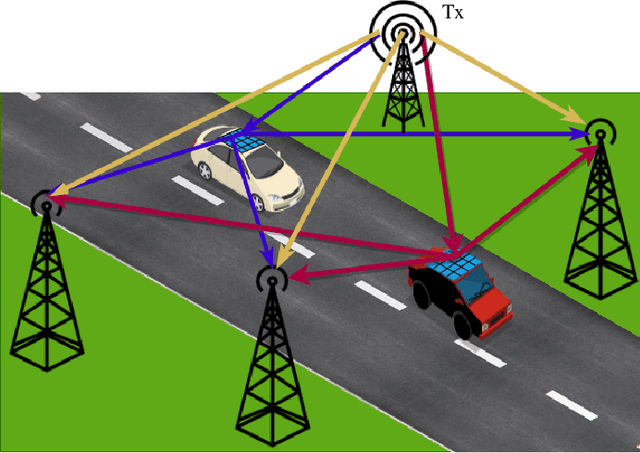
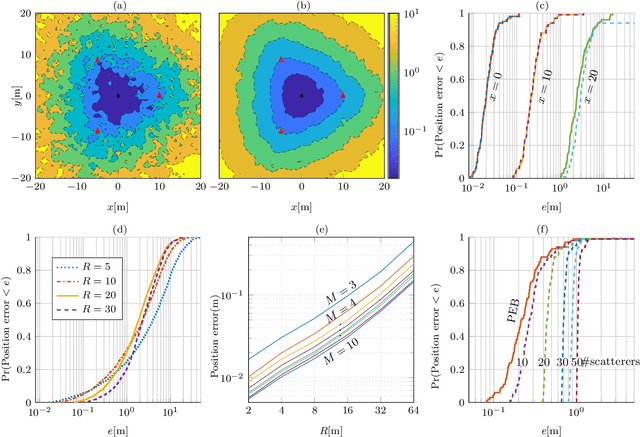
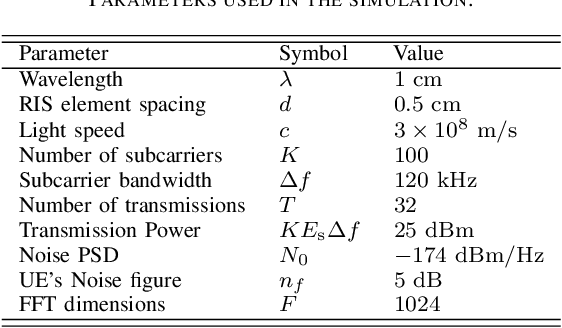
Reconfigurable intelligent surfaces (RISs) are set to be a revolutionary technology in the 6th generation of wireless systems. In this work, we study the application of RIS in a multi-user passive localization scenario, where we have one transmitter (Tx) and multiple asynchronous receivers (Rxs) with known locations. We aim to estimate the locations of multiple users equipped with RISs. The RISs only reflect the signal from the Tx to the Rxs and are not used as active transceivers themselves. Each Rx receives the signal from the Tx (LOS path) and the reflected signal from the RISs (NLOS path). We show that users' 3D position can be estimated with submeter accuracy in a large area around the transmitter, using the LOS and NLOS time-of-arrival measurements at the Rxs. We do so, by developing the signal model, deriving the Cramer-Rao bounds, and devising an estimator that attains these bounds. Furthermore, by orthogonalizing the RIS phase profiles across different users, we circumvent inter-path interference.