 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
Hierarchical Autoscaling for Large Language Model Serving with Chiron
Jan 14, 2025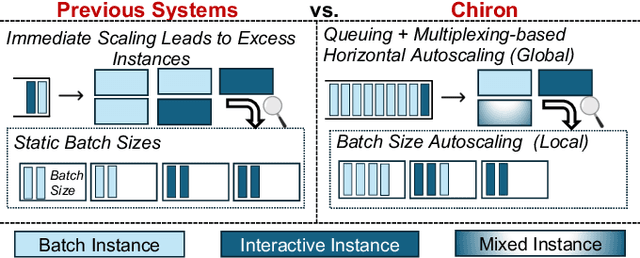
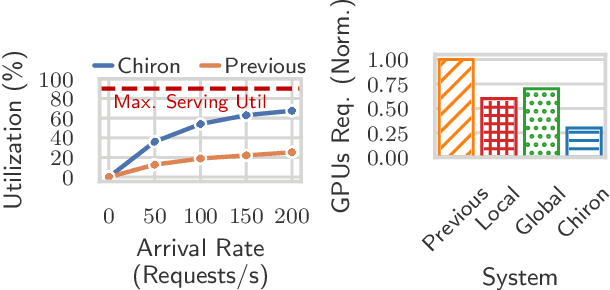
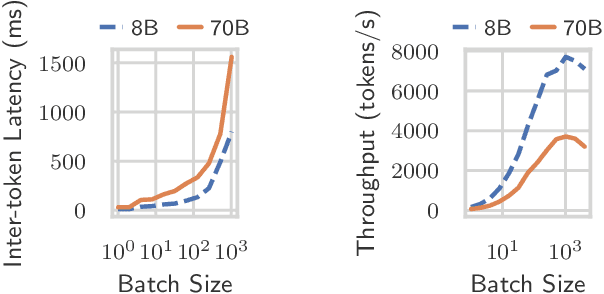

Large language model (LLM) serving is becoming an increasingly important workload for cloud providers. Based on performance SLO requirements, LLM inference requests can be divided into (a) interactive requests that have tight SLOs in the order of seconds, and (b) batch requests that have relaxed SLO in the order of minutes to hours. These SLOs can degrade based on the arrival rates, multiplexing, and configuration parameters, thus necessitating the use of resource autoscaling on serving instances and their batch sizes. However, previous autoscalers for LLM serving do not consider request SLOs leading to unnecessary scaling and resource under-utilization. To address these limitations, we introduce Chiron, an autoscaler that uses the idea of hierarchical backpressure estimated using queue size, utilization, and SLOs. Our experiments show that Chiron achieves up to 90% higher SLO attainment and improves GPU efficiency by up to 70% compared to existing solutions.
An Optimistic-Robust Approach for Dynamic Positioning of Omnichannel Inventories
Oct 17, 2023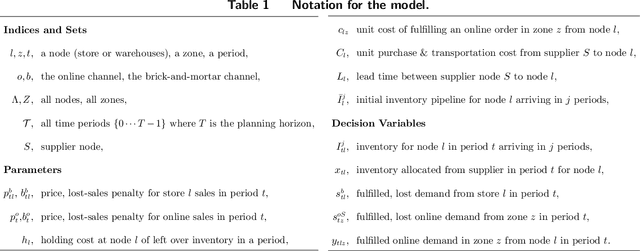
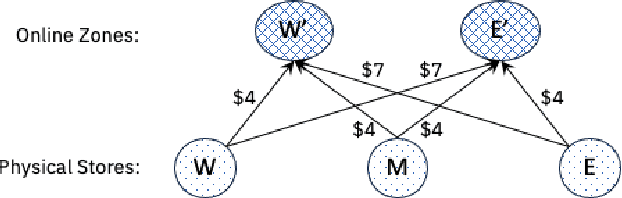
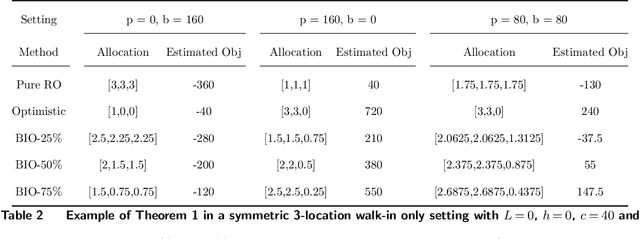
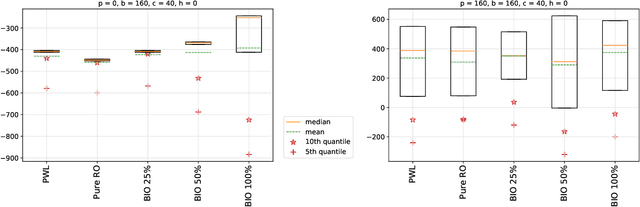
We introduce a new class of data-driven and distribution-free optimistic-robust bimodal inventory optimization (BIO) strategy to effectively allocate inventory across a retail chain to meet time-varying, uncertain omnichannel demand. While prior Robust optimization (RO) methods emphasize the downside, i.e., worst-case adversarial demand, BIO also considers the upside to remain resilient like RO while also reaping the rewards of improved average-case performance by overcoming the presence of endogenous outliers. This bimodal strategy is particularly valuable for balancing the tradeoff between lost sales at the store and the costs of cross-channel e-commerce fulfillment, which is at the core of our inventory optimization model. These factors are asymmetric due to the heterogenous behavior of the channels, with a bias towards the former in terms of lost-sales cost and a dependence on network effects for the latter. We provide structural insights about the BIO solution and how it can be tuned to achieve a preferred tradeoff between robustness and the average-case. Our experiments show that significant benefits can be achieved by rethinking traditional approaches to inventory management, which are siloed by channel and location. Using a real-world dataset from a large American omnichannel retail chain, a business value assessment during a peak period indicates over a 15% profitability gain for BIO over RO and other baselines while also preserving the (practical) worst case performance.
Hierarchy-guided Model Selection for Time Series Forecasting
Nov 28, 2022



Generalizability of time series forecasting models depends on the quality of model selection. Temporal cross validation (TCV) is a standard technique to perform model selection in forecasting tasks. TCV sequentially partitions the training time series into train and validation windows, and performs hyperparameter optmization (HPO) of the forecast model to select the model with the best validation performance. Model selection with TCV often leads to poor test performance when the test data distribution differs from that of the validation data. We propose a novel model selection method, H-Pro that exploits the data hierarchy often associated with a time series dataset. Generally, the aggregated data at the higher levels of the hierarchy show better predictability and more consistency compared to the bottom-level data which is more sparse and (sometimes) intermittent. H-Pro performs the HPO of the lowest-level student model based on the test proxy forecasts obtained from a set of teacher models at higher levels in the hierarchy. The consistency of the teachers' proxy forecasts help select better student models at the lowest-level. We perform extensive empirical studies on multiple datasets to validate the efficacy of the proposed method. H-Pro along with off-the-shelf forecasting models outperform existing state-of-the-art forecasting methods including the winning models of the M5 point-forecasting competition.