 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
Hierarchical Autoscaling for Large Language Model Serving with Chiron
Jan 14, 2025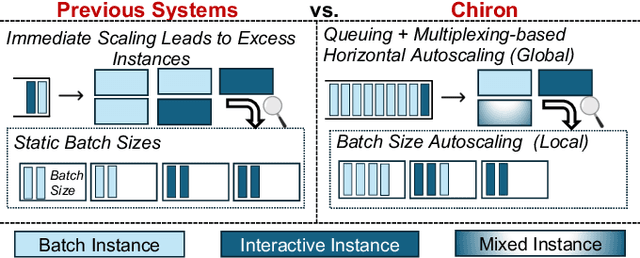
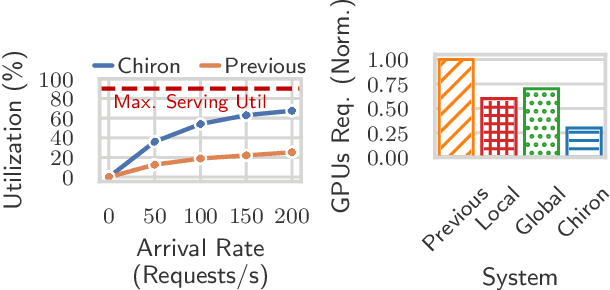
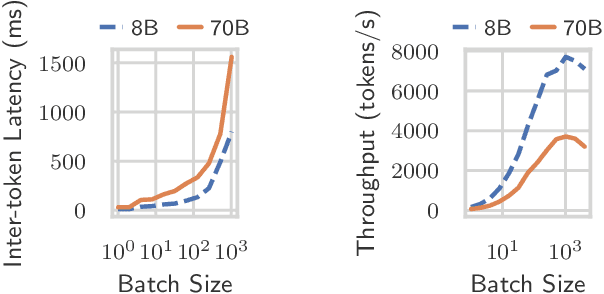

Large language model (LLM) serving is becoming an increasingly important workload for cloud providers. Based on performance SLO requirements, LLM inference requests can be divided into (a) interactive requests that have tight SLOs in the order of seconds, and (b) batch requests that have relaxed SLO in the order of minutes to hours. These SLOs can degrade based on the arrival rates, multiplexing, and configuration parameters, thus necessitating the use of resource autoscaling on serving instances and their batch sizes. However, previous autoscalers for LLM serving do not consider request SLOs leading to unnecessary scaling and resource under-utilization. To address these limitations, we introduce Chiron, an autoscaler that uses the idea of hierarchical backpressure estimated using queue size, utilization, and SLOs. Our experiments show that Chiron achieves up to 90% higher SLO attainment and improves GPU efficiency by up to 70% compared to existing solutions.
Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction
Apr 12, 2024Large language models (LLMs) have been driving a new wave of interactive AI applications across numerous domains. However, efficiently serving LLM inference requests is challenging due to their unpredictable execution times originating from the autoregressive nature of generative models. Existing LLM serving systems exploit first-come-first-serve (FCFS) scheduling, suffering from head-of-line blocking issues. To address the non-deterministic nature of LLMs and enable efficient interactive LLM serving, we present a speculative shortest-job-first (SSJF) scheduler that uses a light proxy model to predict LLM output sequence lengths. Our open-source SSJF implementation does not require changes to memory management or batching strategies. Evaluations on real-world datasets and production workload traces show that SSJF reduces average job completion times by 30.5-39.6% and increases throughput by 2.2-3.6x compared to FCFS schedulers, across no batching, dynamic batching, and continuous batching settings.