 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Language Models to Critique via Reinforcement Learning
Feb 05, 2025



Teaching large language models (LLMs) to critique and refine their outputs is crucial for building systems that can iteratively improve, yet it is fundamentally limited by the ability to provide accurate judgments and actionable suggestions. In this work, we study LLM critics for code generation and propose $\texttt{CTRL}$, a framework for $\texttt{C}$ritic $\texttt{T}$raining via $\texttt{R}$einforcement $\texttt{L}$earning, which trains a critic model to generate feedback that maximizes correction performance for a fixed generator model without human supervision. Our results demonstrate that critics trained with $\texttt{CTRL}$ significantly enhance pass rates and mitigate compounding errors across both base and stronger generator models. Furthermore, we show that these critic models act as accurate generative reward models and enable test-time scaling through iterative critique-revision, achieving up to 106.1% relative improvements across challenging code generation benchmarks.
Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction
Apr 12, 2024Large language models (LLMs) have been driving a new wave of interactive AI applications across numerous domains. However, efficiently serving LLM inference requests is challenging due to their unpredictable execution times originating from the autoregressive nature of generative models. Existing LLM serving systems exploit first-come-first-serve (FCFS) scheduling, suffering from head-of-line blocking issues. To address the non-deterministic nature of LLMs and enable efficient interactive LLM serving, we present a speculative shortest-job-first (SSJF) scheduler that uses a light proxy model to predict LLM output sequence lengths. Our open-source SSJF implementation does not require changes to memory management or batching strategies. Evaluations on real-world datasets and production workload traces show that SSJF reduces average job completion times by 30.5-39.6% and increases throughput by 2.2-3.6x compared to FCFS schedulers, across no batching, dynamic batching, and continuous batching settings.
Decision Transformer as a Foundation Model for Partially Observable Continuous Control
Apr 03, 2024



Closed-loop control of nonlinear dynamical systems with partial-state observability demands expert knowledge of a diverse, less standardized set of theoretical tools. Moreover, it requires a delicate integration of controller and estimator designs to achieve the desired system behavior. To establish a general controller synthesis framework, we explore the Decision Transformer (DT) architecture. Specifically, we first frame the control task as predicting the current optimal action based on past observations, actions, and rewards, eliminating the need for a separate estimator design. Then, we leverage the pre-trained language models, i.e., the Generative Pre-trained Transformer (GPT) series, to initialize DT and subsequently train it for control tasks using low-rank adaptation (LoRA). Our comprehensive experiments across five distinct control tasks, ranging from maneuvering aerospace systems to controlling partial differential equations (PDEs), demonstrate DT's capability to capture the parameter-agnostic structures intrinsic to control tasks. DT exhibits remarkable zero-shot generalization abilities for completely new tasks and rapidly surpasses expert performance levels with a minimal amount of demonstration data. These findings highlight the potential of DT as a foundational controller for general control applications.
Controlgym: Large-Scale Safety-Critical Control Environments for Benchmarking Reinforcement Learning Algorithms
Nov 30, 2023



We introduce controlgym, a library of thirty-six safety-critical industrial control settings, and ten infinite-dimensional partial differential equation (PDE)-based control problems. Integrated within the OpenAI Gym/Gymnasium (Gym) framework, controlgym allows direct applications of standard reinforcement learning (RL) algorithms like stable-baselines3. Our control environments complement those in Gym with continuous, unbounded action and observation spaces, motivated by real-world control applications. Moreover, the PDE control environments uniquely allow the users to extend the state dimensionality of the system to infinity while preserving the intrinsic dynamics. This feature is crucial for evaluating the scalability of RL algorithms for control. This project serves the learning for dynamics & control (L4DC) community, aiming to explore key questions: the convergence of RL algorithms in learning control policies; the stability and robustness issues of learning-based controllers; and the scalability of RL algorithms to high- and potentially infinite-dimensional systems. We open-source the controlgym project at https://github.com/xiangyuan-zhang/controlgym.
Provably Efficient Reinforcement Learning in Decentralized General-Sum Markov Games
Oct 21, 2021This paper addresses the problem of learning an equilibrium efficiently in general-sum Markov games through decentralized multi-agent reinforcement learning. Given the fundamental difficulty of calculating a Nash equilibrium (NE), we instead aim at finding a coarse correlated equilibrium (CCE), a solution concept that generalizes NE by allowing possible correlations among the agents' strategies. We propose an algorithm in which each agent independently runs optimistic V-learning (a variant of Q-learning) to efficiently explore the unknown environment, while using a stabilized online mirror descent (OMD) subroutine for policy updates. We show that the agents can find an $\epsilon$-approximate CCE in at most $\widetilde{O}( H^6S A /\epsilon^2)$ episodes, where $S$ is the number of states, $A$ is the size of the largest individual action space, and $H$ is the length of an episode. This appears to be the first sample complexity result for learning in generic general-sum Markov games. Our results rely on a novel investigation of an anytime high-probability regret bound for OMD with a dynamic learning rate and weighted regret, which would be of independent interest. One key feature of our algorithm is that it is fully \emph{decentralized}, in the sense that each agent has access to only its local information, and is completely oblivious to the presence of others. This way, our algorithm can readily scale up to an arbitrary number of agents, without suffering from the exponential dependence on the number of agents.
Decentralized Cooperative Multi-Agent Reinforcement Learning with Exploration
Oct 12, 2021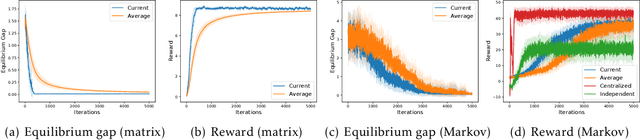

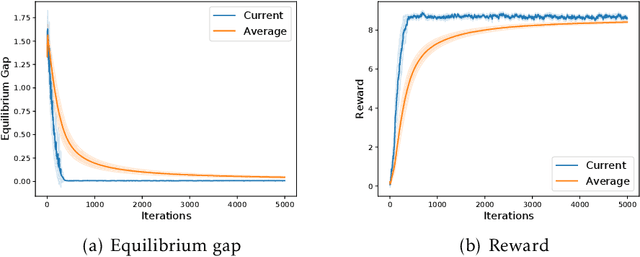
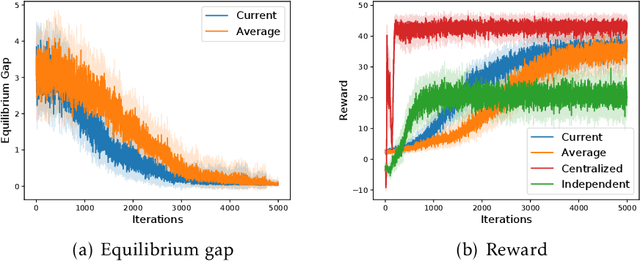
Many real-world applications of multi-agent reinforcement learning (RL), such as multi-robot navigation and decentralized control of cyber-physical systems, involve the cooperation of agents as a team with aligned objectives. We study multi-agent RL in the most basic cooperative setting -- Markov teams -- a class of Markov games where the cooperating agents share a common reward. We propose an algorithm in which each agent independently runs stage-based V-learning (a Q-learning style algorithm) to efficiently explore the unknown environment, while using a stochastic gradient descent (SGD) subroutine for policy updates. We show that the agents can learn an $\epsilon$-approximate Nash equilibrium policy in at most $\propto\widetilde{O}(1/\epsilon^4)$ episodes. Our results advocate the use of a novel \emph{stage-based} V-learning approach to create a stage-wise stationary environment. We also show that under certain smoothness assumptions of the team, our algorithm can achieve a nearly \emph{team-optimal} Nash equilibrium. Simulation results corroborate our theoretical findings. One key feature of our algorithm is being \emph{decentralized}, in the sense that each agent has access to only the state and its local actions, and is even \emph{oblivious} to the presence of the other agents. Neither communication among teammates nor coordination by a central controller is required during learning. Hence, our algorithm can readily generalize to an arbitrary number of agents, without suffering from the exponential dependence on the number of agents.
Near-Optimal Regret Bounds for Model-Free RL in Non-Stationary Episodic MDPs
Oct 07, 2020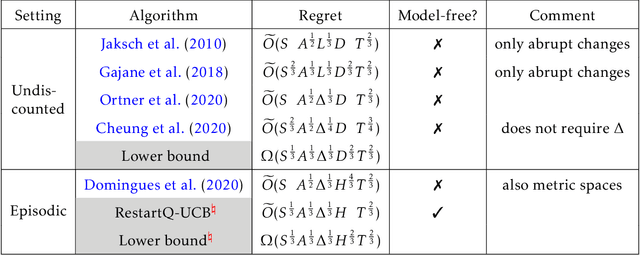
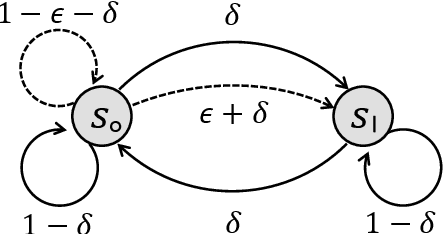
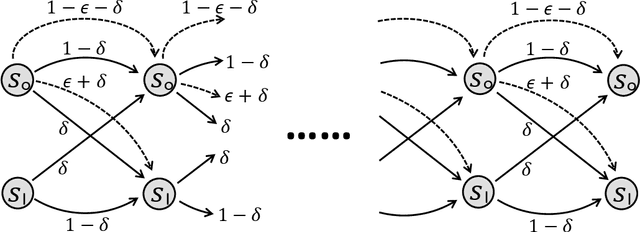
We consider model-free reinforcement learning (RL) in non-stationary Markov decision processes (MDPs). Both the reward functions and the state transition distributions are allowed to vary over time, either gradually or abruptly, as long as their cumulative variation magnitude does not exceed certain budgets. We propose an algorithm, named Restarted Q-Learning with Upper Confidence Bounds (RestartQ-UCB), for this setting, which adopts a simple restarting strategy and an extra optimism term. Our algorithm outperforms the state-of-the-art (model-based) solution in terms of dynamic regret. Specifically, RestartQ-UCB with Freedman-type bonus terms achieves a dynamic regret of $\widetilde{O}(S^{\frac{1}{3}} A^{\frac{1}{3}} \Delta^{\frac{1}{3}} H T^{\frac{2}{3}})$, where $S$ and $A$ are the numbers of states and actions, respectively, $\Delta>0$ is the variation budget, $H$ is the number of steps per episode, and $T$ is the total number of steps. We further show that our algorithm is near-optimal by establishing an information-theoretical lower bound of $\Omega(S^{\frac{1}{3}} A^{\frac{1}{3}} \Delta^{\frac{1}{3}} H^{\frac{2}{3}} T^{\frac{2}{3}})$, which to the best of our knowledge is the first impossibility result in non-stationary RL in general.
POLY-HOOT: Monte-Carlo Planning in Continuous Space MDPs with Non-Asymptotic Analysis
Jun 08, 2020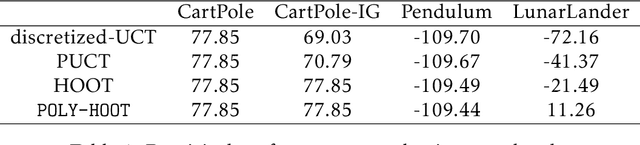
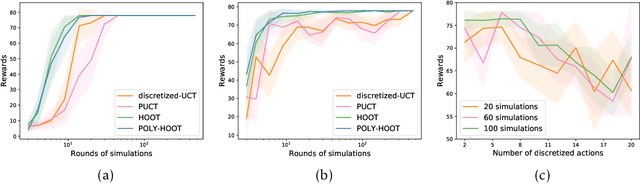
Monte-Carlo planning, as exemplified by Monte-Carlo Tree Search (MCTS), has demonstrated remarkable performance in applications with finite spaces. In this paper, we consider Monte-Carlo planning in an environment with continuous state-action spaces, a much less understood problem with important applications in control and robotics. We introduce POLY-HOOT, an algorithm that augments MCTS with a continuous armed bandit strategy named Hierarchical Optimistic Optimization (HOO) (Bubeck et al., 2011). Specifically, we enhance HOO by using an appropriate polynomial, rather than logarithmic, bonus term in the upper confidence bounds. Such a polynomial bonus is motivated by its empirical successes in AlphaGo Zero (Silver et al., 2017b), as well as its significant role in achieving theoretical guarantees of finite space MCTS (Shah et al., 2019). We investigate, for the first time, the regret of the enhanced HOO algorithm in non-stationary bandit problems. Using this result as a building block, we establish non-asymptotic convergence guarantees for POLY-HOOT: the value estimate converges to an arbitrarily small neighborhood of the optimal value function at a polynomial rate. We further provide experimental results that corroborate our theoretical findings.
Information State Embedding in Partially Observable Cooperative Multi-Agent Reinforcement Learning
Apr 18, 2020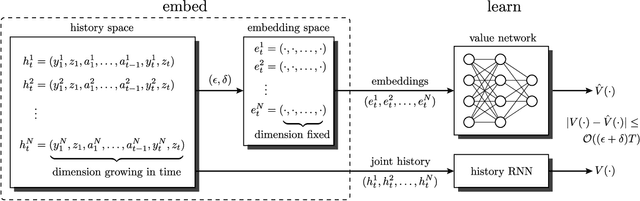
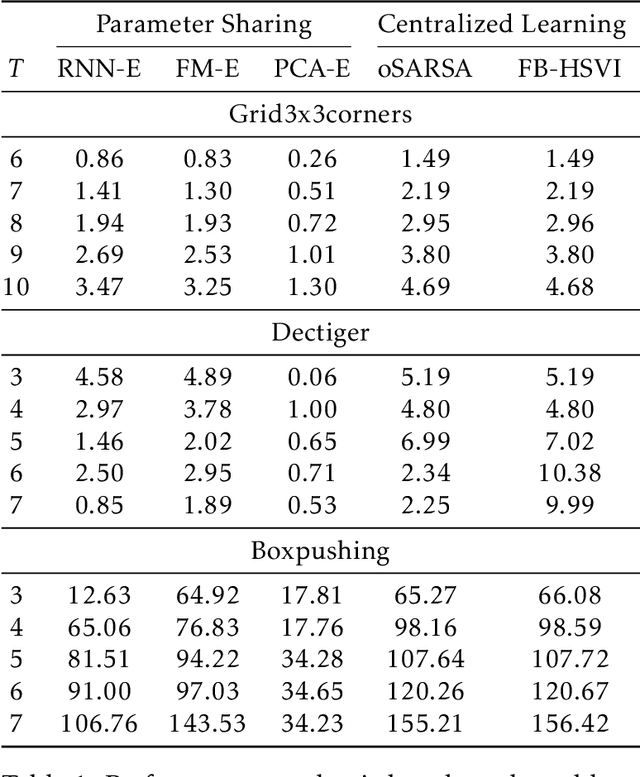
Multi-agent reinforcement learning (MARL) under partial observability has long been considered challenging, primarily due to the requirement for each agent to maintain a belief over all other agents' local histories -- a domain that generally grows exponentially over time. In this work, we investigate a partially observable MARL problem in which agents are cooperative. To enable the development of tractable algorithms, we introduce the concept of an information state embedding that serves to compress agents' histories. We quantify how the compression error influences the resulting value functions for decentralized control. Furthermore, we propose three natural embeddings, based on finite-memory truncation, principal component analysis, and recurrent neural networks. The output of these embeddings are then used as the information state, and can be fed into any MARL algorithm. The proposed embed-then-learn pipeline opens the black-box of existing MARL algorithms, allowing us to establish some theoretical guarantees (error bounds of value functions) while still achieving competitive performance with many end-to-end approaches.