 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Structured Graph Traversal for Root Cause Analysis of Code-related Incidents in Cloud Applications
Dec 26, 2025Cloud incidents pose major operational challenges in production, with unresolved production cloud incidents cost on average over $2M per hour. Prior research identifies code- and configuration-related issues as the predominant category of root causes in cloud incidents. This paper introduces PRAXIS, an orchestrator that manages and deploys an agentic workflow for diagnosing code- and configuration-caused cloud incidents. PRAXIS employs an LLM-driven structured traversal over two types of graph: (1) a service dependency graph (SDG) that captures microservice-level dependencies; and (2) a hammock-block program dependence graph (PDG) that captures code-level dependencies for each microservice. Together, these graphs encode microservice- and code-level dependencies and the LLM acts as a traversal policy over these graphs, moving between services and code dependencies to localize and explain failures. Compared to state-of-the-art ReAct baselines, PRAXIS improves RCA accuracy by up to 3.1x while reducing token consumption by 3.8x. PRAXIS is demonstrated on a set of 30 comprehensive real-world incidents that is being compiled into an RCA benchmark.
Characterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction
Apr 12, 2024Large language models (LLMs) have been driving a new wave of interactive AI applications across numerous domains. However, efficiently serving LLM inference requests is challenging due to their unpredictable execution times originating from the autoregressive nature of generative models. Existing LLM serving systems exploit first-come-first-serve (FCFS) scheduling, suffering from head-of-line blocking issues. To address the non-deterministic nature of LLMs and enable efficient interactive LLM serving, we present a speculative shortest-job-first (SSJF) scheduler that uses a light proxy model to predict LLM output sequence lengths. Our open-source SSJF implementation does not require changes to memory management or batching strategies. Evaluations on real-world datasets and production workload traces show that SSJF reduces average job completion times by 30.5-39.6% and increases throughput by 2.2-3.6x compared to FCFS schedulers, across no batching, dynamic batching, and continuous batching settings.
REMEDI: REinforcement learning-driven adaptive MEtabolism modeling of primary sclerosing cholangitis DIsease progression
Oct 02, 2023



Primary sclerosing cholangitis (PSC) is a rare disease wherein altered bile acid metabolism contributes to sustained liver injury. This paper introduces REMEDI, a framework that captures bile acid dynamics and the body's adaptive response during PSC progression that can assist in exploring treatments. REMEDI merges a differential equation (DE)-based mechanistic model that describes bile acid metabolism with reinforcement learning (RL) to emulate the body's adaptations to PSC continuously. An objective of adaptation is to maintain homeostasis by regulating enzymes involved in bile acid metabolism. These enzymes correspond to the parameters of the DEs. REMEDI leverages RL to approximate adaptations in PSC, treating homeostasis as a reward signal and the adjustment of the DE parameters as the corresponding actions. On real-world data, REMEDI generated bile acid dynamics and parameter adjustments consistent with published findings. Also, our results support discussions in the literature that early administration of drugs that suppress bile acid synthesis may be effective in PSC treatment.
RACR-MIL: Weakly Supervised Skin Cancer Grading using Rank-Aware Contextual Reasoning on Whole Slide Images
Aug 29, 2023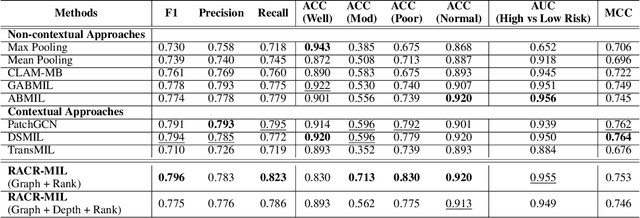
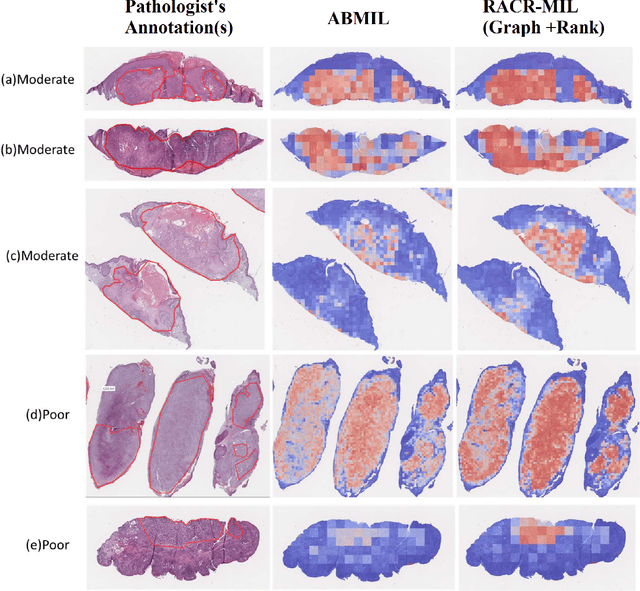
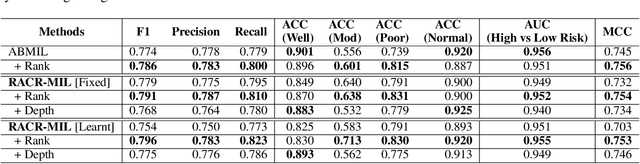
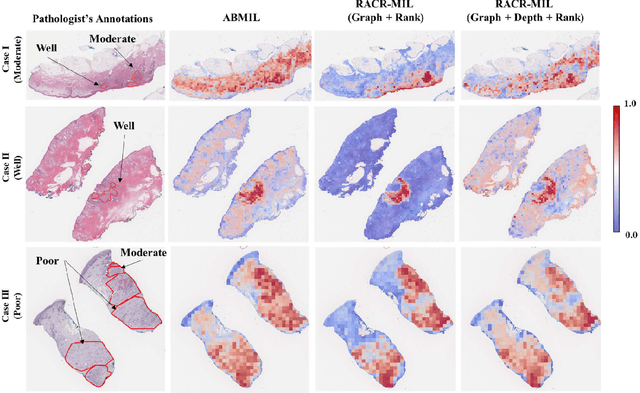
Cutaneous squamous cell cancer (cSCC) is the second most common skin cancer in the US. It is diagnosed by manual multi-class tumor grading using a tissue whole slide image (WSI), which is subjective and suffers from inter-pathologist variability. We propose an automated weakly-supervised grading approach for cSCC WSIs that is trained using WSI-level grade and does not require fine-grained tumor annotations. The proposed model, RACR-MIL, transforms each WSI into a bag of tiled patches and leverages attention-based multiple-instance learning to assign a WSI-level grade. We propose three key innovations to address general as well as cSCC-specific challenges in tumor grading. First, we leverage spatial and semantic proximity to define a WSI graph that encodes both local and non-local dependencies between tumor regions and leverage graph attention convolution to derive contextual patch features. Second, we introduce a novel ordinal ranking constraint on the patch attention network to ensure that higher-grade tumor regions are assigned higher attention. Third, we use tumor depth as an auxiliary task to improve grade classification in a multitask learning framework. RACR-MIL achieves 2-9% improvement in grade classification over existing weakly-supervised approaches on a dataset of 718 cSCC tissue images and localizes the tumor better. The model achieves 5-20% higher accuracy in difficult-to-classify high-risk grade classes and is robust to class imbalance.
Watch Out for the Safety-Threatening Actors: Proactively Mitigating Safety Hazards
Jun 02, 2022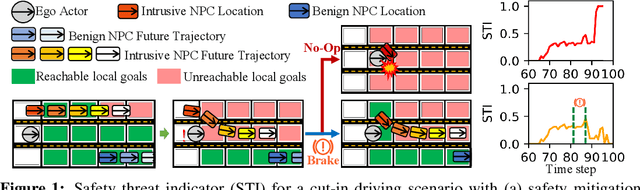

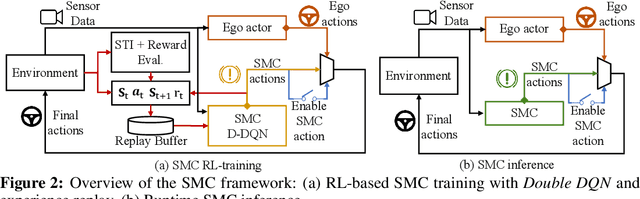
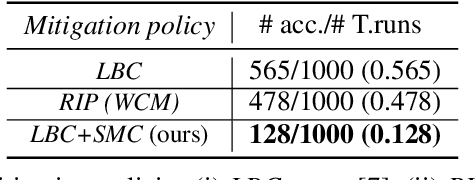
Despite the successful demonstration of autonomous vehicles (AVs), such as self-driving cars, ensuring AV safety remains a challenging task. Although some actors influence an AV's driving decisions more than others, current approaches pay equal attention to each actor on the road. An actor's influence on the AV's decision can be characterized in terms of its ability to decrease the number of safe navigational choices for the AV. In this work, we propose a safety threat indicator (STI) using counterfactual reasoning to estimate the importance of each actor on the road with respect to its influence on the AV's safety. We use this indicator to (i) characterize the existing real-world datasets to identify rare hazardous scenarios as well as the poor performance of existing controllers in such scenarios; and (ii) design an RL based safety mitigation controller to proactively mitigate the safety hazards those actors pose to the AV. Our approach reduces the accident rate for the state-of-the-art AV agent(s) in rare hazardous scenarios by more than 70%.
Watch out for the risky actors: Assessing risk in dynamic environments for safe driving
Oct 19, 2021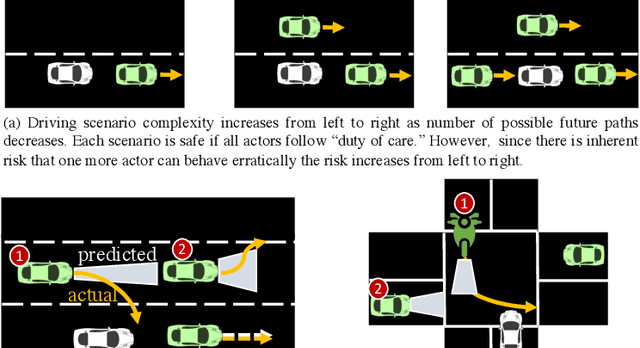
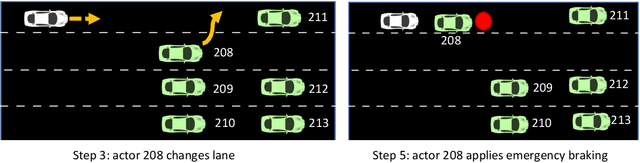
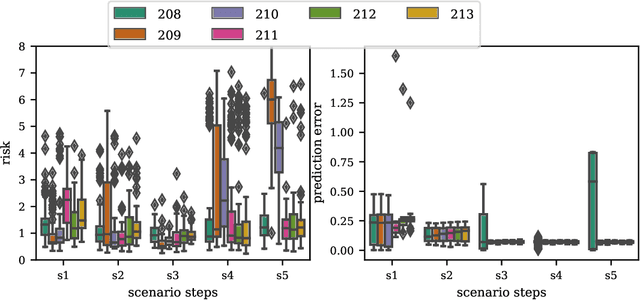
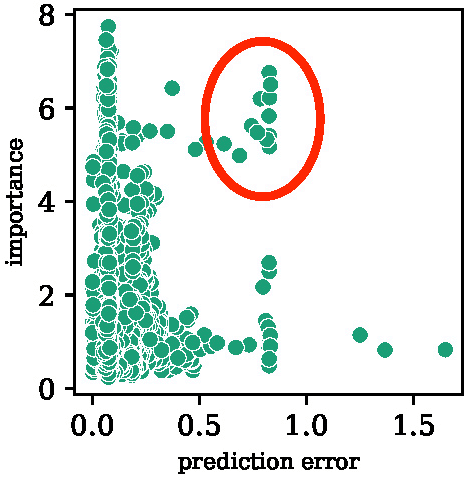
Driving in a dynamic environment that consists of other actors is inherently a risky task as each actor influences the driving decision and may significantly limit the number of choices in terms of navigation and safety plan. The risk encountered by the Ego actor depends on the driving scenario and the uncertainty associated with predicting the future trajectories of the other actors in the driving scenario. However, not all objects pose a similar risk. Depending on the object's type, trajectory, position, and the associated uncertainty with these quantities; some objects pose a much higher risk than others. The higher the risk associated with an actor, the more attention must be directed towards that actor in terms of resources and safety planning. In this paper, we propose a novel risk metric to calculate the importance of each actor in the world and demonstrate its usefulness through a case study.
Reinforcement Learning based Disease Progression Model for Alzheimer's Disease
Jun 30, 2021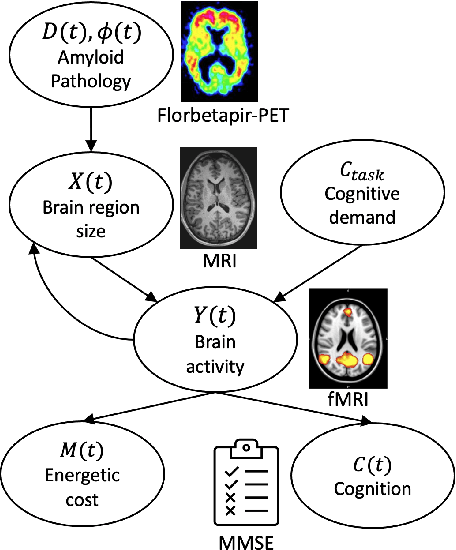
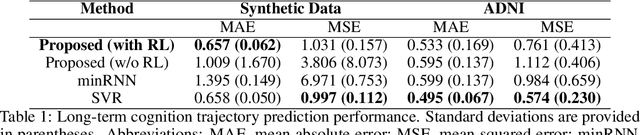
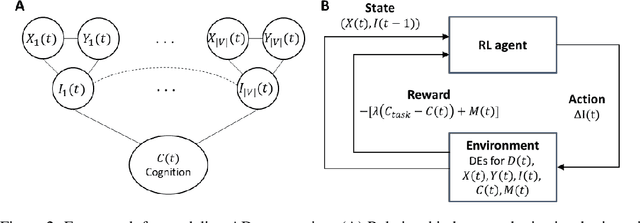
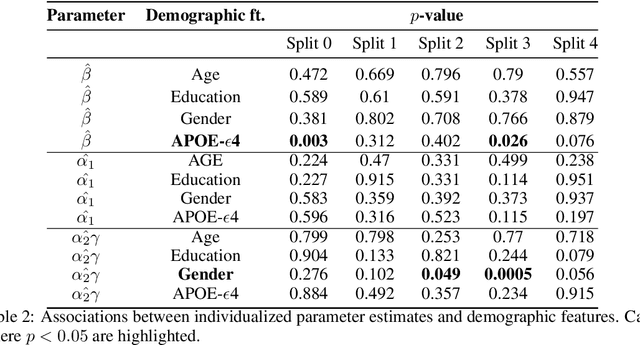
We model Alzheimer's disease (AD) progression by combining differential equations (DEs) and reinforcement learning (RL) with domain knowledge. DEs provide relationships between some, but not all, factors relevant to AD. We assume that the missing relationships must satisfy general criteria about the working of the brain, for e.g., maximizing cognition while minimizing the cost of supporting cognition. This allows us to extract the missing relationships by using RL to optimize an objective (reward) function that captures the above criteria. We use our model consisting of DEs (as a simulator) and the trained RL agent to predict individualized 10-year AD progression using baseline (year 0) features on synthetic and real data. The model was comparable or better at predicting 10-year cognition trajectories than state-of-the-art learning-based models. Our interpretable model demonstrated, and provided insights into, "recovery/compensatory" processes that mitigate the effect of AD, even though those processes were not explicitly encoded in the model. Our framework combines DEs with RL for modelling AD progression and has broad applicability for understanding other neurological disorders.
BayesPerf: Minimizing Performance Monitoring Errors Using Bayesian Statistics
Feb 22, 2021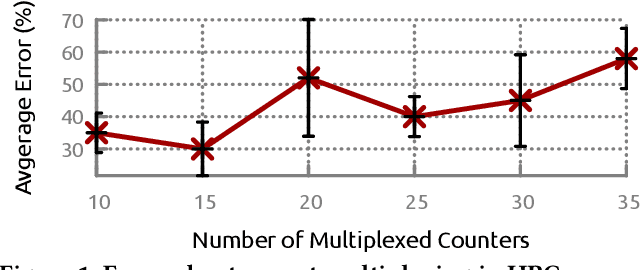
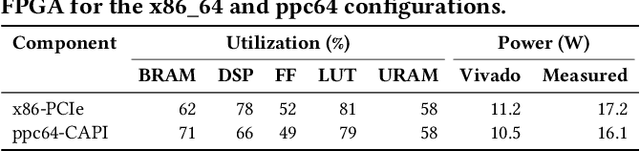
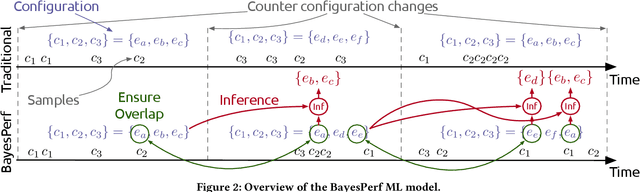
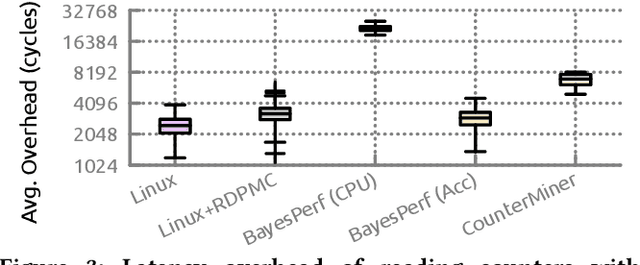
Hardware performance counters (HPCs) that measure low-level architectural and microarchitectural events provide dynamic contextual information about the state of the system. However, HPC measurements are error-prone due to non determinism (e.g., undercounting due to event multiplexing, or OS interrupt-handling behaviors). In this paper, we present BayesPerf, a system for quantifying uncertainty in HPC measurements by using a domain-driven Bayesian model that captures microarchitectural relationships between HPCs to jointly infer their values as probability distributions. We provide the design and implementation of an accelerator that allows for low-latency and low-power inference of the BayesPerf model for x86 and ppc64 CPUs. BayesPerf reduces the average error in HPC measurements from 40.1% to 7.6% when events are being multiplexed. The value of BayesPerf in real-time decision-making is illustrated with a simple example of scheduling of PCIe transfers.
Inductive Bias-driven Reinforcement Learning For Efficient Schedules in Heterogeneous Clusters
Sep 04, 2019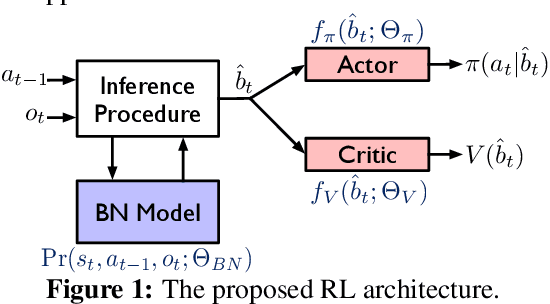
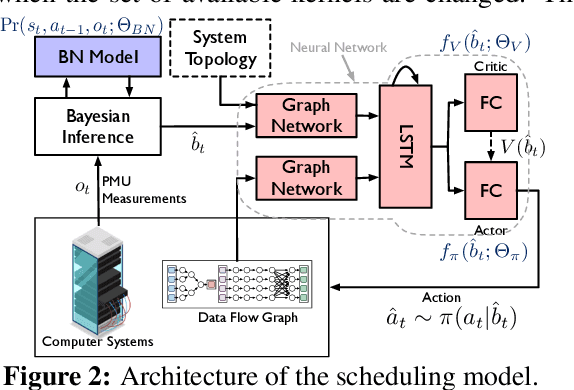
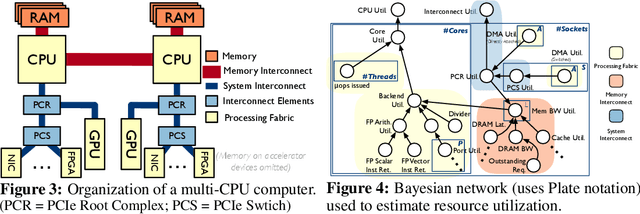
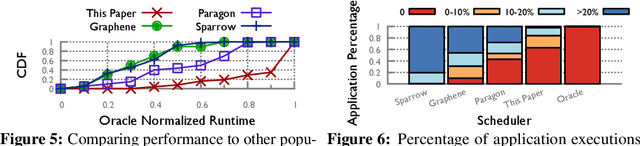
The problem of scheduling of workloads onto heterogeneous processors (e.g., CPUs, GPUs, FPGAs) is of fundamental importance in modern datacenters. Most current approaches rely on building application/system-specific heuristics that have to be reinvented on a case-by-case basis. This can be prohibitively expensive and is untenable going forward. In this paper, we propose a domain-driven reinforcement learning (RL) model for scheduling that can be broadly applied to a large class of heterogeneous processors. The key novelty of our approach is (i) the RL model; and (ii) the significant reduction of training-data (using domain knowledge) and -time (using sampling based end-to-end gradient propagation). We demonstrate the approach using real world GPU and FPGA accelerated applications to produce scheduling policies that significantly outperform hand-tuned heuristics.