 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring transfer learning for pathological speech feature prediction: Impact of layer selection
Feb 02, 2024There is interest in leveraging AI to conduct automatic, objective assessments of clinical speech, in turn facilitating diagnosis and treatment of speech disorders. We explore transfer learning, focusing on the impact of layer selection, for the downstream task of predicting the presence of pathological speech. We find that selecting an optimal layer offers large performance improvements (12.4% average increase in balanced accuracy), though the best layer varies by predicted feature and does not always generalize well to unseen data. A learned weighted sum offers comparable performance to the average best layer in-distribution and has better generalization for out-of-distribution data.
Detecting Speech Abnormalities with a Perceiver-based Sequence Classifier that Leverages a Universal Speech Model
Oct 16, 2023



We propose a Perceiver-based sequence classifier to detect abnormalities in speech reflective of several neurological disorders. We combine this classifier with a Universal Speech Model (USM) that is trained (unsupervised) on 12 million hours of diverse audio recordings. Our model compresses long sequences into a small set of class-specific latent representations and a factorized projection is used to predict different attributes of the disordered input speech. The benefit of our approach is that it allows us to model different regions of the input for different classes and is at the same time data efficient. We evaluated the proposed model extensively on a curated corpus from the Mayo Clinic. Our model outperforms standard transformer (80.9%) and perceiver (81.8%) models and achieves an average accuracy of 83.1%. With limited task-specific data, we find that pretraining is important and surprisingly pretraining with the unrelated automatic speech recognition (ASR) task is also beneficial. Encodings from the middle layers provide a mix of both acoustic and phonetic information and achieve best prediction results compared to just using the final layer encodings (83.1% vs. 79.6%). The results are promising and with further refinements may help clinicians detect speech abnormalities without needing access to highly specialized speech-language pathologists.
Risk of re-identification for shared clinical speech recordings
Oct 18, 2022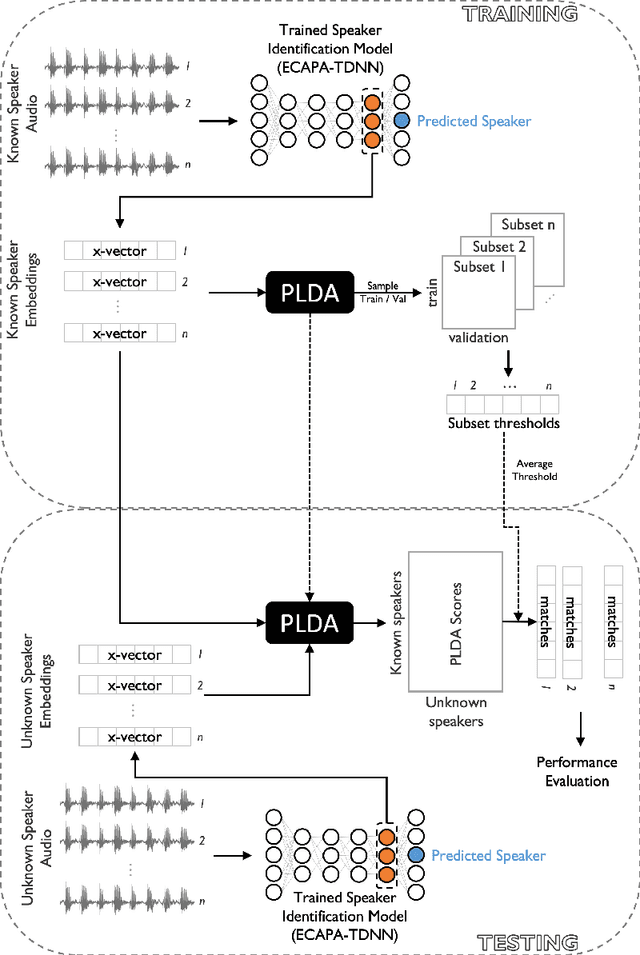
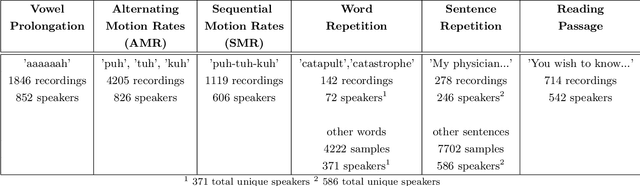
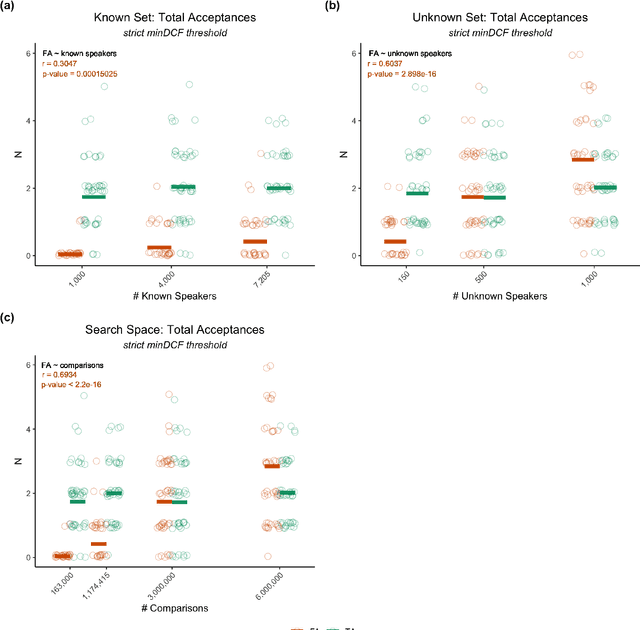
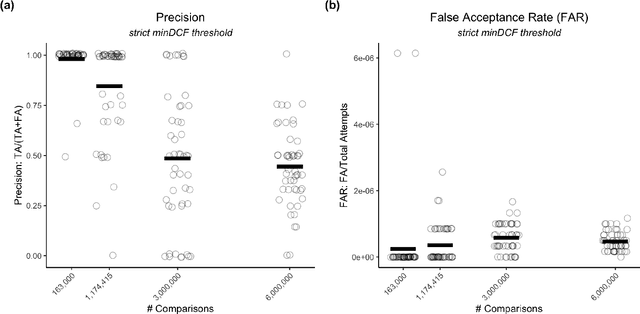
Large, curated datasets are required to leverage speech-based tools in healthcare. These are costly to produce, resulting in increased interest in data sharing. As speech can potentially identify speakers (i.e., voiceprints), sharing recordings raises privacy concerns. We examine the re-identification risk for speech recordings, without reference to demographic or metadata, using a state-of-the-art speaker recognition system. We demonstrate that the risk is inversely related to the number of comparisons an adversary must consider, i.e., the search space. Risk is high for a small search space but drops as the search space grows ($precision >0.85$ for $<1*10^{6}$ comparisons, $precision <0.5$ for $>3*10^{6}$ comparisons). Next, we show that the nature of a speech recording influences re-identification risk, with non-connected speech (e.g., vowel prolongation) being harder to identify. Our findings suggest that speaker recognition systems can be used to re-identify participants in specific circumstances, but in practice, the re-identification risk appears low.
Reinforcement Learning based Disease Progression Model for Alzheimer's Disease
Jun 30, 2021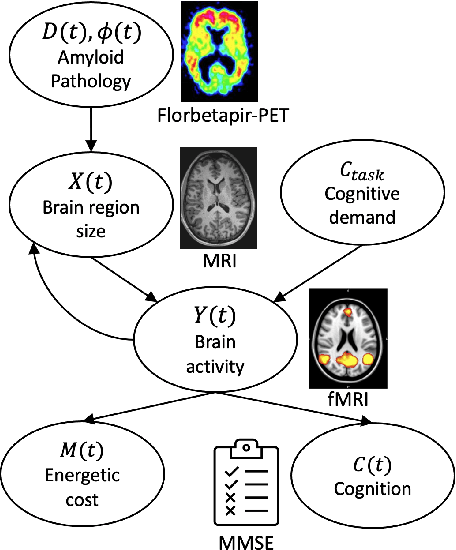
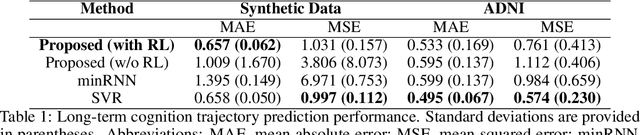
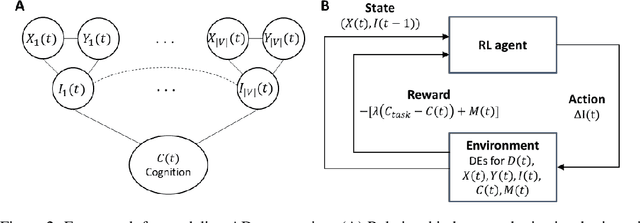
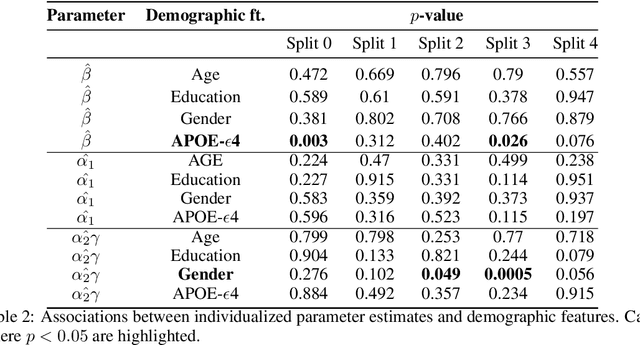
We model Alzheimer's disease (AD) progression by combining differential equations (DEs) and reinforcement learning (RL) with domain knowledge. DEs provide relationships between some, but not all, factors relevant to AD. We assume that the missing relationships must satisfy general criteria about the working of the brain, for e.g., maximizing cognition while minimizing the cost of supporting cognition. This allows us to extract the missing relationships by using RL to optimize an objective (reward) function that captures the above criteria. We use our model consisting of DEs (as a simulator) and the trained RL agent to predict individualized 10-year AD progression using baseline (year 0) features on synthetic and real data. The model was comparable or better at predicting 10-year cognition trajectories than state-of-the-art learning-based models. Our interpretable model demonstrated, and provided insights into, "recovery/compensatory" processes that mitigate the effect of AD, even though those processes were not explicitly encoded in the model. Our framework combines DEs with RL for modelling AD progression and has broad applicability for understanding other neurological disorders.