 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk of re-identification for shared clinical speech recordings
Paper and Code
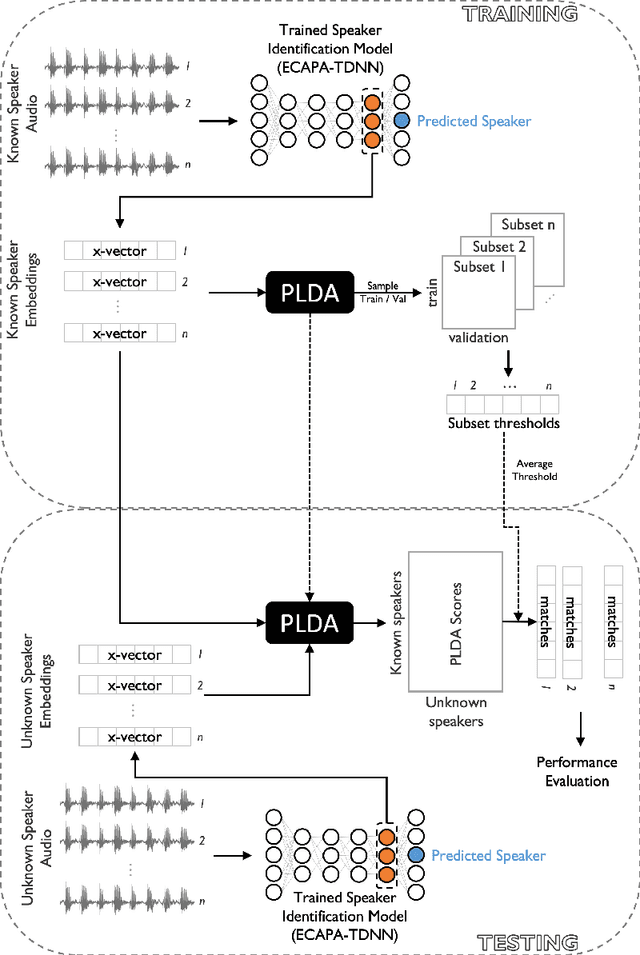
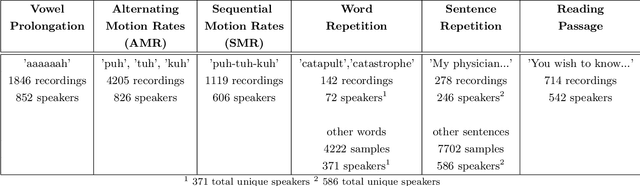
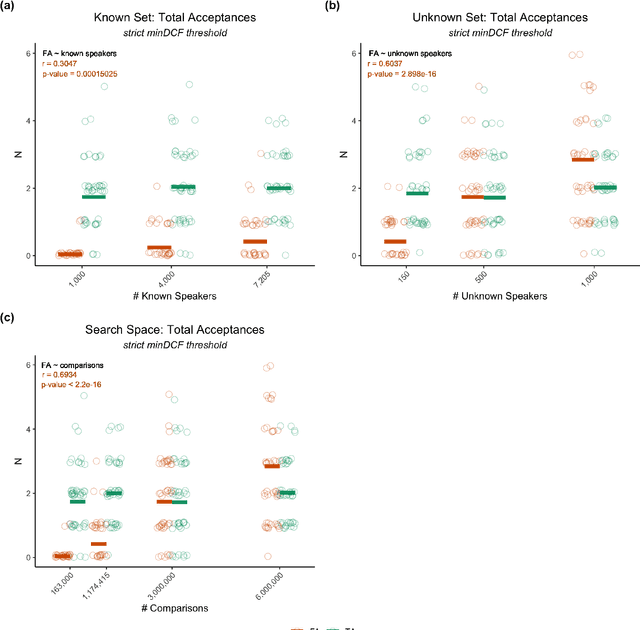
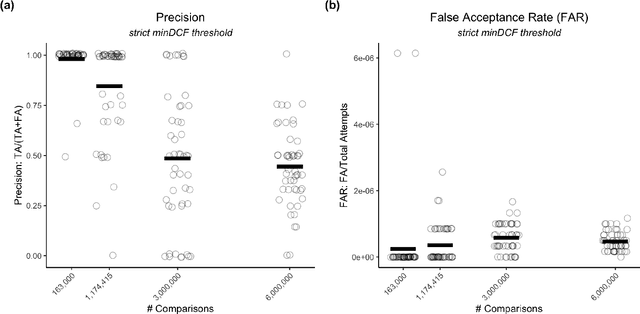
Large, curated datasets are required to leverage speech-based tools in healthcare. These are costly to produce, resulting in increased interest in data sharing. As speech can potentially identify speakers (i.e., voiceprints), sharing recordings raises privacy concerns. We examine the re-identification risk for speech recordings, without reference to demographic or metadata, using a state-of-the-art speaker recognition system. We demonstrate that the risk is inversely related to the number of comparisons an adversary must consider, i.e., the search space. Risk is high for a small search space but drops as the search space grows ($precision >0.85$ for $<1*10^{6}$ comparisons, $precision <0.5$ for $>3*10^{6}$ comparisons). Next, we show that the nature of a speech recording influences re-identification risk, with non-connected speech (e.g., vowel prolongation) being harder to identify. Our findings suggest that speaker recognition systems can be used to re-identify participants in specific circumstances, but in practice, the re-identification risk appears low.