 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Structured Graph Traversal for Root Cause Analysis of Code-related Incidents in Cloud Applications
Dec 26, 2025Cloud incidents pose major operational challenges in production, with unresolved production cloud incidents cost on average over $2M per hour. Prior research identifies code- and configuration-related issues as the predominant category of root causes in cloud incidents. This paper introduces PRAXIS, an orchestrator that manages and deploys an agentic workflow for diagnosing code- and configuration-caused cloud incidents. PRAXIS employs an LLM-driven structured traversal over two types of graph: (1) a service dependency graph (SDG) that captures microservice-level dependencies; and (2) a hammock-block program dependence graph (PDG) that captures code-level dependencies for each microservice. Together, these graphs encode microservice- and code-level dependencies and the LLM acts as a traversal policy over these graphs, moving between services and code dependencies to localize and explain failures. Compared to state-of-the-art ReAct baselines, PRAXIS improves RCA accuracy by up to 3.1x while reducing token consumption by 3.8x. PRAXIS is demonstrated on a set of 30 comprehensive real-world incidents that is being compiled into an RCA benchmark.
Characterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction
Apr 12, 2024Large language models (LLMs) have been driving a new wave of interactive AI applications across numerous domains. However, efficiently serving LLM inference requests is challenging due to their unpredictable execution times originating from the autoregressive nature of generative models. Existing LLM serving systems exploit first-come-first-serve (FCFS) scheduling, suffering from head-of-line blocking issues. To address the non-deterministic nature of LLMs and enable efficient interactive LLM serving, we present a speculative shortest-job-first (SSJF) scheduler that uses a light proxy model to predict LLM output sequence lengths. Our open-source SSJF implementation does not require changes to memory management or batching strategies. Evaluations on real-world datasets and production workload traces show that SSJF reduces average job completion times by 30.5-39.6% and increases throughput by 2.2-3.6x compared to FCFS schedulers, across no batching, dynamic batching, and continuous batching settings.
Watch Out for the Safety-Threatening Actors: Proactively Mitigating Safety Hazards
Jun 02, 2022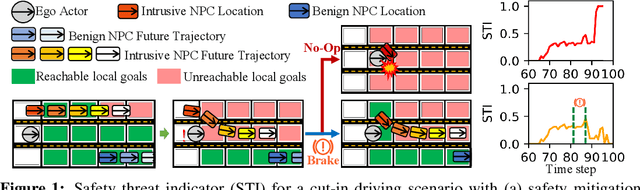

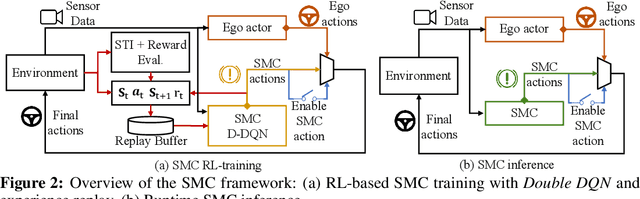
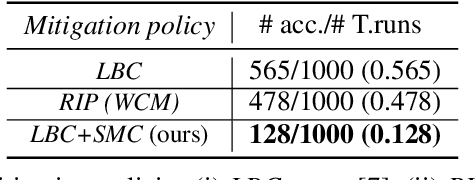
Despite the successful demonstration of autonomous vehicles (AVs), such as self-driving cars, ensuring AV safety remains a challenging task. Although some actors influence an AV's driving decisions more than others, current approaches pay equal attention to each actor on the road. An actor's influence on the AV's decision can be characterized in terms of its ability to decrease the number of safe navigational choices for the AV. In this work, we propose a safety threat indicator (STI) using counterfactual reasoning to estimate the importance of each actor on the road with respect to its influence on the AV's safety. We use this indicator to (i) characterize the existing real-world datasets to identify rare hazardous scenarios as well as the poor performance of existing controllers in such scenarios; and (ii) design an RL based safety mitigation controller to proactively mitigate the safety hazards those actors pose to the AV. Our approach reduces the accident rate for the state-of-the-art AV agent(s) in rare hazardous scenarios by more than 70%.
ML-driven Malware that Targets AV Safety
Apr 24, 2020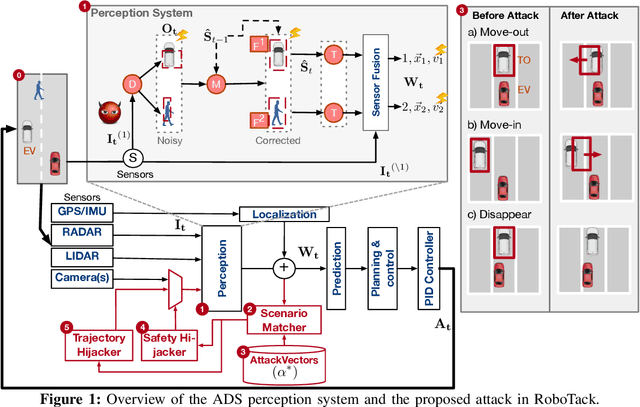


Ensuring the safety of autonomous vehicles (AVs) is critical for their mass deployment and public adoption. However, security attacks that violate safety constraints and cause accidents are a significant deterrent to achieving public trust in AVs, and that hinders a vendor's ability to deploy AVs. Creating a security hazard that results in a severe safety compromise (for example, an accident) is compelling from an attacker's perspective. In this paper, we introduce an attack model, a method to deploy the attack in the form of smart malware, and an experimental evaluation of its impact on production-grade autonomous driving software. We find that determining the time interval during which to launch the attack is{ critically} important for causing safety hazards (such as collisions) with a high degree of success. For example, the smart malware caused 33X more forced emergency braking than random attacks did, and accidents in 52.6% of the driving simulations.
* Accepted for DSN 2020
Live Forensics for Distributed Storage Systems
Jul 24, 2019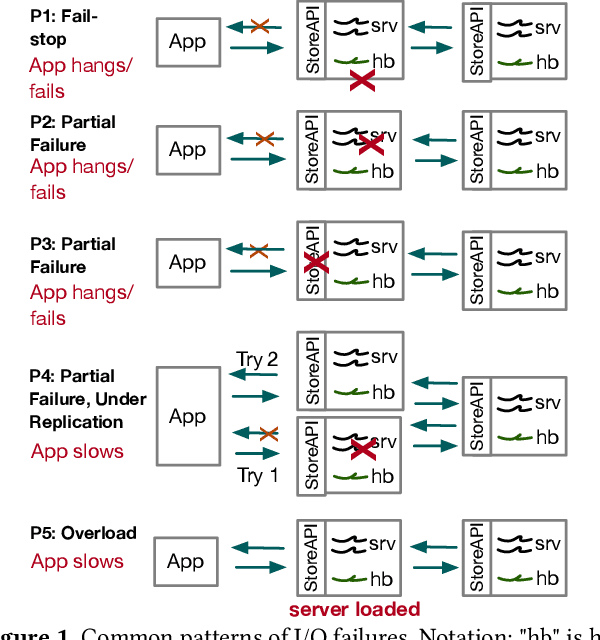



We present Kaleidoscope an innovative system that supports live forensics for application performance problems caused by either individual component failures or resource contention issues in large-scale distributed storage systems. The design of Kaleidoscope is driven by our study of I/O failures observed in a peta-scale storage system anonymized as PetaStore. Kaleidoscope is built on three key features: 1) using temporal and spatial differential observability for end-to-end performance monitoring of I/O requests, 2) modeling the health of storage components as a stochastic process using domain-guided functions that accounts for path redundancy and uncertainty in measurements, and, 3) observing differences in reliability and performance metrics between similar types of healthy and unhealthy components to attribute the most likely root causes. We deployed Kaleidoscope on PetaStore and our evaluation shows that Kaleidoscope can run live forensics at 5-minute intervals and pinpoint the root causes of 95.8% of real-world performance issues, with negligible monitoring overhead.