 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation State Embedding in Partially Observable Cooperative Multi-Agent Reinforcement Learning
Paper and Code
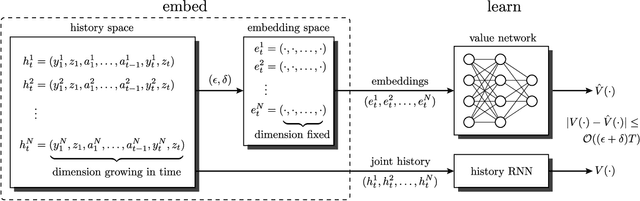
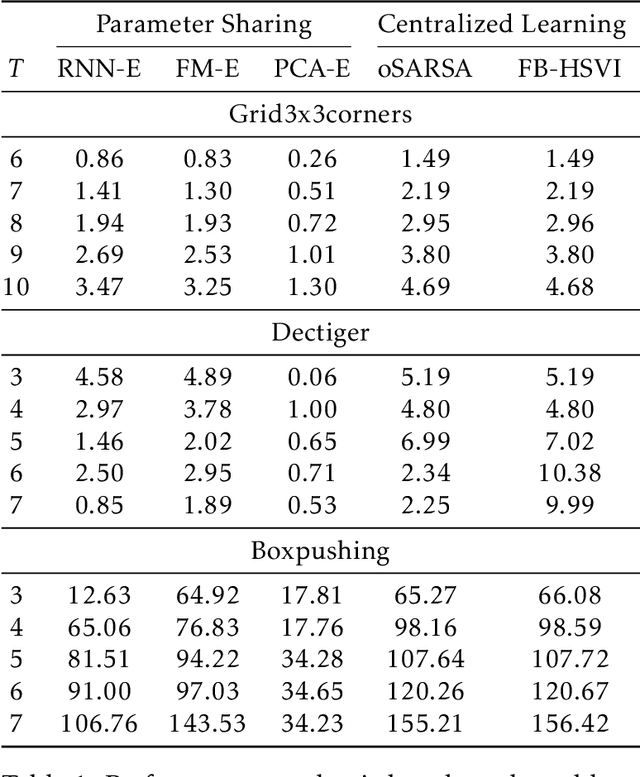
Multi-agent reinforcement learning (MARL) under partial observability has long been considered challenging, primarily due to the requirement for each agent to maintain a belief over all other agents' local histories -- a domain that generally grows exponentially over time. In this work, we investigate a partially observable MARL problem in which agents are cooperative. To enable the development of tractable algorithms, we introduce the concept of an information state embedding that serves to compress agents' histories. We quantify how the compression error influences the resulting value functions for decentralized control. Furthermore, we propose three natural embeddings, based on finite-memory truncation, principal component analysis, and recurrent neural networks. The output of these embeddings are then used as the information state, and can be fed into any MARL algorithm. The proposed embed-then-learn pipeline opens the black-box of existing MARL algorithms, allowing us to establish some theoretical guarantees (error bounds of value functions) while still achieving competitive performance with many end-to-end approaches.