 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Cooperative Multi-Agent Reinforcement Learning with Exploration
Paper and Code
Oct 12, 2021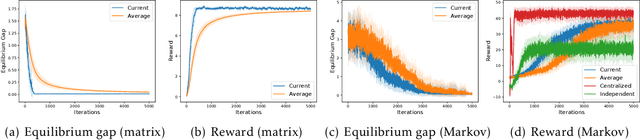

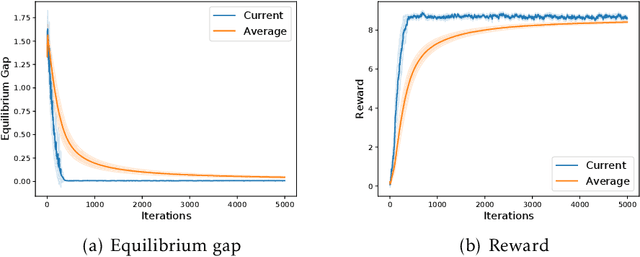
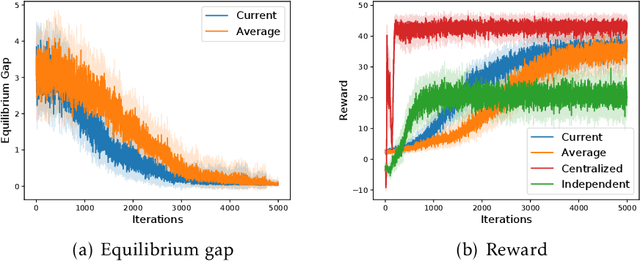
Many real-world applications of multi-agent reinforcement learning (RL), such as multi-robot navigation and decentralized control of cyber-physical systems, involve the cooperation of agents as a team with aligned objectives. We study multi-agent RL in the most basic cooperative setting -- Markov teams -- a class of Markov games where the cooperating agents share a common reward. We propose an algorithm in which each agent independently runs stage-based V-learning (a Q-learning style algorithm) to efficiently explore the unknown environment, while using a stochastic gradient descent (SGD) subroutine for policy updates. We show that the agents can learn an $\epsilon$-approximate Nash equilibrium policy in at most $\propto\widetilde{O}(1/\epsilon^4)$ episodes. Our results advocate the use of a novel \emph{stage-based} V-learning approach to create a stage-wise stationary environment. We also show that under certain smoothness assumptions of the team, our algorithm can achieve a nearly \emph{team-optimal} Nash equilibrium. Simulation results corroborate our theoretical findings. One key feature of our algorithm is being \emph{decentralized}, in the sense that each agent has access to only the state and its local actions, and is even \emph{oblivious} to the presence of the other agents. Neither communication among teammates nor coordination by a central controller is required during learning. Hence, our algorithm can readily generalize to an arbitrary number of agents, without suffering from the exponential dependence on the number of agents.