 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Regret Bounds for Model-Free RL in Non-Stationary Episodic MDPs
Paper and Code
Oct 07, 2020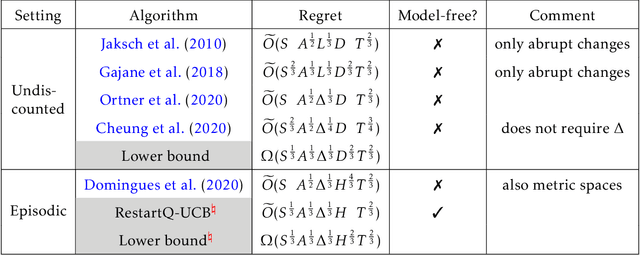
We consider model-free reinforcement learning (RL) in non-stationary Markov decision processes (MDPs). Both the reward functions and the state transition distributions are allowed to vary over time, either gradually or abruptly, as long as their cumulative variation magnitude does not exceed certain budgets. We propose an algorithm, named Restarted Q-Learning with Upper Confidence Bounds (RestartQ-UCB), for this setting, which adopts a simple restarting strategy and an extra optimism term. Our algorithm outperforms the state-of-the-art (model-based) solution in terms of dynamic regret. Specifically, RestartQ-UCB with Freedman-type bonus terms achieves a dynamic regret of $\widetilde{O}(S^{\frac{1}{3}} A^{\frac{1}{3}} \Delta^{\frac{1}{3}} H T^{\frac{2}{3}})$, where $S$ and $A$ are the numbers of states and actions, respectively, $\Delta>0$ is the variation budget, $H$ is the number of steps per episode, and $T$ is the total number of steps. We further show that our algorithm is near-optimal by establishing an information-theoretical lower bound of $\Omega(S^{\frac{1}{3}} A^{\frac{1}{3}} \Delta^{\frac{1}{3}} H^{\frac{2}{3}} T^{\frac{2}{3}})$, which to the best of our knowledge is the first impossibility result in non-stationary RL in general.