 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-kNN-LSH: A Nearest-Neighbor Algorithm for Sequential Counterfactual Inference
Feb 02, 2026Estimating causal effects from longitudinal trajectories is central to understanding the progression of complex conditions and optimizing clinical decision-making, such as comorbidities and long COVID recovery. We introduce \emph{C-kNN--LSH}, a nearest-neighbor framework for sequential causal inference designed to handle such high-dimensional, confounded situations. By utilizing locality-sensitive hashing, we efficiently identify ``clinical twins'' with similar covariate histories, enabling local estimation of conditional treatment effects across evolving disease states. To mitigate bias from irregular sampling and shifting patient recovery profiles, we integrate neighborhood estimator with a doubly-robust correction. Theoretical analysis guarantees our estimator is consistent and second-order robust to nuisance error. Evaluated on a real-world Long COVID cohort with 13,511 participants, \emph{C-kNN-LSH} demonstrates superior performance in capturing recovery heterogeneity and estimating policy values compared to existing baselines.
Wasserstein-p Central Limit Theorem Rates: From Local Dependence to Markov Chains
Jan 13, 2026Finite-time central limit theorem (CLT) rates play a central role in modern machine learning (ML). In this paper, we study CLT rates for multivariate dependent data in Wasserstein-$p$ ($\mathcal W_p$) distance, for general $p\ge 1$. We focus on two fundamental dependence structures that commonly arise in ML: locally dependent sequences and geometrically ergodic Markov chains. In both settings, we establish the \textit{first optimal} $\mathcal O(n^{-1/2})$ rate in $\mathcal W_1$, as well as the first $\mathcal W_p$ ($p\ge 2$) CLT rates under mild moment assumptions, substantially improving the best previously known bounds in these dependent-data regimes. As an application of our optimal $\mathcal W_1$ rate for locally dependent sequences, we further obtain the first optimal $\mathcal W_1$--CLT rate for multivariate $U$-statistics. On the technical side, we derive a tractable auxiliary bound for $\mathcal W_1$ Gaussian approximation errors that is well suited to studying dependent data. For Markov chains, we further prove that the regeneration time of the split chain associated with a geometrically ergodic chain has a geometric tail without assuming strong aperiodicity or other restrictive conditions. These tools may be of independent interests and enable our optimal $\mathcal W_1$ rates and underpin our $\mathcal W_p$ ($p\ge 2$) results.
Contextual Online Pricing with (Biased) Offline Data
Jul 03, 2025We study contextual online pricing with biased offline data. For the scalar price elasticity case, we identify the instance-dependent quantity $\delta^2$ that measures how far the offline data lies from the (unknown) online optimum. We show that the time length $T$, bias bound $V$, size $N$ and dispersion $\lambda_{\min}(\hat{\Sigma})$ of the offline data, and $\delta^2$ jointly determine the statistical complexity. An Optimism-in-the-Face-of-Uncertainty (OFU) policy achieves a minimax-optimal, instance-dependent regret bound $\tilde{\mathcal{O}}\big(d\sqrt{T} \wedge (V^2T + \frac{dT}{\lambda_{\min}(\hat{\Sigma}) + (N \wedge T) \delta^2})\big)$. For general price elasticity, we establish a worst-case, minimax-optimal rate $\tilde{\mathcal{O}}\big(d\sqrt{T} \wedge (V^2T + \frac{dT }{\lambda_{\min}(\hat{\Sigma})})\big)$ and provide a generalized OFU algorithm that attains it. When the bias bound $V$ is unknown, we design a robust variant that always guarantees sub-linear regret and strictly improves on purely online methods whenever the exact bias is small. These results deliver the first tight regret guarantees for contextual pricing in the presence of biased offline data. Our techniques also transfer verbatim to stochastic linear bandits with biased offline data, yielding analogous bounds.
A Piecewise Lyapunov Analysis of Sub-quadratic SGD: Applications to Robust and Quantile Regression
Apr 15, 2025Motivated by robust and quantile regression problems, we investigate the stochastic gradient descent (SGD) algorithm for minimizing an objective function $f$ that is locally strongly convex with a sub--quadratic tail. This setting covers many widely used online statistical methods. We introduce a novel piecewise Lyapunov function that enables us to handle functions $f$ with only first-order differentiability, which includes a wide range of popular loss functions such as Huber loss. Leveraging our proposed Lyapunov function, we derive finite-time moment bounds under general diminishing stepsizes, as well as constant stepsizes. We further establish the weak convergence, central limit theorem and bias characterization under constant stepsize, providing the first geometrical convergence result for sub--quadratic SGD. Our results have wide applications, especially in online statistical methods. In particular, we discuss two applications of our results. 1) Online robust regression: We consider a corrupted linear model with sub--exponential covariates and heavy--tailed noise. Our analysis provides convergence rates comparable to those for corrupted models with Gaussian covariates and noise. 2) Online quantile regression: Importantly, our results relax the common assumption in prior work that the conditional density is continuous and provide a more fine-grained analysis for the moment bounds.
Optimally Installing Strict Equilibria
Mar 05, 2025In this work, we develop a reward design framework for installing a desired behavior as a strict equilibrium across standard solution concepts: dominant strategy equilibrium, Nash equilibrium, correlated equilibrium, and coarse correlated equilibrium. We also extend our framework to capture the Markov-perfect equivalents of each solution concept. Central to our framework is a comprehensive mathematical characterization of strictly installable, based on the desired solution concept and the behavior's structure. These characterizations lead to efficient iterative algorithms, which we generalize to handle optimization objectives through linear programming. Finally, we explore how our results generalize to bounded rational agents.
Coupling-based Convergence Diagnostic and Stepsize Scheme for Stochastic Gradient Descent
Dec 15, 2024



The convergence behavior of Stochastic Gradient Descent (SGD) crucially depends on the stepsize configuration. When using a constant stepsize, the SGD iterates form a Markov chain, enjoying fast convergence during the initial transient phase. However, when reaching stationarity, the iterates oscillate around the optimum without making further progress. In this paper, we study the convergence diagnostics for SGD with constant stepsize, aiming to develop an effective dynamic stepsize scheme. We propose a novel coupling-based convergence diagnostic procedure, which monitors the distance of two coupled SGD iterates for stationarity detection. Our diagnostic statistic is simple and is shown to track the transition from transience stationarity theoretically. We conduct extensive numerical experiments and compare our method against various existing approaches. Our proposed coupling-based stepsize scheme is observed to achieve superior performance across a diverse set of convex and non-convex problems. Moreover, our results demonstrate the robustness of our approach to a wide range of hyperparameters.
Two-Timescale Linear Stochastic Approximation: Constant Stepsizes Go a Long Way
Oct 16, 2024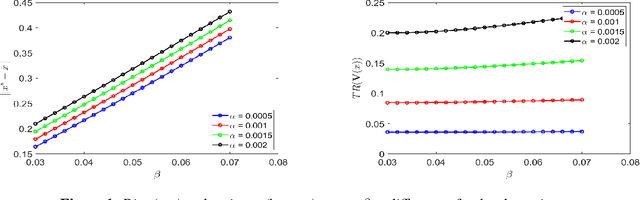
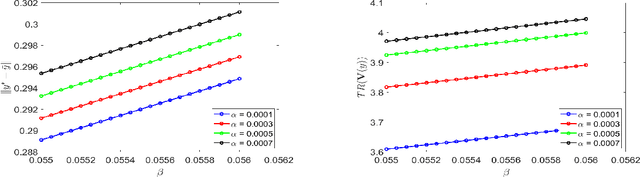
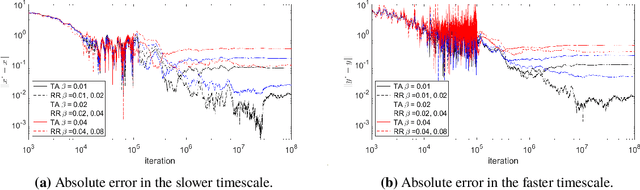
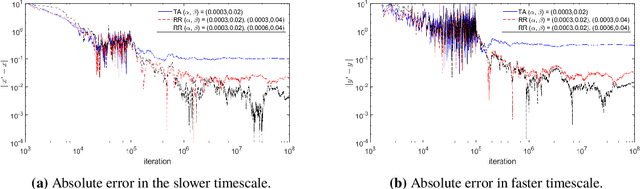
Previous studies on two-timescale stochastic approximation (SA) mainly focused on bounding mean-squared errors under diminishing stepsize schemes. In this work, we investigate {\it constant} stpesize schemes through the lens of Markov processes, proving that the iterates of both timescales converge to a unique joint stationary distribution in Wasserstein metric. We derive explicit geometric and non-asymptotic convergence rates, as well as the variance and bias introduced by constant stepsizes in the presence of Markovian noise. Specifically, with two constant stepsizes $\alpha < \beta$, we show that the biases scale linearly with both stepsizes as $\Theta(\alpha)+\Theta(\beta)$ up to higher-order terms, while the variance of the slower iterate (resp., faster iterate) scales only with its own stepsize as $O(\alpha)$ (resp., $O(\beta)$). Unlike previous work, our results require no additional assumptions such as $\beta^2 \ll \alpha$ nor extra dependence on dimensions. These fine-grained characterizations allow tail-averaging and extrapolation techniques to reduce variance and bias, improving mean-squared error bound to $O(\beta^4 + \frac{1}{t})$ for both iterates.
Stable Offline Value Function Learning with Bisimulation-based Representations
Oct 02, 2024



In reinforcement learning, offline value function learning is the procedure of using an offline dataset to estimate the expected discounted return from each state when taking actions according to a fixed target policy. The stability of this procedure, i.e., whether it converges to its fixed-point, critically depends on the representations of the state-action pairs. Poorly learned representations can make value function learning unstable, or even divergent. Therefore, it is critical to stabilize value function learning by explicitly shaping the state-action representations. Recently, the class of bisimulation-based algorithms have shown promise in shaping representations for control. However, it is still unclear if this class of methods can stabilize value function learning. In this work, we investigate this question and answer it affirmatively. We introduce a bisimulation-based algorithm called kernel representations for offline policy evaluation (KROPE). KROPE uses a kernel to shape state-action representations such that state-action pairs that have similar immediate rewards and lead to similar next state-action pairs under the target policy also have similar representations. We show that KROPE: 1) learns stable representations and 2) leads to lower value error than baselines. Our analysis provides new theoretical insight into the stability properties of bisimulation-based methods and suggests that practitioners can use these methods for stable and accurate evaluation of offline reinforcement learning agents.
Inception: Efficiently Computable Misinformation Attacks on Markov Games
Jun 24, 2024

We study security threats to Markov games due to information asymmetry and misinformation. We consider an attacker player who can spread misinformation about its reward function to influence the robust victim player's behavior. Given a fixed fake reward function, we derive the victim's policy under worst-case rationality and present polynomial-time algorithms to compute the attacker's optimal worst-case policy based on linear programming and backward induction. Then, we provide an efficient inception ("planting an idea in someone's mind") attack algorithm to find the optimal fake reward function within a restricted set of reward functions with dominant strategies. Importantly, our methods exploit the universal assumption of rationality to compute attacks efficiently. Thus, our work exposes a security vulnerability arising from standard game assumptions under misinformation.
Roping in Uncertainty: Robustness and Regularization in Markov Games
Jun 13, 2024We study robust Markov games (RMG) with $s$-rectangular uncertainty. We show a general equivalence between computing a robust Nash equilibrium (RNE) of a $s$-rectangular RMG and computing a Nash equilibrium (NE) of an appropriately constructed regularized MG. The equivalence result yields a planning algorithm for solving $s$-rectangular RMGs, as well as provable robustness guarantees for policies computed using regularized methods. However, we show that even for just reward-uncertain two-player zero-sum matrix games, computing an RNE is PPAD-hard. Consequently, we derive a special uncertainty structure called efficient player-decomposability and show that RNE for two-player zero-sum RMG in this class can be provably solved in polynomial time. This class includes commonly used uncertainty sets such as $L_1$ and $L_\infty$ ball uncertainty sets.