 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Autoscaling for Large Language Model Serving with Chiron
Jan 14, 2025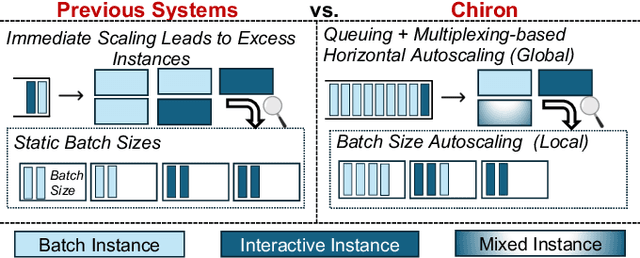
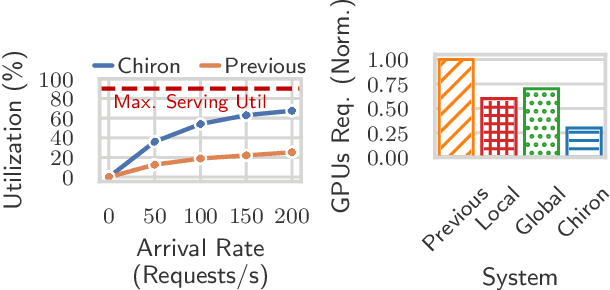
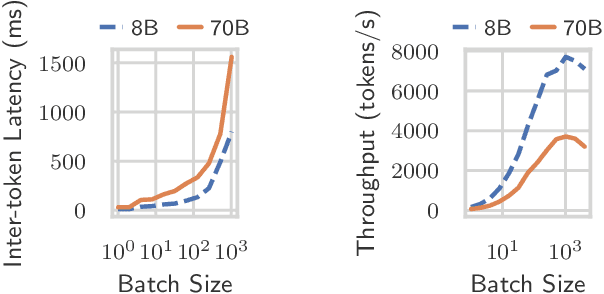

Large language model (LLM) serving is becoming an increasingly important workload for cloud providers. Based on performance SLO requirements, LLM inference requests can be divided into (a) interactive requests that have tight SLOs in the order of seconds, and (b) batch requests that have relaxed SLO in the order of minutes to hours. These SLOs can degrade based on the arrival rates, multiplexing, and configuration parameters, thus necessitating the use of resource autoscaling on serving instances and their batch sizes. However, previous autoscalers for LLM serving do not consider request SLOs leading to unnecessary scaling and resource under-utilization. To address these limitations, we introduce Chiron, an autoscaler that uses the idea of hierarchical backpressure estimated using queue size, utilization, and SLOs. Our experiments show that Chiron achieves up to 90% higher SLO attainment and improves GPU efficiency by up to 70% compared to existing solutions.
CyNetDiff -- A Python Library for Accelerated Implementation of Network Diffusion Models
Apr 25, 2024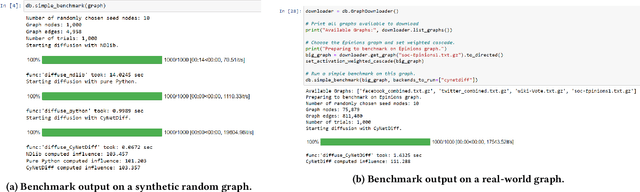
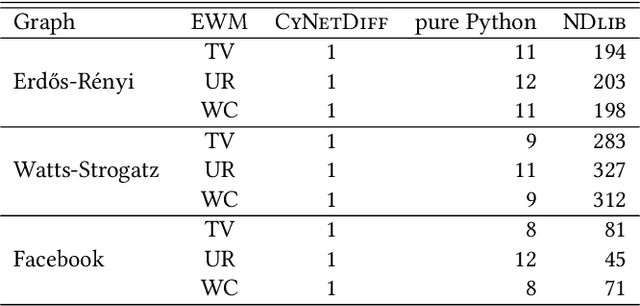

In recent years, there has been increasing interest in network diffusion models and related problems. The most popular of these are the independent cascade and linear threshold models. Much of the recent experimental work done on these models requires a large number of simulations conducted on large graphs, a computationally expensive task suited for low-level languages. However, many researchers prefer the use of higher-level languages (such as Python) for their flexibility and shorter development times. Moreover, in many research tasks, these simulations are the most computationally intensive task, so it would be desirable to have a library for these with an interface to a high-level language with the performance of a low-level language. To fill this niche, we introduce CyNetDiff, a Python library with components written in Cython to provide improved performance for these computationally intensive diffusion tasks.