 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePresAIse, A Prescriptive AI Solution for Enterprises
Feb 13, 2024Prescriptive AI represents a transformative shift in decision-making, offering causal insights and actionable recommendations. Despite its huge potential, enterprise adoption often faces several challenges. The first challenge is caused by the limitations of observational data for accurate causal inference which is typically a prerequisite for good decision-making. The second pertains to the interpretability of recommendations, which is crucial for enterprise decision-making settings. The third challenge is the silos between data scientists and business users, hindering effective collaboration. This paper outlines an initiative from IBM Research, aiming to address some of these challenges by offering a suite of prescriptive AI solutions. Leveraging insights from various research papers, the solution suite includes scalable causal inference methods, interpretable decision-making approaches, and the integration of large language models (LLMs) to bridge communication gaps via a conversation agent. A proof-of-concept, PresAIse, demonstrates the solutions' potential by enabling non-ML experts to interact with prescriptive AI models via a natural language interface, democratizing advanced analytics for strategic decision-making.
An Optimistic-Robust Approach for Dynamic Positioning of Omnichannel Inventories
Oct 17, 2023
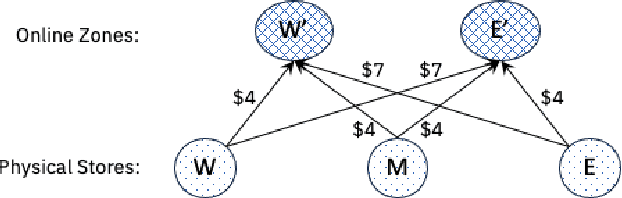
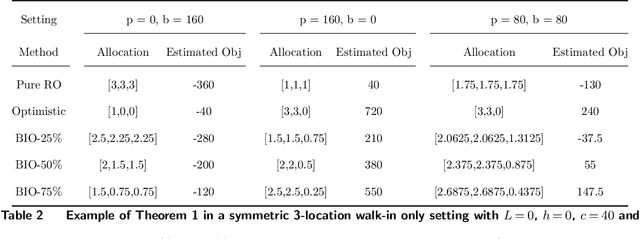
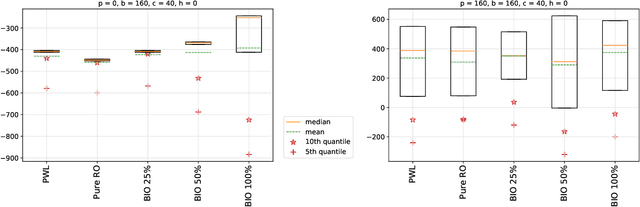
We introduce a new class of data-driven and distribution-free optimistic-robust bimodal inventory optimization (BIO) strategy to effectively allocate inventory across a retail chain to meet time-varying, uncertain omnichannel demand. While prior Robust optimization (RO) methods emphasize the downside, i.e., worst-case adversarial demand, BIO also considers the upside to remain resilient like RO while also reaping the rewards of improved average-case performance by overcoming the presence of endogenous outliers. This bimodal strategy is particularly valuable for balancing the tradeoff between lost sales at the store and the costs of cross-channel e-commerce fulfillment, which is at the core of our inventory optimization model. These factors are asymmetric due to the heterogenous behavior of the channels, with a bias towards the former in terms of lost-sales cost and a dependence on network effects for the latter. We provide structural insights about the BIO solution and how it can be tuned to achieve a preferred tradeoff between robustness and the average-case. Our experiments show that significant benefits can be achieved by rethinking traditional approaches to inventory management, which are siloed by channel and location. Using a real-world dataset from a large American omnichannel retail chain, a business value assessment during a peak period indicates over a 15% profitability gain for BIO over RO and other baselines while also preserving the (practical) worst case performance.
Scalable Optimal Multiway-Split Decision Trees with Constraints
Feb 14, 2023There has been a surge of interest in learning optimal decision trees using mixed-integer programs (MIP) in recent years, as heuristic-based methods do not guarantee optimality and find it challenging to incorporate constraints that are critical for many practical applications. However, existing MIP methods that build on an arc-based formulation do not scale well as the number of binary variables is in the order of $\mathcal{O}(2^dN)$, where $d$ and $N$ refer to the depth of the tree and the size of the dataset. Moreover, they can only handle sample-level constraints and linear metrics. In this paper, we propose a novel path-based MIP formulation where the number of decision variables is independent of $N$. We present a scalable column generation framework to solve the MIP optimally. Our framework produces a multiway-split tree which is more interpretable than the typical binary-split trees due to its shorter rules. Our method can handle nonlinear metrics such as F1 score and incorporate a broader class of constraints. We demonstrate its efficacy with extensive experiments. We present results on datasets containing up to 1,008,372 samples while existing MIP-based decision tree models do not scale well on data beyond a few thousand points. We report superior or competitive results compared to the state-of-art MIP-based methods with up to a 24X reduction in runtime.
Constrained Prescriptive Trees via Column Generation
Jul 20, 2022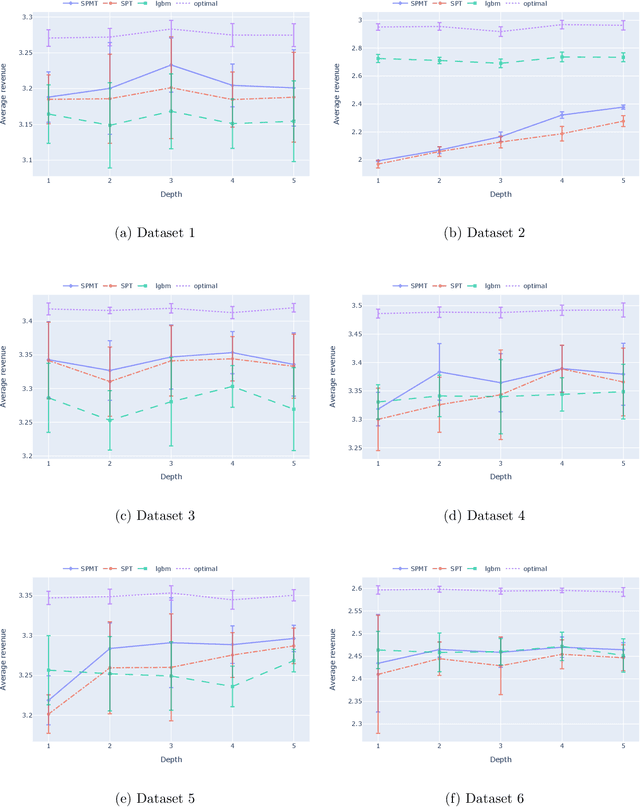

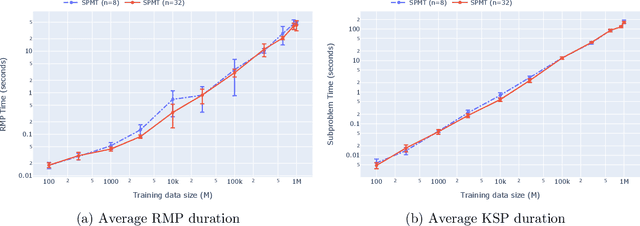
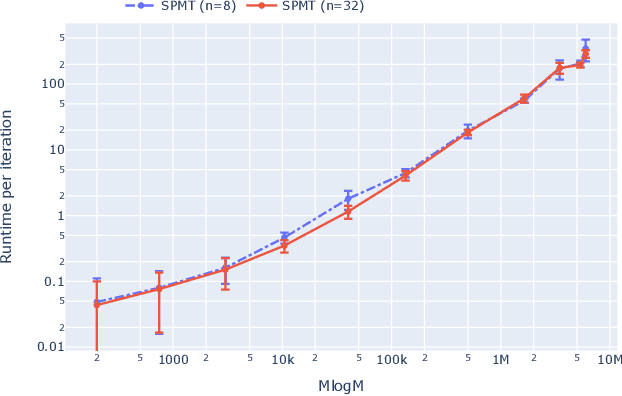
With the abundance of available data, many enterprises seek to implement data-driven prescriptive analytics to help them make informed decisions. These prescriptive policies need to satisfy operational constraints, and proactively eliminate rule conflicts, both of which are ubiquitous in practice. It is also desirable for them to be simple and interpretable, so they can be easily verified and implemented. Existing approaches from the literature center around constructing variants of prescriptive decision trees to generate interpretable policies. However, none of the existing methods are able to handle constraints. In this paper, we propose a scalable method that solves the constrained prescriptive policy generation problem. We introduce a novel path-based mixed-integer program (MIP) formulation which identifies a (near) optimal policy efficiently via column generation. The policy generated can be represented as a multiway-split tree which is more interpretable and informative than a binary-split tree due to its shorter rules. We demonstrate the efficacy of our method with extensive experiments on both synthetic and real datasets.