 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Encrypted Inference on Ensembles of Decision Trees
Mar 05, 2021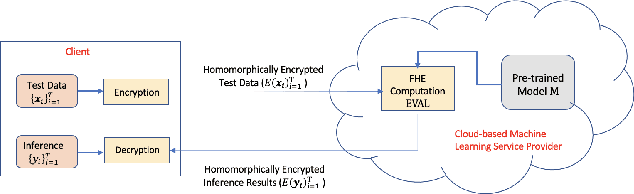

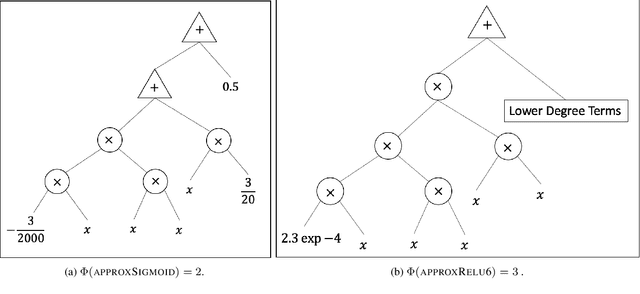
Data privacy concerns often prevent the use of cloud-based machine learning services for sensitive personal data. While homomorphic encryption (HE) offers a potential solution by enabling computations on encrypted data, the challenge is to obtain accurate machine learning models that work within the multiplicative depth constraints of a leveled HE scheme. Existing approaches for encrypted inference either make ad-hoc simplifications to a pre-trained model (e.g., replace hard comparisons in a decision tree with soft comparators) at the cost of accuracy or directly train a new depth-constrained model using the original training set. In this work, we propose a framework to transfer knowledge extracted by complex decision tree ensembles to shallow neural networks (referred to as DTNets) that are highly conducive to encrypted inference. Our approach minimizes the accuracy loss by searching for the best DTNet architecture that operates within the given depth constraints and training this DTNet using only synthetic data sampled from the training data distribution. Extensive experiments on real-world datasets demonstrate that these characteristics are critical in ensuring that DTNet accuracy approaches that of the original tree ensemble. Our system is highly scalable and can perform efficient inference on batched encrypted (134 bits of security) data with amortized time in milliseconds. This is approximately three orders of magnitude faster than the standard approach of applying soft comparison at the internal nodes of the ensemble trees.
Efficient CNN Building Blocks for Encrypted Data
Jan 30, 2021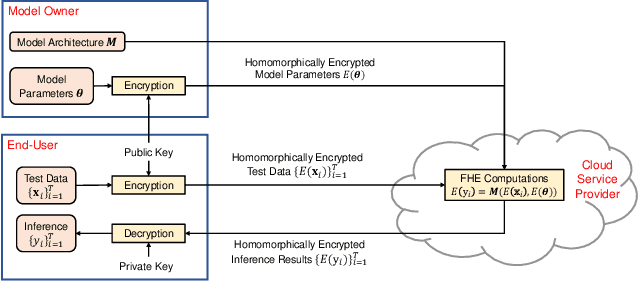

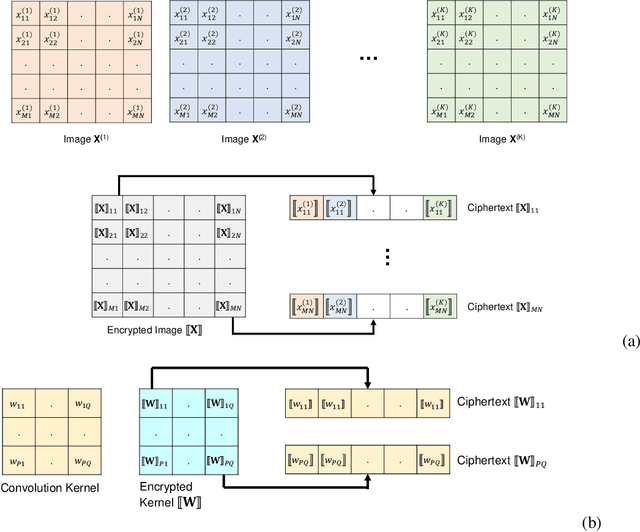
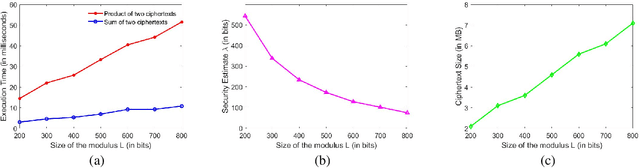
Machine learning on encrypted data can address the concerns related to privacy and legality of sharing sensitive data with untrustworthy service providers. Fully Homomorphic Encryption (FHE) is a promising technique to enable machine learning and inferencing while providing strict guarantees against information leakage. Since deep convolutional neural networks (CNNs) have become the machine learning tool of choice in several applications, several attempts have been made to harness CNNs to extract insights from encrypted data. However, existing works focus only on ensuring data security and ignore security of model parameters. They also report high level implementations without providing rigorous analysis of the accuracy, security, and speed trade-offs involved in the FHE implementation of generic primitive operators of a CNN such as convolution, non-linear activation, and pooling. In this work, we consider a Machine Learning as a Service (MLaaS) scenario where both input data and model parameters are secured using FHE. Using the CKKS scheme available in the open-source HElib library, we show that operational parameters of the chosen FHE scheme such as the degree of the cyclotomic polynomial, depth limitations of the underlying leveled HE scheme, and the computational precision parameters have a major impact on the design of the machine learning model (especially, the choice of the activation function and pooling method). Our empirical study shows that choice of aforementioned design parameters result in significant trade-offs between accuracy, security level, and computational time. Encrypted inference experiments on the MNIST dataset indicate that other design choices such as ciphertext packing strategy and parallelization using multithreading are also critical in determining the throughput and latency of the inference process.
Distributed Bundle Adjustment
Aug 26, 2017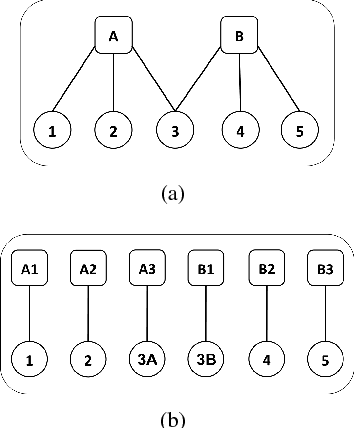
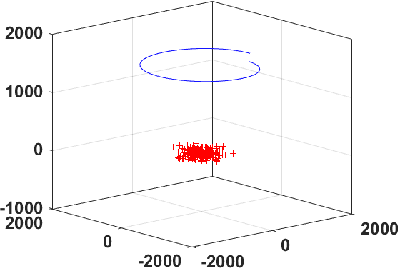
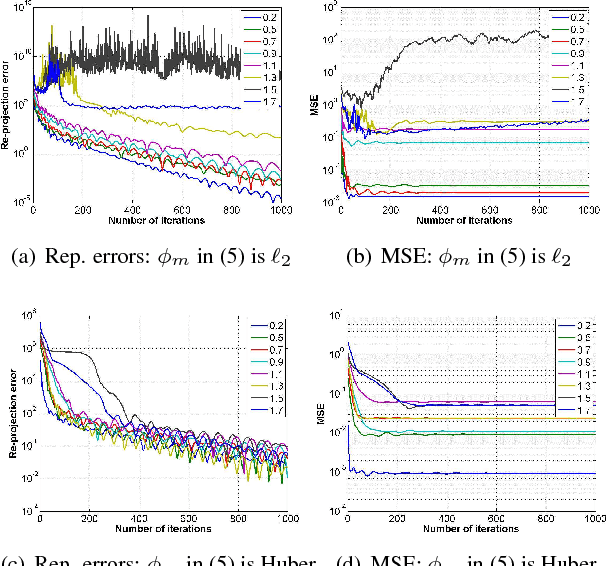
Most methods for Bundle Adjustment (BA) in computer vision are either centralized or operate incrementally. This leads to poor scaling and affects the quality of solution as the number of images grows in large scale structure from motion (SfM). Furthermore, they cannot be used in scenarios where image acquisition and processing must be distributed. We address this problem with a new distributed BA algorithm. Our distributed formulation uses alternating direction method of multipliers (ADMM), and, since each processor sees only a small portion of the data, we show that robust formulations improve performance. We analyze convergence of the proposed algorithm, and illustrate numerical performance, accuracy of the parameter estimates, and scalability of the distributed implementation in the context of synthetic 3D datasets with known camera position and orientation ground truth. The results are comparable to an alternate state-of-the-art centralized bundle adjustment algorithm on synthetic and real 3D reconstruction problems. The runtime of our implementation scales linearly with the number of observed points.
Deep Learning Ensembles for Melanoma Recognition in Dermoscopy Images
Oct 18, 2016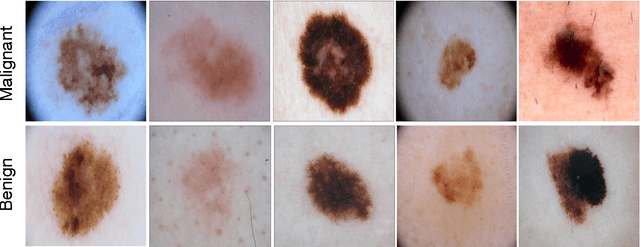

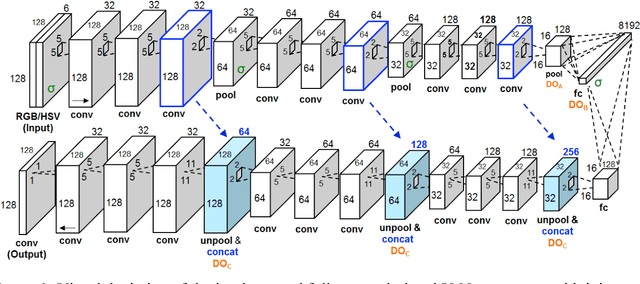
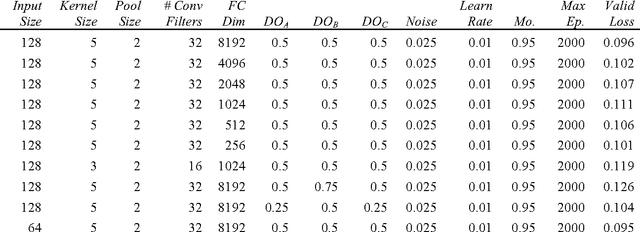
Melanoma is the deadliest form of skin cancer. While curable with early detection, only highly trained specialists are capable of accurately recognizing the disease. As expertise is in limited supply, automated systems capable of identifying disease could save lives, reduce unnecessary biopsies, and reduce costs. Toward this goal, we propose a system that combines recent developments in deep learning with established machine learning approaches, creating ensembles of methods that are capable of segmenting skin lesions, as well as analyzing the detected area and surrounding tissue for melanoma detection. The system is evaluated using the largest publicly available benchmark dataset of dermoscopic images, containing 900 training and 379 testing images. New state-of-the-art performance levels are demonstrated, leading to an improvement in the area under receiver operating characteristic curve of 7.5% (0.843 vs. 0.783), in average precision of 4% (0.649 vs. 0.624), and in specificity measured at the clinically relevant 95% sensitivity operating point 2.9 times higher than the previous state-of-the-art (36.8% specificity compared to 12.5%). Compared to the average of 8 expert dermatologists on a subset of 100 test images, the proposed system produces a higher accuracy (76% vs. 70.5%), and specificity (62% vs. 59%) evaluated at an equivalent sensitivity (82%).
* URL for the IBM Journal of Research and Development: http://www.research.ibm.com/journal/