 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Edge deployment and ondevice acceleration of multi-LoRA enabled one-for-all foundational LLM
Apr 20, 2026Deploying large language models (LLMs) on smartphones poses significant engineering challenges due to stringent constraints on memory, latency, and runtime flexibility. In this work, we present a hardware-aware framework for efficient on-device inference of a LLaMA-based multilingual foundation model supporting multiple use cases on Samsung Galaxy S24 and S25 devices with SM8650 and SM8750 Qualcomm chipsets respectively. Our approach integrates application-specific LoRAs as runtime inputs to a single frozen inference graph, enabling dynamic task switching without recompilation or memory overhead. We further introduce a multi-stream decoding mechanism that concurrently generates stylistic variations - such as formal, polite, or jovial responses - within a single forward pass, reducing latency by up to 6x. To accelerate token generation, we apply Dynamic Self-Speculative Decoding (DS2D), a tree-based strategy that predicts future tokens without requiring a draft model, yielding up to 2.3x speedup in decode time. Combined with quantization to INT4 and architecture-level optimizations, our system achieves 4-6x overall improvements in memory and latency while maintaining accuracy across 9 languages and 8 tasks. These results demonstrate practical feasibility of deploying multi-use-case LLMs on edge devices, advancing the commercial viability of Generative AI in mobile platforms.
Continual learning with task specialist
Sep 26, 2024



Continual learning (CL) adapt the deep learning scenarios with timely updated datasets. However, existing CL models suffer from the catastrophic forgetting issue, where new knowledge replaces past learning. In this paper, we propose Continual Learning with Task Specialists (CLTS) to address the issues of catastrophic forgetting and limited labelled data in real-world datasets by performing class incremental learning of the incoming stream of data. The model consists of Task Specialists (T S) and Task Predictor (T P ) with pre-trained Stable Diffusion (SD) module. Here, we introduce a new specialist to handle a new task sequence and each T S has three blocks; i) a variational autoencoder (V AE) to learn the task distribution in a low dimensional latent space, ii) a K-Means block to perform data clustering and iii) Bootstrapping Language-Image Pre-training (BLIP ) model to generate a small batch of captions from the input data. These captions are fed as input to the pre-trained stable diffusion model (SD) for the generation of task samples. The proposed model does not store any task samples for replay, instead uses generated samples from SD to train the T P module. A comparison study with four SOTA models conducted on three real-world datasets shows that the proposed model outperforms all the selected baselines
U-TELL: Unsupervised Task Expert Lifelong Learning
May 23, 2024



Continual learning (CL) models are designed to learn new tasks arriving sequentially without re-training the network. However, real-world ML applications have very limited label information and these models suffer from catastrophic forgetting. To address these issues, we propose an unsupervised CL model with task experts called Unsupervised Task Expert Lifelong Learning (U-TELL) to continually learn the data arriving in a sequence addressing catastrophic forgetting. During training of U-TELL, we introduce a new expert on arrival of a new task. Our proposed architecture has task experts, a structured data generator and a task assigner. Each task expert is composed of 3 blocks; i) a variational autoencoder to capture the task distribution and perform data abstraction, ii) a k-means clustering module, and iii) a structure extractor to preserve latent task data signature. During testing, task assigner selects a suitable expert to perform clustering. U-TELL does not store or replay task samples, instead, we use generated structured samples to train the task assigner. We compared U-TELL with five SOTA unsupervised CL methods. U-TELL outperformed all baselines on seven benchmarks and one industry dataset for various CL scenarios with a training time over 6 times faster than the best performing baseline.
Prediction of Transportation Index for Urban Patterns in Small and Medium-sized Indian Cities using Hybrid RidgeGAN Model
Jun 09, 2023The rapid urbanization trend in most developing countries including India is creating a plethora of civic concerns such as loss of green space, degradation of environmental health, clean water availability, air pollution, traffic congestion leading to delays in vehicular transportation, etc. Transportation and network modeling through transportation indices have been widely used to understand transportation problems in the recent past. This necessitates predicting transportation indices to facilitate sustainable urban planning and traffic management. Recent advancements in deep learning research, in particular, Generative Adversarial Networks (GANs), and their modifications in spatial data analysis such as CityGAN, Conditional GAN, and MetroGAN have enabled urban planners to simulate hyper-realistic urban patterns. These synthetic urban universes mimic global urban patterns and evaluating their landscape structures through spatial pattern analysis can aid in comprehending landscape dynamics, thereby enhancing sustainable urban planning. This research addresses several challenges in predicting the urban transportation index for small and medium-sized Indian cities. A hybrid framework based on Kernel Ridge Regression (KRR) and CityGAN is introduced to predict transportation index using spatial indicators of human settlement patterns. This paper establishes a relationship between the transportation index and human settlement indicators and models it using KRR for the selected 503 Indian cities. The proposed hybrid pipeline, we call it RidgeGAN model, can evaluate the sustainability of urban sprawl associated with infrastructure development and transportation systems in sprawling cities. Experimental results show that the two-step pipeline approach outperforms existing benchmarks based on spatial and statistical measures.
An ensemble neural network approach to forecast Dengue outbreak based on climatic condition
Dec 20, 2022



Dengue fever is a virulent disease spreading over 100 tropical and subtropical countries in Africa, the Americas, and Asia. This arboviral disease affects around 400 million people globally, severely distressing the healthcare systems. The unavailability of a specific drug and ready-to-use vaccine makes the situation worse. Hence, policymakers must rely on early warning systems to control intervention-related decisions. Forecasts routinely provide critical information for dangerous epidemic events. However, the available forecasting models (e.g., weather-driven mechanistic, statistical time series, and machine learning models) lack a clear understanding of different components to improve prediction accuracy and often provide unstable and unreliable forecasts. This study proposes an ensemble wavelet neural network with exogenous factor(s) (XEWNet) model that can produce reliable estimates for dengue outbreak prediction for three geographical regions, namely San Juan, Iquitos, and Ahmedabad. The proposed XEWNet model is flexible and can easily incorporate exogenous climate variable(s) confirmed by statistical causality tests in its scalable framework. The proposed model is an integrated approach that uses wavelet transformation into an ensemble neural network framework that helps in generating more reliable long-term forecasts. The proposed XEWNet allows complex non-linear relationships between the dengue incidence cases and rainfall; however, mathematically interpretable, fast in execution, and easily comprehensible. The proposal's competitiveness is measured using computational experiments based on various statistical metrics and several statistical comparison tests. In comparison with statistical, machine learning, and deep learning methods, our proposed XEWNet performs better in 75% of the cases for short-term and long-term forecasting of dengue incidence.
Epicasting: An Ensemble Wavelet Neural Network (EWNet) for Forecasting Epidemics
Jun 21, 2022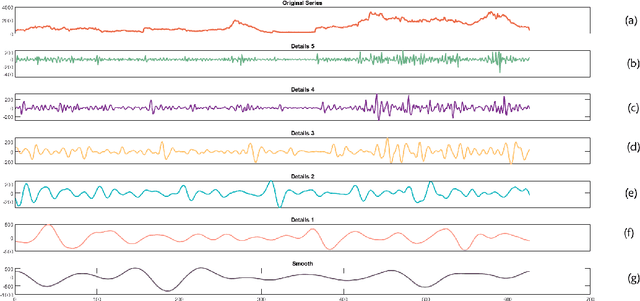
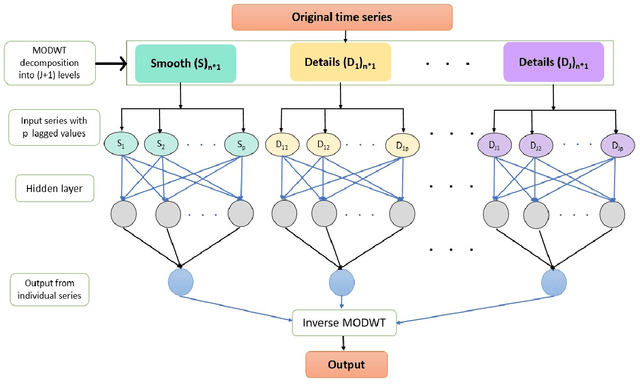
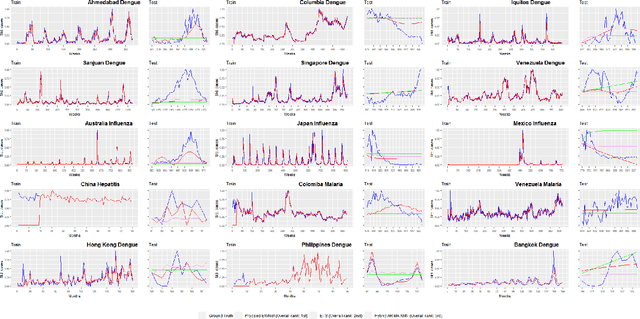
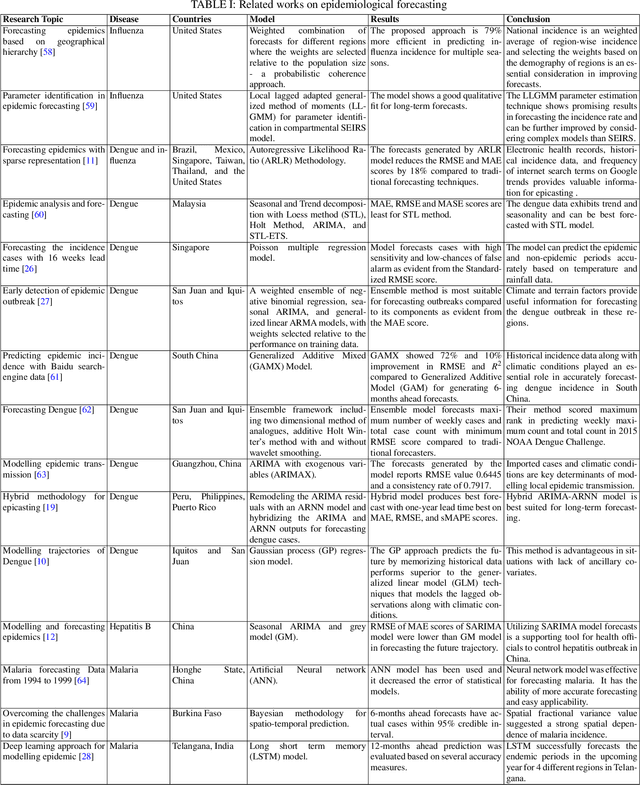
Infectious diseases remain among the top contributors to human illness and death worldwide, among which many diseases produce epidemic waves of infection. The unavailability of specific drugs and ready-to-use vaccines to prevent most of these epidemics makes the situation worse. These force public health officials, health care providers, and policymakers to rely on early warning systems generated by reliable and accurate forecasts of epidemics. Accurate forecasts of epidemics can assist stakeholders in tailoring countermeasures, such as vaccination campaigns, staff scheduling, and resource allocation, to the situation at hand, which could translate to reductions in the impact of a disease. Unfortunately, most of these past epidemics (e.g., dengue, malaria, hepatitis, influenza, and most recent, Covid-19) exhibit nonlinear and non-stationary characteristics due to their spreading fluctuations based on seasonal-dependent variability and the nature of these epidemics. We analyze a wide variety of epidemic time series datasets using a maximal overlap discrete wavelet transform (MODWT) based autoregressive neural network and call it EWNet. MODWT techniques effectively characterize non-stationary behavior and seasonal dependencies in the epidemic time series and improve the forecasting scheme of the autoregressive neural network in the proposed ensemble wavelet network framework. From a nonlinear time series viewpoint, we explore the asymptotic stationarity of the proposed EWNet model to show the asymptotic behavior of the associated Markov Chain. We also theoretically investigate the effect of learning stability and the choice of hidden neurons in the proposed EWNet model. From a practical perspective, we compare our proposed EWNet framework with several statistical, machine learning, and deep learning models that have been previously used for epidemic forecasting.
Semantic Answer Type and Relation Prediction Task (SMART 2021)
Jan 10, 2022
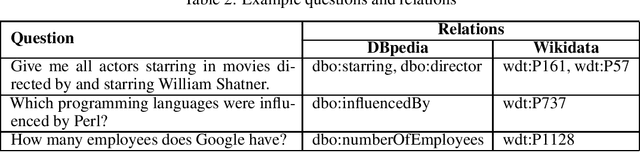
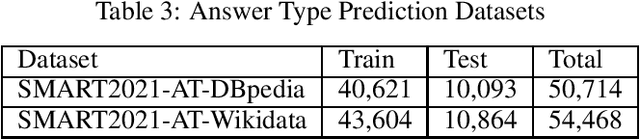
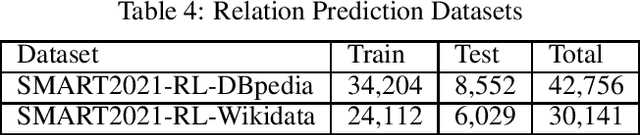
Each year the International Semantic Web Conference organizes a set of Semantic Web Challenges to establish competitions that will advance state-of-the-art solutions in some problem domains. The Semantic Answer Type and Relation Prediction Task (SMART) task is one of the ISWC 2021 Semantic Web challenges. This is the second year of the challenge after a successful SMART 2020 at ISWC 2020. This year's version focuses on two sub-tasks that are very important to Knowledge Base Question Answering (KBQA): Answer Type Prediction and Relation Prediction. Question type and answer type prediction can play a key role in knowledge base question answering systems providing insights about the expected answer that are helpful to generate correct queries or rank the answer candidates. More concretely, given a question in natural language, the first task is, to predict the answer type using a target ontology (e.g., DBpedia or Wikidata. Similarly, the second task is to identify relations in the natural language query and link them to the relations in a target ontology. This paper discusses the task descriptions, benchmark datasets, and evaluation metrics. For more information, please visit https://smart-task.github.io/2021/.
Efficient CNN Building Blocks for Encrypted Data
Jan 30, 2021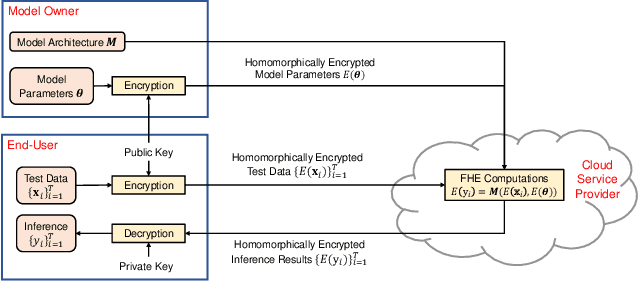

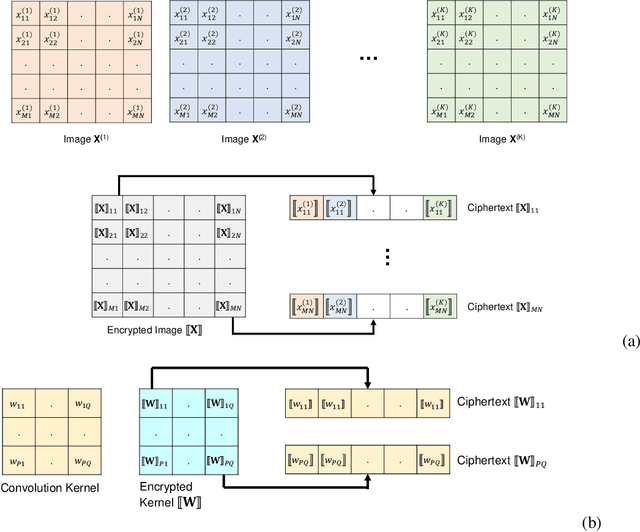
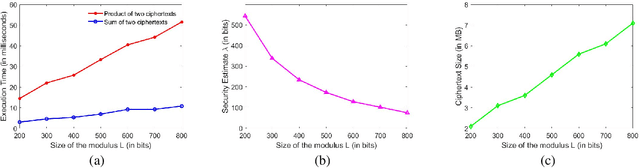
Machine learning on encrypted data can address the concerns related to privacy and legality of sharing sensitive data with untrustworthy service providers. Fully Homomorphic Encryption (FHE) is a promising technique to enable machine learning and inferencing while providing strict guarantees against information leakage. Since deep convolutional neural networks (CNNs) have become the machine learning tool of choice in several applications, several attempts have been made to harness CNNs to extract insights from encrypted data. However, existing works focus only on ensuring data security and ignore security of model parameters. They also report high level implementations without providing rigorous analysis of the accuracy, security, and speed trade-offs involved in the FHE implementation of generic primitive operators of a CNN such as convolution, non-linear activation, and pooling. In this work, we consider a Machine Learning as a Service (MLaaS) scenario where both input data and model parameters are secured using FHE. Using the CKKS scheme available in the open-source HElib library, we show that operational parameters of the chosen FHE scheme such as the degree of the cyclotomic polynomial, depth limitations of the underlying leveled HE scheme, and the computational precision parameters have a major impact on the design of the machine learning model (especially, the choice of the activation function and pooling method). Our empirical study shows that choice of aforementioned design parameters result in significant trade-offs between accuracy, security level, and computational time. Encrypted inference experiments on the MNIST dataset indicate that other design choices such as ciphertext packing strategy and parallelization using multithreading are also critical in determining the throughput and latency of the inference process.