 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHE-PEx: Efficient Machine Learning under Homomorphic Encryption using Pruning, Permutation and Expansion
Jul 07, 2022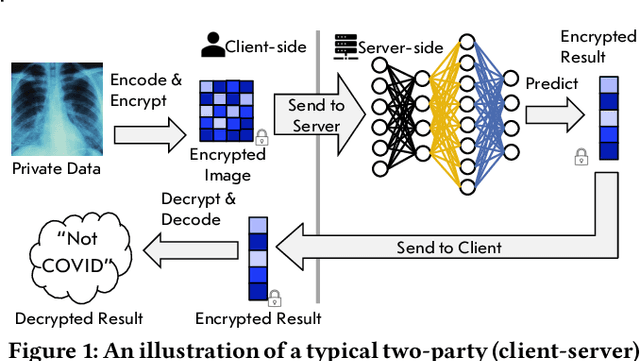

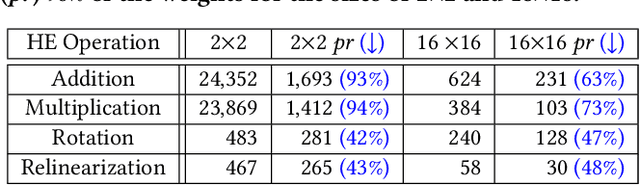
Privacy-preserving neural network (NN) inference solutions have recently gained significant traction with several solutions that provide different latency-bandwidth trade-offs. Of these, many rely on homomorphic encryption (HE), a method of performing computations over encrypted data. However, HE operations even with state-of-the-art schemes are still considerably slow compared to their plaintext counterparts. Pruning the parameters of a NN model is a well-known approach to improving inference latency. However, pruning methods that are useful in the plaintext context may lend nearly negligible improvement in the HE case, as has also been demonstrated in recent work. In this work, we propose a novel set of pruning methods that reduce the latency and memory requirement, thus bringing the effectiveness of plaintext pruning methods to HE. Crucially, our proposal employs two key techniques, viz. permutation and expansion of the packed model weights, that enable pruning significantly more ciphertexts and recuperating most of the accuracy loss, respectively. We demonstrate the advantage of our method on fully connected layers where the weights are packed using a recently proposed packing technique called tile tensors, which allows executing deep NN inference in a non-interactive mode. We evaluate our methods on various autoencoder architectures and demonstrate that for a small mean-square reconstruction loss of 1.5*10^{-5} on MNIST, we reduce the memory requirement and latency of HE-enabled inference by 60%.
Improving Efficiency in Large-Scale Decentralized Distributed Training
Feb 04, 2020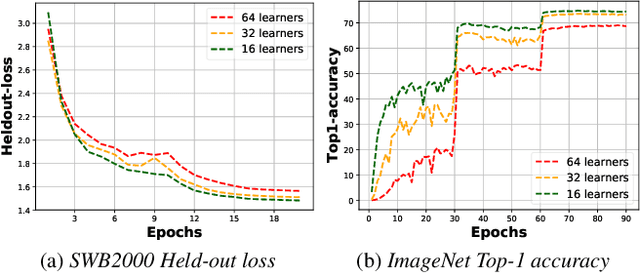
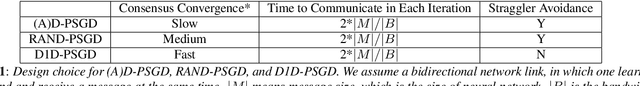
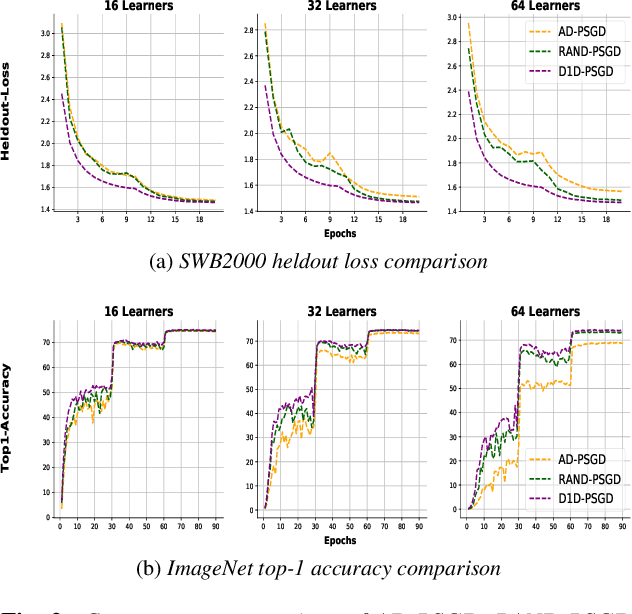

Decentralized Parallel SGD (D-PSGD) and its asynchronous variant Asynchronous Parallel SGD (AD-PSGD) is a family of distributed learning algorithms that have been demonstrated to perform well for large-scale deep learning tasks. One drawback of (A)D-PSGD is that the spectral gap of the mixing matrix decreases when the number of learners in the system increases, which hampers convergence. In this paper, we investigate techniques to accelerate (A)D-PSGD based training by improving the spectral gap while minimizing the communication cost. We demonstrate the effectiveness of our proposed techniques by running experiments on the 2000-hour Switchboard speech recognition task and the ImageNet computer vision task. On an IBM P9 supercomputer, our system is able to train an LSTM acoustic model in 2.28 hours with 7.5% WER on the Hub5-2000 Switchboard (SWB) test set and 13.3% WER on the CallHome (CH) test set using 64 V100 GPUs and in 1.98 hours with 7.7% WER on SWB and 13.3% WER on CH using 128 V100 GPUs, the fastest training time reported to date.
A Highly Efficient Distributed Deep Learning System For Automatic Speech Recognition
Jul 10, 2019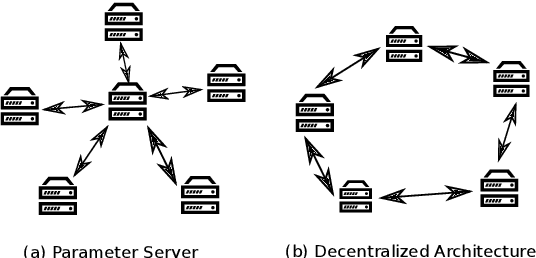

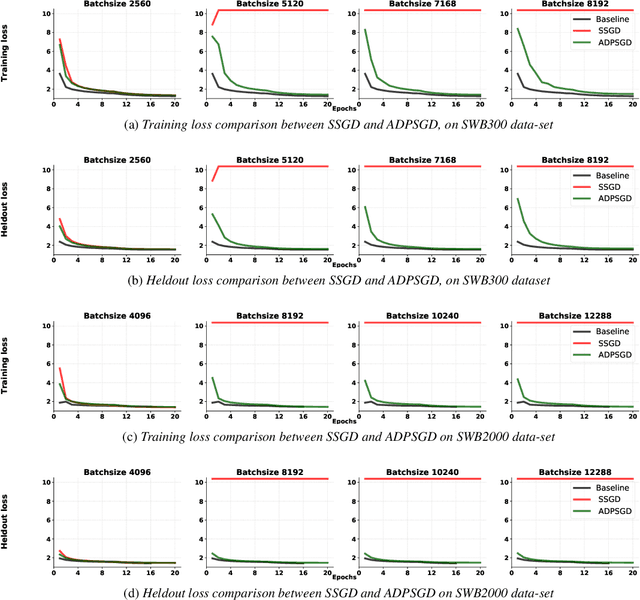
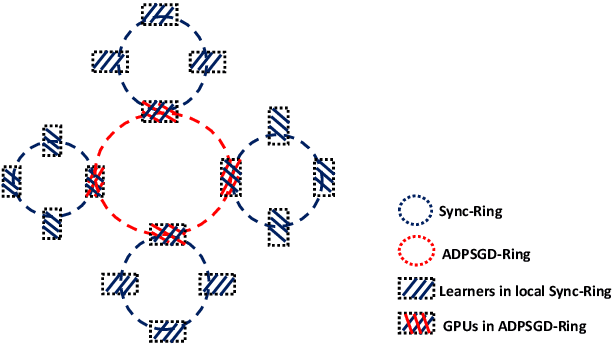
Modern Automatic Speech Recognition (ASR) systems rely on distributed deep learning to for quick training completion. To enable efficient distributed training, it is imperative that the training algorithms can converge with a large mini-batch size. In this work, we discovered that Asynchronous Decentralized Parallel Stochastic Gradient Descent (ADPSGD) can work with much larger batch size than commonly used Synchronous SGD (SSGD) algorithm. On commonly used public SWB-300 and SWB-2000 ASR datasets, ADPSGD can converge with a batch size 3X as large as the one used in SSGD, thus enable training at a much larger scale. Further, we proposed a Hierarchical-ADPSGD (H-ADPSGD) system in which learners on the same computing node construct a super learner via a fast allreduce implementation, and super learners deploy ADPSGD algorithm among themselves. On a 64 Nvidia V100 GPU cluster connected via a 100Gb/s Ethernet network, our system is able to train SWB-2000 to reach a 7.6% WER on the Hub5-2000 Switchboard (SWB) test-set and a 13.2% WER on the Call-home (CH) test-set in 5.2 hours. To the best of our knowledge, this is the fastest ASR training system that attains this level of model accuracy for SWB-2000 task to be ever reported in the literature.