 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Customization of LLMs for Enterprise Code Repositories Using Semantic Scopes
Feb 05, 2026Code completion (CC) is a task frequently used by developers when working in collaboration with LLM-based programming assistants. Despite the increased performance of LLMs on public benchmarks, out of the box LLMs still have a hard time generating code that aligns with a private code repository not previously seen by the model's training data. Customizing code LLMs to a private repository provides a way to improve the model performance. In this paper we present our approach for automated LLM customization based on semantic scopes in the code. We evaluate LLMs on real industry cases with two private enterprise code repositories with two customization strategies: Retrieval-Augmented Generation (RAG) and supervised Fine-Tuning (FT). Our mechanism for ingesting the repository's data and formulating the training data pairs with semantic scopes helps models to learn the underlying patterns specific to the repository, providing more precise code to developers and helping to boost their productivity. The code completions of moderately sized customized models can be significantly better than those of uncustomized models of much larger capacity. We also include an analysis of customization on two public benchmarks and present opportunities for future work.
Asynchronous Decentralized Distributed Training of Acoustic Models
Oct 21, 2021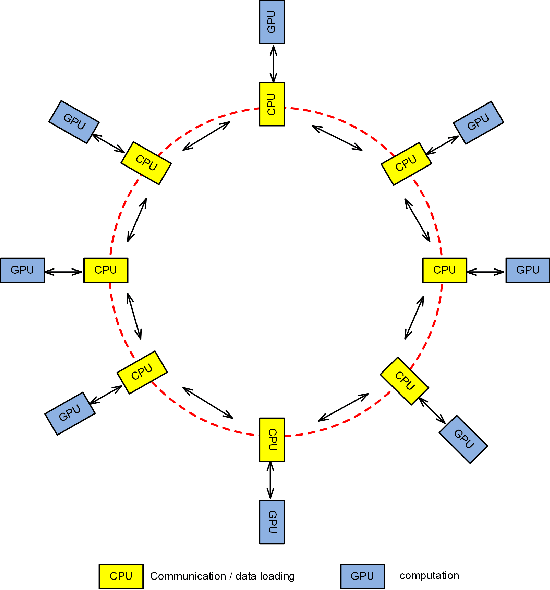
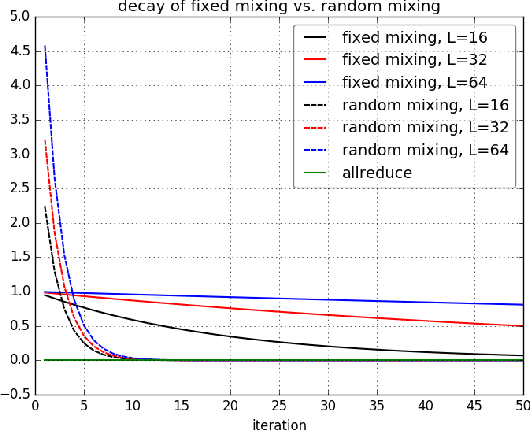
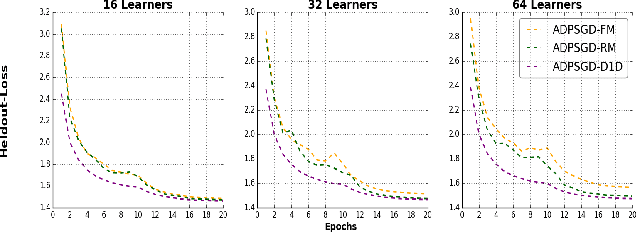
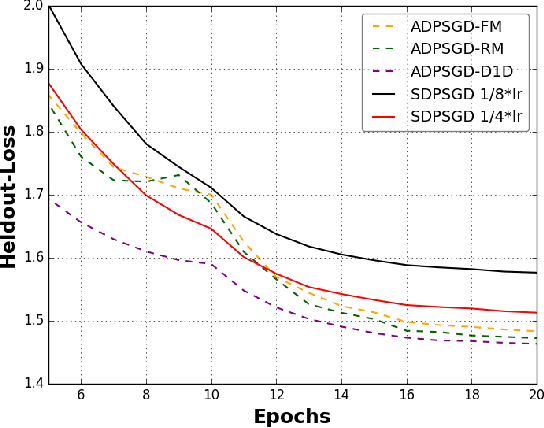
Large-scale distributed training of deep acoustic models plays an important role in today's high-performance automatic speech recognition (ASR). In this paper we investigate a variety of asynchronous decentralized distributed training strategies based on data parallel stochastic gradient descent (SGD) to show their superior performance over the commonly-used synchronous distributed training via allreduce, especially when dealing with large batch sizes. Specifically, we study three variants of asynchronous decentralized parallel SGD (ADPSGD), namely, fixed and randomized communication patterns on a ring as well as a delay-by-one scheme. We introduce a mathematical model of ADPSGD, give its theoretical convergence rate, and compare the empirical convergence behavior and straggler resilience properties of the three variants. Experiments are carried out on an IBM supercomputer for training deep long short-term memory (LSTM) acoustic models on the 2000-hour Switchboard dataset. Recognition and speedup performance of the proposed strategies are evaluated under various training configurations. We show that ADPSGD with fixed and randomized communication patterns cope well with slow learners. When learners are equally fast, ADPSGD with the delay-by-one strategy has the fastest convergence with large batches. In particular, using the delay-by-one strategy, we can train the acoustic model in less than 2 hours using 128 V100 GPUs with competitive word error rates.
Project CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks
May 25, 2021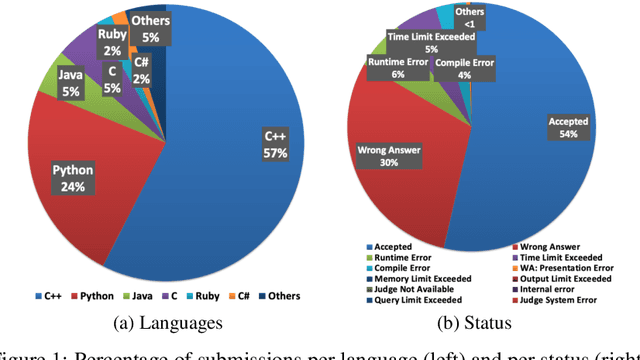
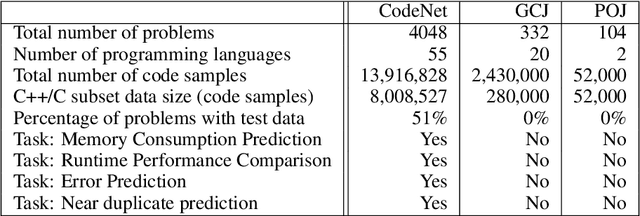
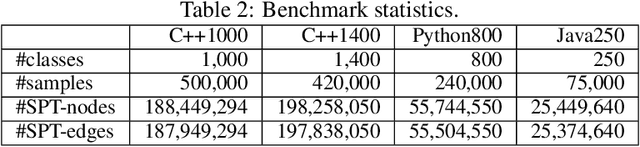
Advancements in deep learning and machine learning algorithms have enabled breakthrough progress in computer vision, speech recognition, natural language processing and beyond. In addition, over the last several decades, software has been built into the fabric of every aspect of our society. Together, these two trends have generated new interest in the fast-emerging research area of AI for Code. As software development becomes ubiquitous across all industries and code infrastructure of enterprise legacy applications ages, it is more critical than ever to increase software development productivity and modernize legacy applications. Over the last decade, datasets like ImageNet, with its large scale and diversity, have played a pivotal role in algorithmic advancements from computer vision to language and speech understanding. In this paper, we present Project CodeNet, a first-of-its-kind, very large scale, diverse, and high-quality dataset to accelerate the algorithmic advancements in AI for Code. It consists of 14M code samples and about 500M lines of code in 55 different programming languages. Project CodeNet is not only unique in its scale, but also in the diversity of coding tasks it can help benchmark: from code similarity and classification for advances in code recommendation algorithms, and code translation between a large variety programming languages, to advances in code performance (both runtime, and memory) improvement techniques. CodeNet also provides sample input and output test sets for over 7M code samples, which can be critical for determining code equivalence in different languages. As a usability feature, we provide several preprocessing tools in Project CodeNet to transform source codes into representations that can be readily used as inputs into machine learning models.
Large Scale Neural Architecture Search with Polyharmonic Splines
Nov 20, 2020
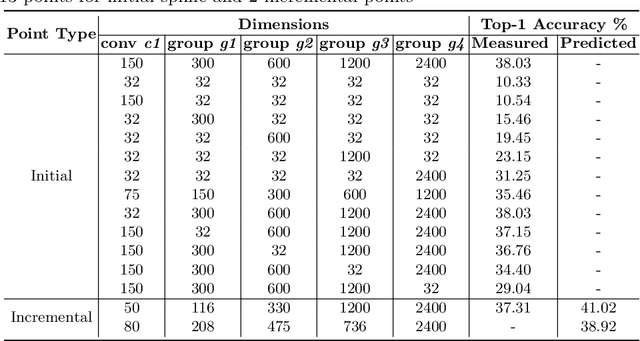
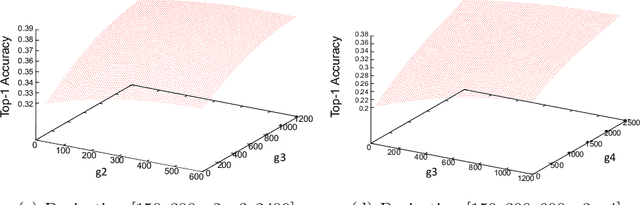
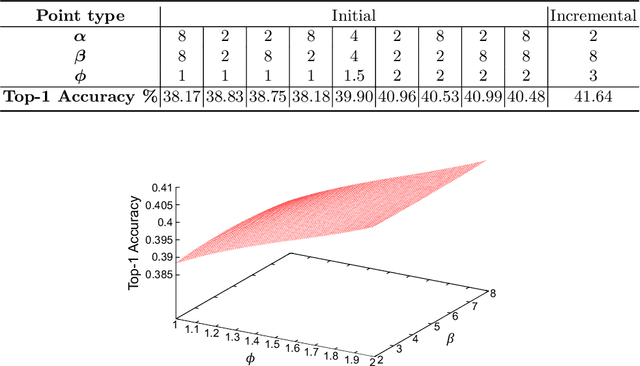
Neural Architecture Search (NAS) is a powerful tool to automatically design deep neural networks for many tasks, including image classification. Due to the significant computational burden of the search phase, most NAS methods have focused so far on small, balanced datasets. All attempts at conducting NAS at large scale have employed small proxy sets, and then transferred the learned architectures to larger datasets by replicating or stacking the searched cells. We propose a NAS method based on polyharmonic splines that can perform search directly on large scale, imbalanced target datasets. We demonstrate the effectiveness of our method on the ImageNet22K benchmark[16], which contains 14 million images distributed in a highly imbalanced manner over 21,841 categories. By exploring the search space of the ResNet [23] and Big-Little Net ResNext [11] architectures directly on ImageNet22K, our polyharmonic splines NAS method designed a model which achieved a top-1 accuracy of 40.03% on ImageNet22K, an absolute improvement of 3.13% over the state of the art with similar global batch size [15].
NASTransfer: Analyzing Architecture Transferability in Large Scale Neural Architecture Search
Jun 23, 2020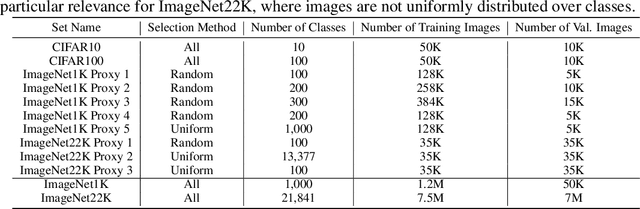
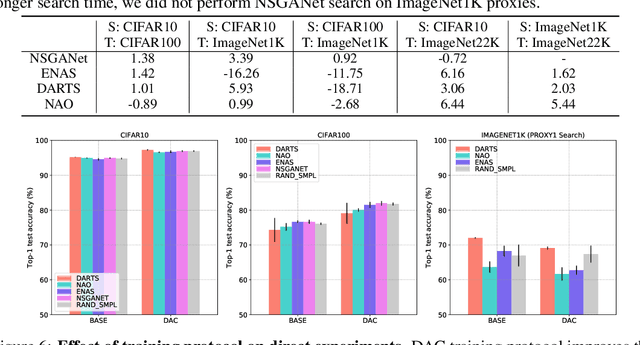
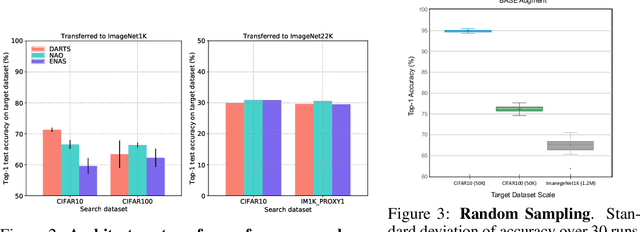
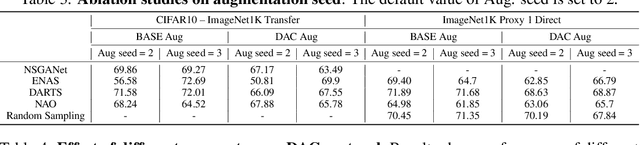
Neural Architecture Search (NAS) is an open and challenging problem in machine learning. While NAS offers great promise, the prohibitive computational demand of most of the existing NAS methods makes it difficult to directly search the architectures on large-scale tasks. The typical way of conducting large scale NAS is to search for an architectural building block on a small dataset (either using a proxy set from the large dataset or a completely different small scale dataset) and then transfer the block to a larger dataset. Despite a number of recent results that show the promise of transfer from proxy datasets, a comprehensive evaluation of different NAS methods studying the impact of different source datasets and training protocols has not yet been addressed. In this work, we propose to analyze the architecture transferability of different NAS methods by performing a series of experiments on large scale benchmarks such as ImageNet1K and ImageNet22K. We find that: (i) On average, transfer performance of architectures searched using completely different small datasets perform similarly to the architectures searched directly on proxy target datasets. However, design of proxy sets has considerable impact on rankings of different NAS methods. (ii) While the different NAS methods show similar performance on a source dataset (e.g., CIFAR10), they significantly differ on the transfer performance to a large dataset (e.g., ImageNet1K). (iii) Even on large datasets, the randomly sampled architecture baseline is very competitive and significantly outperforms many representative NAS methods. (iv) The training protocol has a larger impact on small datasets, but it fails to provide consistent improvements on large datasets. We believe that our NASTransfer benchmark will be key to designing future NAS strategies that consistently show superior transfer performance on large scale datasets.
Map Generation from Large Scale Incomplete and Inaccurate Data Labels
May 20, 2020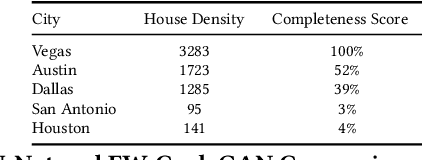
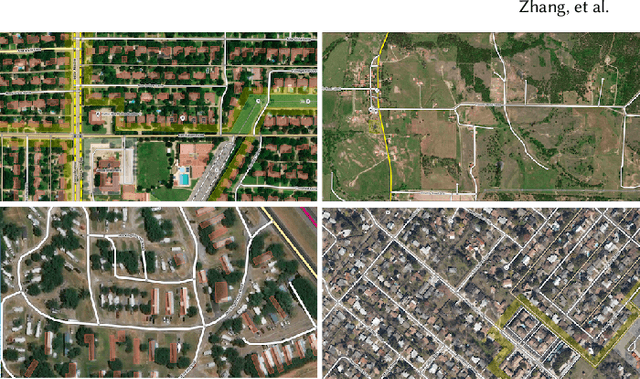

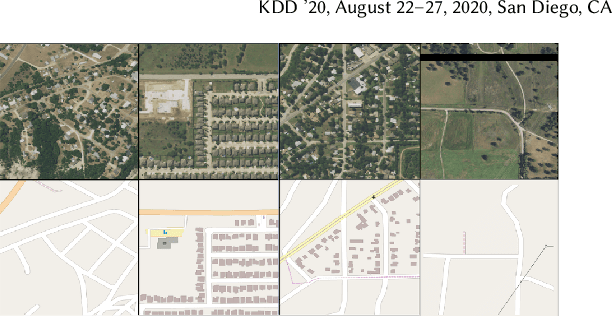
Accurately and globally mapping human infrastructure is an important and challenging task with applications in routing, regulation compliance monitoring, and natural disaster response management etc.. In this paper we present progress in developing an algorithmic pipeline and distributed compute system that automates the process of map creation using high resolution aerial images. Unlike previous studies, most of which use datasets that are available only in a few cities across the world, we utilizes publicly available imagery and map data, both of which cover the contiguous United States (CONUS). We approach the technical challenge of inaccurate and incomplete training data adopting state-of-the-art convolutional neural network architectures such as the U-Net and the CycleGAN to incrementally generate maps with increasingly more accurate and more complete labels of man-made infrastructure such as roads and houses. Since scaling the mapping task to CONUS calls for parallelization, we then adopted an asynchronous distributed stochastic parallel gradient descent training scheme to distribute the computational workload onto a cluster of GPUs with nearly linear speed-up.
Distributed Training of Deep Neural Network Acoustic Models for Automatic Speech Recognition
Feb 24, 2020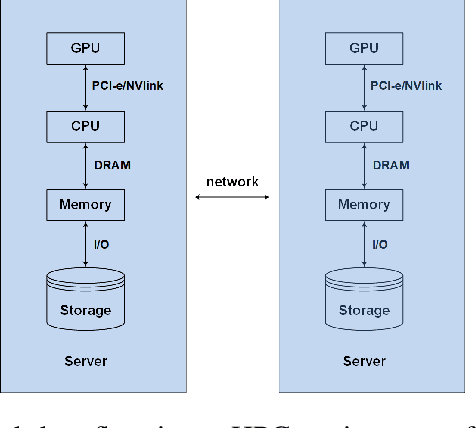
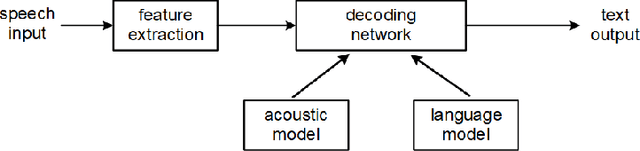
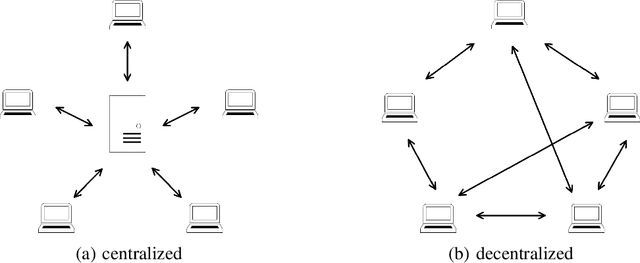
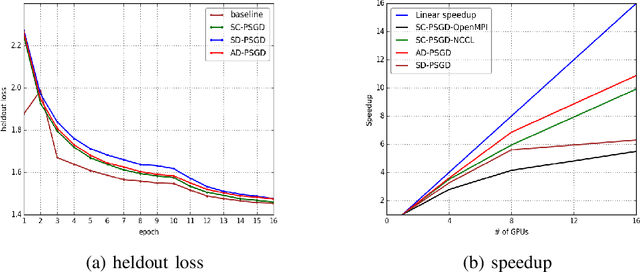
The past decade has witnessed great progress in Automatic Speech Recognition (ASR) due to advances in deep learning. The improvements in performance can be attributed to both improved models and large-scale training data. Key to training such models is the employment of efficient distributed learning techniques. In this article, we provide an overview of distributed training techniques for deep neural network acoustic models for ASR. Starting with the fundamentals of data parallel stochastic gradient descent (SGD) and ASR acoustic modeling, we will investigate various distributed training strategies and their realizations in high performance computing (HPC) environments with an emphasis on striking the balance between communication and computation. Experiments are carried out on a popular public benchmark to study the convergence, speedup and recognition performance of the investigated strategies.
Improving Efficiency in Large-Scale Decentralized Distributed Training
Feb 04, 2020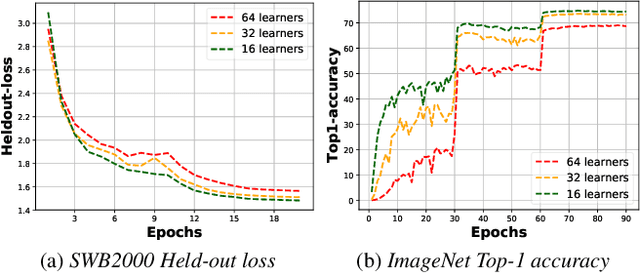
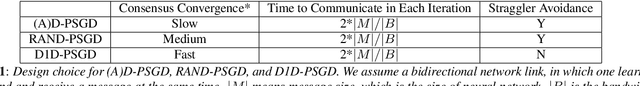
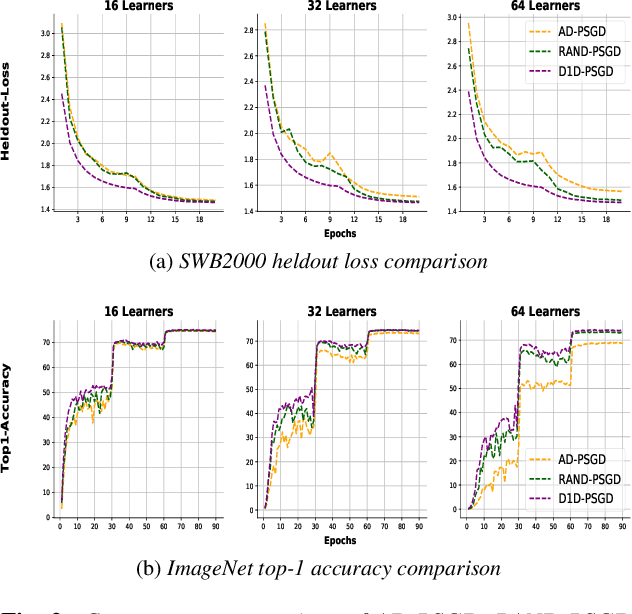

Decentralized Parallel SGD (D-PSGD) and its asynchronous variant Asynchronous Parallel SGD (AD-PSGD) is a family of distributed learning algorithms that have been demonstrated to perform well for large-scale deep learning tasks. One drawback of (A)D-PSGD is that the spectral gap of the mixing matrix decreases when the number of learners in the system increases, which hampers convergence. In this paper, we investigate techniques to accelerate (A)D-PSGD based training by improving the spectral gap while minimizing the communication cost. We demonstrate the effectiveness of our proposed techniques by running experiments on the 2000-hour Switchboard speech recognition task and the ImageNet computer vision task. On an IBM P9 supercomputer, our system is able to train an LSTM acoustic model in 2.28 hours with 7.5% WER on the Hub5-2000 Switchboard (SWB) test set and 13.3% WER on the CallHome (CH) test set using 64 V100 GPUs and in 1.98 hours with 7.7% WER on SWB and 13.3% WER on CH using 128 V100 GPUs, the fastest training time reported to date.
A Highly Efficient Distributed Deep Learning System For Automatic Speech Recognition
Jul 10, 2019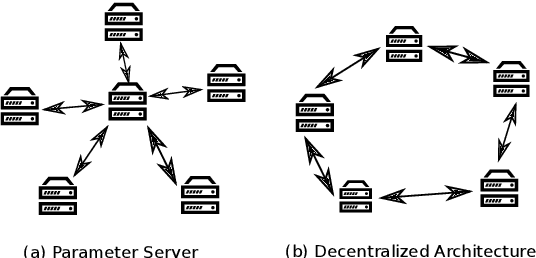

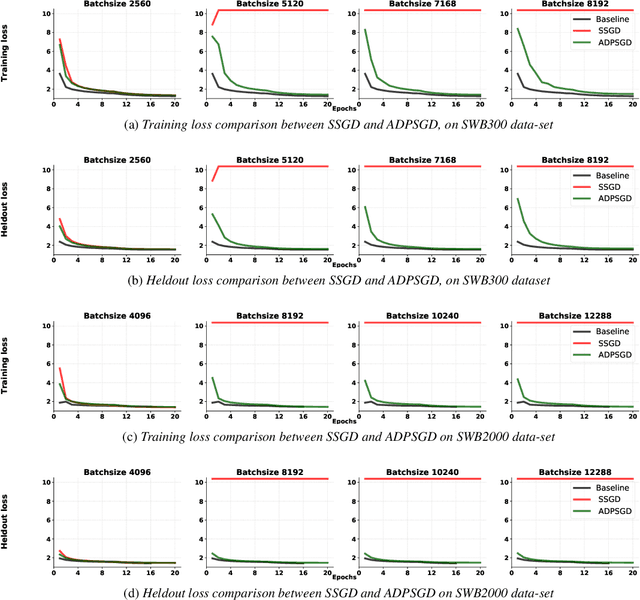
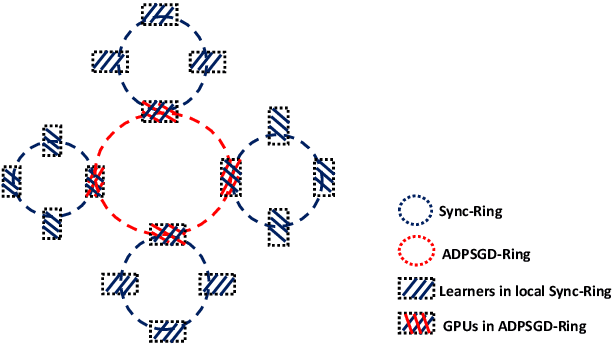
Modern Automatic Speech Recognition (ASR) systems rely on distributed deep learning to for quick training completion. To enable efficient distributed training, it is imperative that the training algorithms can converge with a large mini-batch size. In this work, we discovered that Asynchronous Decentralized Parallel Stochastic Gradient Descent (ADPSGD) can work with much larger batch size than commonly used Synchronous SGD (SSGD) algorithm. On commonly used public SWB-300 and SWB-2000 ASR datasets, ADPSGD can converge with a batch size 3X as large as the one used in SSGD, thus enable training at a much larger scale. Further, we proposed a Hierarchical-ADPSGD (H-ADPSGD) system in which learners on the same computing node construct a super learner via a fast allreduce implementation, and super learners deploy ADPSGD algorithm among themselves. On a 64 Nvidia V100 GPU cluster connected via a 100Gb/s Ethernet network, our system is able to train SWB-2000 to reach a 7.6% WER on the Hub5-2000 Switchboard (SWB) test-set and a 13.2% WER on the Call-home (CH) test-set in 5.2 hours. To the best of our knowledge, this is the fastest ASR training system that attains this level of model accuracy for SWB-2000 task to be ever reported in the literature.
Distributed Deep Learning Strategies For Automatic Speech Recognition
Apr 10, 2019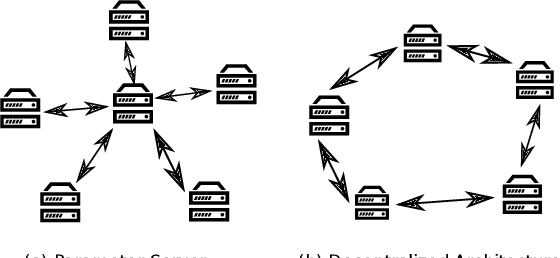
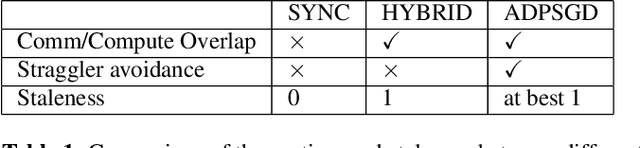
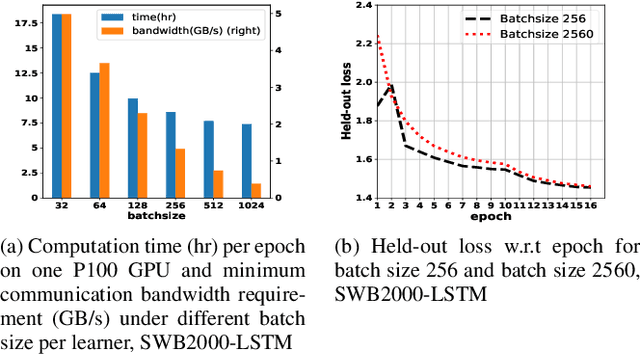
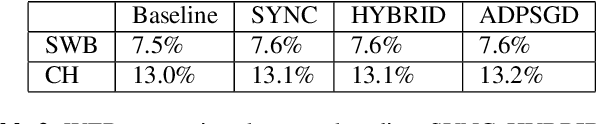
In this paper, we propose and investigate a variety of distributed deep learning strategies for automatic speech recognition (ASR) and evaluate them with a state-of-the-art Long short-term memory (LSTM) acoustic model on the 2000-hour Switchboard (SWB2000), which is one of the most widely used datasets for ASR performance benchmark. We first investigate what are the proper hyper-parameters (e.g., learning rate) to enable the training with sufficiently large batch size without impairing the model accuracy. We then implement various distributed strategies, including Synchronous (SYNC), Asynchronous Decentralized Parallel SGD (ADPSGD) and the hybrid of the two HYBRID, to study their runtime/accuracy trade-off. We show that we can train the LSTM model using ADPSGD in 14 hours with 16 NVIDIA P100 GPUs to reach a 7.6% WER on the Hub5- 2000 Switchboard (SWB) test set and a 13.1% WER on the CallHome (CH) test set. Furthermore, we can train the model using HYBRID in 11.5 hours with 32 NVIDIA V100 GPUs without loss in accuracy.