 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftware Vulnerability Detection via Deep Learning over Disaggregated Code Graph Representation
Sep 07, 2021
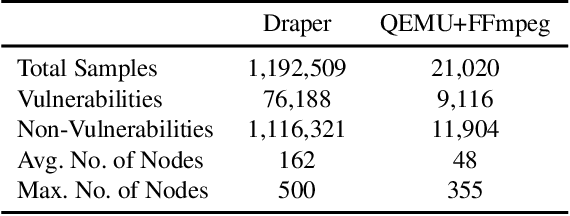
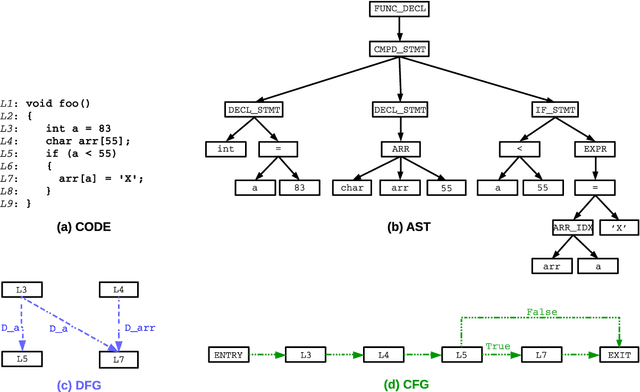
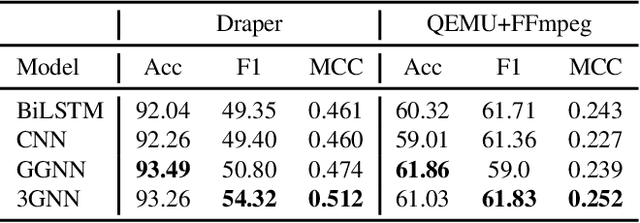
Identifying vulnerable code is a precautionary measure to counter software security breaches. Tedious expert effort has been spent to build static analyzers, yet insecure patterns are barely fully enumerated. This work explores a deep learning approach to automatically learn the insecure patterns from code corpora. Because code naturally admits graph structures with parsing, we develop a novel graph neural network (GNN) to exploit both the semantic context and structural regularity of a program, in order to improve prediction performance. Compared with a generic GNN, our enhancements include a synthesis of multiple representations learned from the several parsed graphs of a program, and a new training loss metric that leverages the fine granularity of labeling. Our model outperforms multiple text, image and graph-based approaches, across two real-world datasets.
Project CodeNet: A Large-Scale AI for Code Dataset for Learning a Diversity of Coding Tasks
May 25, 2021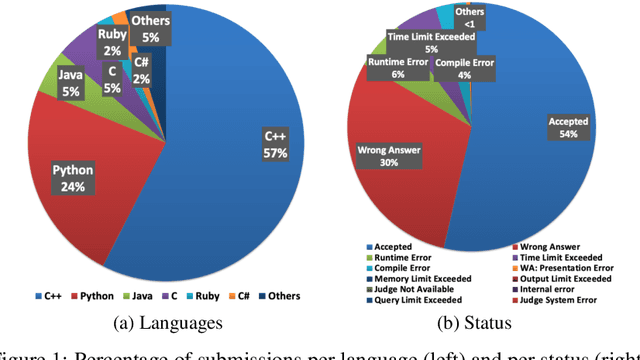
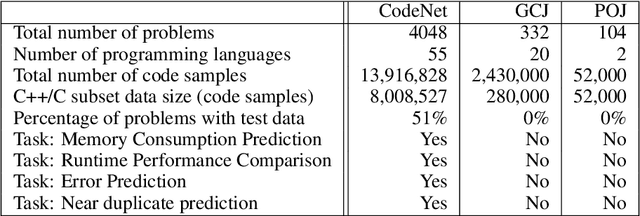
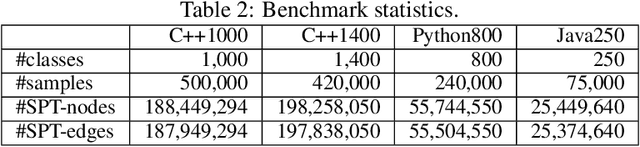
Advancements in deep learning and machine learning algorithms have enabled breakthrough progress in computer vision, speech recognition, natural language processing and beyond. In addition, over the last several decades, software has been built into the fabric of every aspect of our society. Together, these two trends have generated new interest in the fast-emerging research area of AI for Code. As software development becomes ubiquitous across all industries and code infrastructure of enterprise legacy applications ages, it is more critical than ever to increase software development productivity and modernize legacy applications. Over the last decade, datasets like ImageNet, with its large scale and diversity, have played a pivotal role in algorithmic advancements from computer vision to language and speech understanding. In this paper, we present Project CodeNet, a first-of-its-kind, very large scale, diverse, and high-quality dataset to accelerate the algorithmic advancements in AI for Code. It consists of 14M code samples and about 500M lines of code in 55 different programming languages. Project CodeNet is not only unique in its scale, but also in the diversity of coding tasks it can help benchmark: from code similarity and classification for advances in code recommendation algorithms, and code translation between a large variety programming languages, to advances in code performance (both runtime, and memory) improvement techniques. CodeNet also provides sample input and output test sets for over 7M code samples, which can be critical for determining code equivalence in different languages. As a usability feature, we provide several preprocessing tools in Project CodeNet to transform source codes into representations that can be readily used as inputs into machine learning models.
CASTELO: Clustered Atom Subtypes aidEd Lead Optimization -- a combined machine learning and molecular modeling method
Nov 27, 2020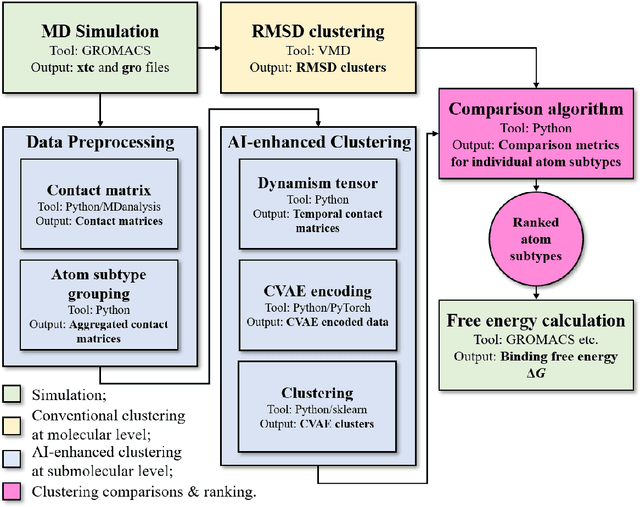

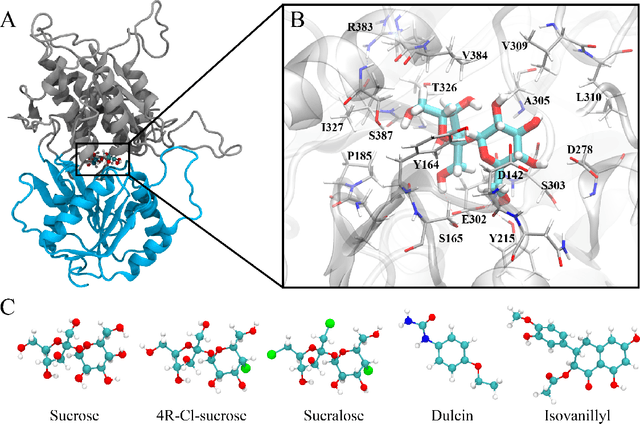
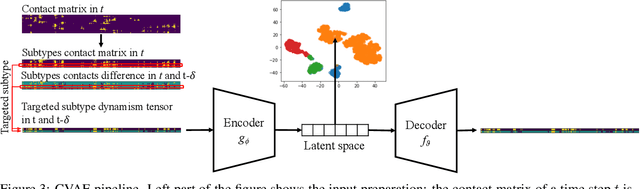
Drug discovery is a multi-stage process that comprises two costly major steps: pre-clinical research and clinical trials. Among its stages, lead optimization easily consumes more than half of the pre-clinical budget. We propose a combined machine learning and molecular modeling approach that automates lead optimization workflow \textit{in silico}. The initial data collection is achieved with physics-based molecular dynamics (MD) simulation. Contact matrices are calculated as the preliminary features extracted from the simulations. To take advantage of the temporal information from the simulations, we enhanced contact matrices data with temporal dynamism representation, which are then modeled with unsupervised convolutional variational autoencoder (CVAE). Finally, conventional clustering method and CVAE-based clustering method are compared with metrics to rank the submolecular structures and propose potential candidates for lead optimization. With no need for extensive structure-activity relationship database, our method provides new hints for drug modification hotspots which can be used to improve drug efficacy. Our workflow can potentially reduce the lead optimization turnaround time from months/years to days compared with the conventional labor-intensive process and thus can potentially become a valuable tool for medical researchers.
Exploring Software Naturalness through Neural Language Models
Jun 24, 2020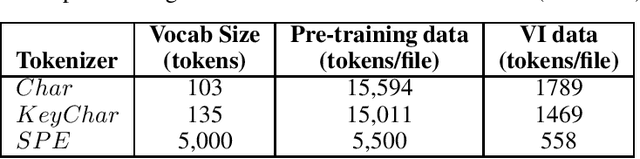
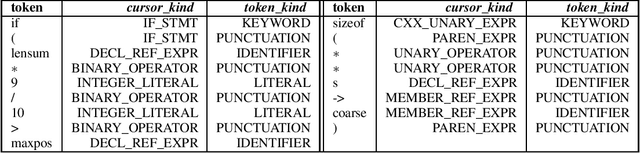
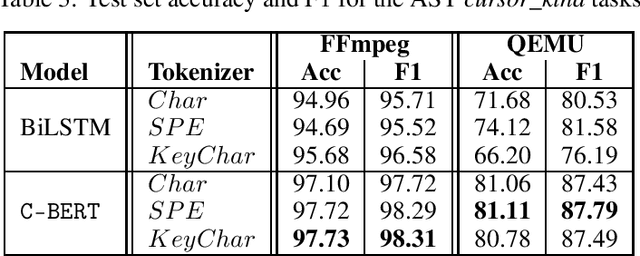
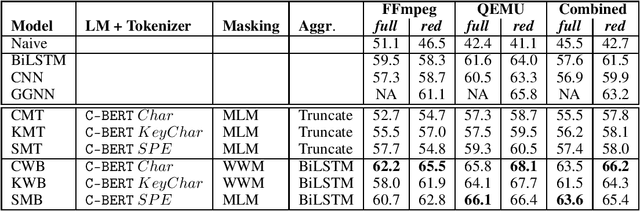
The Software Naturalness hypothesis argues that programming languages can be understood through the same techniques used in natural language processing. We explore this hypothesis through the use of a pre-trained transformer-based language model to perform code analysis tasks. Present approaches to code analysis depend heavily on features derived from the Abstract Syntax Tree (AST) while our transformer-based language models work on raw source code. This work is the first to investigate whether such language models can discover AST features automatically. To achieve this, we introduce a sequence labeling task that directly probes the language models understanding of AST. Our results show that transformer based language models achieve high accuracy in the AST tagging task. Furthermore, we evaluate our model on a software vulnerability identification task. Importantly, we show that our approach obtains vulnerability identification results comparable to graph based approaches that rely heavily on compilers for feature extraction.
Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics
Jul 31, 2019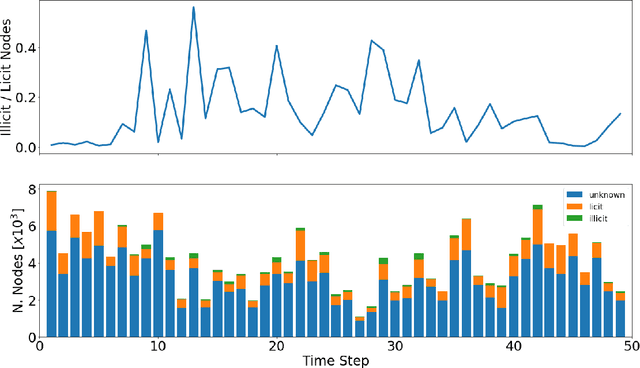
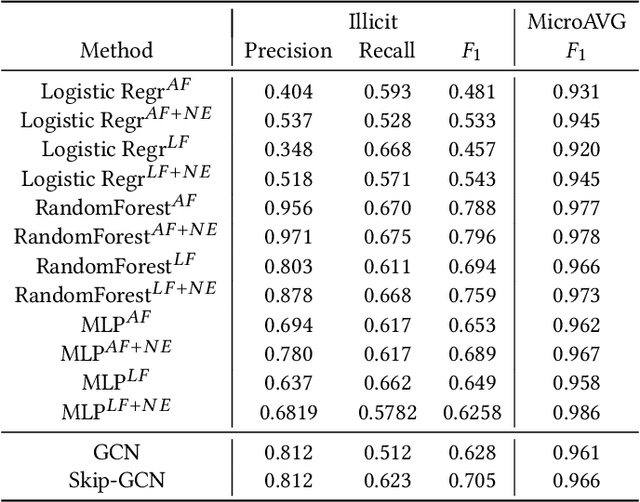
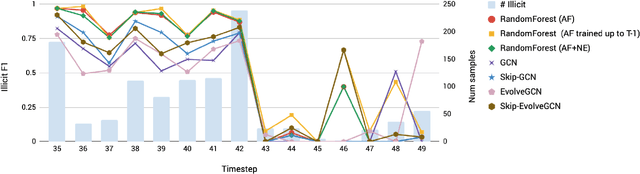

Anti-money laundering (AML) regulations play a critical role in safeguarding financial systems, but bear high costs for institutions and drive financial exclusion for those on the socioeconomic and international margins. The advent of cryptocurrency has introduced an intriguing paradox: pseudonymity allows criminals to hide in plain sight, but open data gives more power to investigators and enables the crowdsourcing of forensic analysis. Meanwhile advances in learning algorithms show great promise for the AML toolkit. In this workshop tutorial, we motivate the opportunity to reconcile the cause of safety with that of financial inclusion. We contribute the Elliptic Data Set, a time series graph of over 200K Bitcoin transactions (nodes), 234K directed payment flows (edges), and 166 node features, including ones based on non-public data; to our knowledge, this is the largest labelled transaction data set publicly available in any cryptocurrency. We share results from a binary classification task predicting illicit transactions using variations of Logistic Regression (LR), Random Forest (RF), Multilayer Perceptrons (MLP), and Graph Convolutional Networks (GCN), with GCN being of special interest as an emergent new method for capturing relational information. The results show the superiority of Random Forest (RF), but also invite algorithmic work to combine the respective powers of RF and graph methods. Lastly, we consider visualization for analysis and explainability, which is difficult given the size and dynamism of real-world transaction graphs, and we offer a simple prototype capable of navigating the graph and observing model performance on illicit activity over time. With this tutorial and data set, we hope to a) invite feedback in support of our ongoing inquiry, and b) inspire others to work on this societally important challenge.
EvolveGCN: Evolving Graph Convolutional Networks for Dynamic Graphs
Feb 26, 2019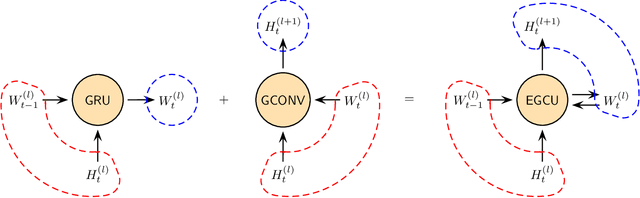
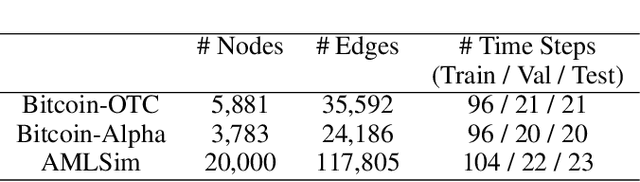

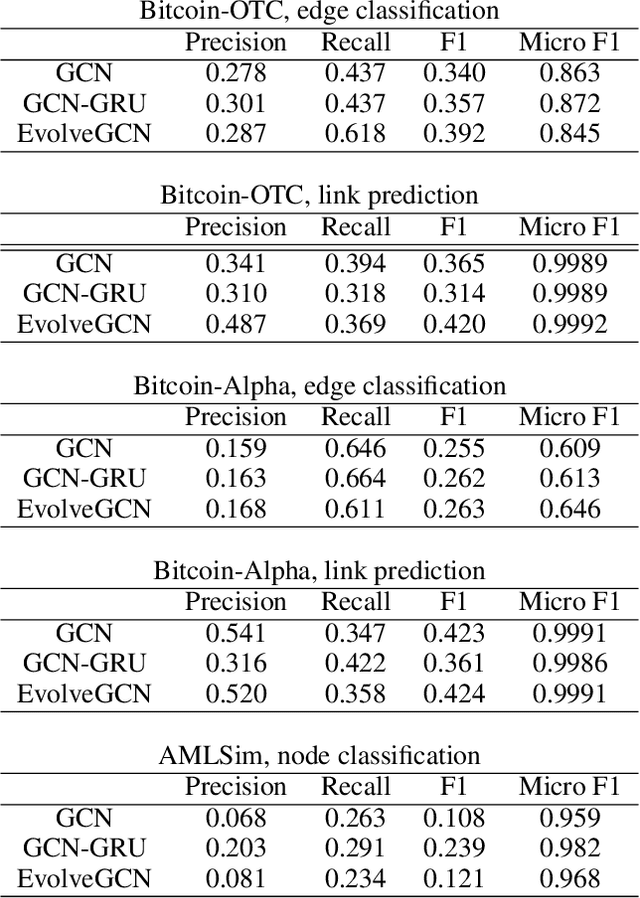
Graph representation learning resurges as a trending research subject owing to the widespread use of deep learning for Euclidean data, which inspire various creative designs of neural networks in the non-Euclidean domain, particularly graphs. With the success of these graph neural networks (GNN) in the static setting, we approach further practical scenarios where the graph dynamically evolves. For this case, combining the GNN with a recurrent neural network (RNN, broadly speaking) is a natural idea. Existing approaches typically learn one single graph model for all the graphs, by using the RNN to capture the dynamism of the output node embeddings and to implicitly regulate the graph model. In this work, we propose a different approach, coined EvolveGCN, that uses the RNN to evolve the graph model itself over time. This model adaptation approach is model oriented rather than node oriented, and hence is advantageous in the flexibility on the input. For example, in the extreme case, the model can handle at a new time step, a completely new set of nodes whose historical information is unknown, because the dynamism has been carried over to the GNN parameters. We evaluate the proposed approach on tasks including node classification, edge classification, and link prediction. The experimental results indicate a generally higher performance of EvolveGCN compared with related approaches.