 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLessons Learned: A Multi-Agent Framework for Code LLMs to Learn and Improve
May 29, 2025Recent studies show that LLMs possess different skills and specialize in different tasks. In fact, we observe that their varied performance occur in several levels of granularity. For example, in the code optimization task, code LLMs excel at different optimization categories and no one dominates others. This observation prompts the question of how one leverages multiple LLM agents to solve a coding problem without knowing their complementary strengths a priori. We argue that a team of agents can learn from each other's successes and failures so as to improve their own performance. Thus, a lesson is the knowledge produced by an agent and passed on to other agents in the collective solution process. We propose a lesson-based collaboration framework, design the lesson solicitation--banking--selection mechanism, and demonstrate that a team of small LLMs with lessons learned can outperform a much larger LLM and other multi-LLM collaboration methods.
The Shape of Money Laundering: Subgraph Representation Learning on the Blockchain with the Elliptic2 Dataset
May 01, 2024



Subgraph representation learning is a technique for analyzing local structures (or shapes) within complex networks. Enabled by recent developments in scalable Graph Neural Networks (GNNs), this approach encodes relational information at a subgroup level (multiple connected nodes) rather than at a node level of abstraction. We posit that certain domain applications, such as anti-money laundering (AML), are inherently subgraph problems and mainstream graph techniques have been operating at a suboptimal level of abstraction. This is due in part to the scarcity of annotated datasets of real-world size and complexity, as well as the lack of software tools for managing subgraph GNN workflows at scale. To enable work in fundamental algorithms as well as domain applications in AML and beyond, we introduce Elliptic2, a large graph dataset containing 122K labeled subgraphs of Bitcoin clusters within a background graph consisting of 49M node clusters and 196M edge transactions. The dataset provides subgraphs known to be linked to illicit activity for learning the set of "shapes" that money laundering exhibits in cryptocurrency and accurately classifying new criminal activity. Along with the dataset we share our graph techniques, software tooling, promising early experimental results, and new domain insights already gleaned from this approach. Taken together, we find immediate practical value in this approach and the potential for a new standard in anti-money laundering and forensic analytics in cryptocurrencies and other financial networks.
Communication-Efficient Graph Neural Networks with Probabilistic Neighborhood Expansion Analysis and Caching
May 04, 2023Training and inference with graph neural networks (GNNs) on massive graphs has been actively studied since the inception of GNNs, owing to the widespread use and success of GNNs in applications such as recommendation systems and financial forensics. This paper is concerned with minibatch training and inference with GNNs that employ node-wise sampling in distributed settings, where the necessary partitioning of vertex features across distributed storage causes feature communication to become a major bottleneck that hampers scalability. To significantly reduce the communication volume without compromising prediction accuracy, we propose a policy for caching data associated with frequently accessed vertices in remote partitions. The proposed policy is based on an analysis of vertex-wise inclusion probabilities (VIP) during multi-hop neighborhood sampling, which may expand the neighborhood far beyond the partition boundaries of the graph. VIP analysis not only enables the elimination of the communication bottleneck, but it also offers a means to organize in-memory data by prioritizing GPU storage for the most frequently accessed vertex features. We present SALIENT++, which extends the prior state-of-the-art SALIENT system to work with partitioned feature data and leverages the VIP-driven caching policy. SALIENT++ retains the local training efficiency and scalability of SALIENT by using a deep pipeline and drastically reducing communication volume while consuming only a fraction of the storage required by SALIENT. We provide experimental results with the Open Graph Benchmark data sets and demonstrate that training a 3-layer GraphSAGE model with SALIENT++ on 8 single-GPU machines is 7.1 faster than with SALIENT on 1 single-GPU machine, and 12.7 faster than with DistDGL on 8 single-GPU machines.
Accelerating Training and Inference of Graph Neural Networks with Fast Sampling and Pipelining
Oct 16, 2021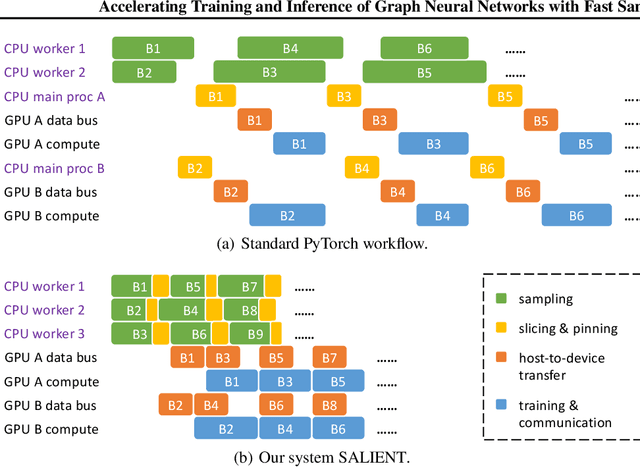
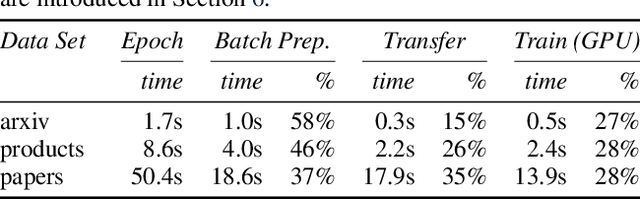
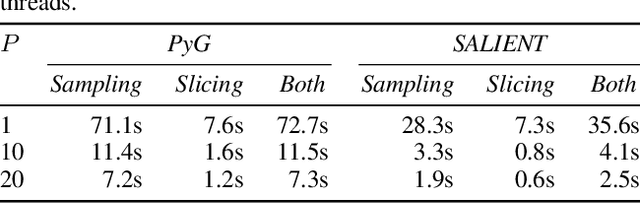
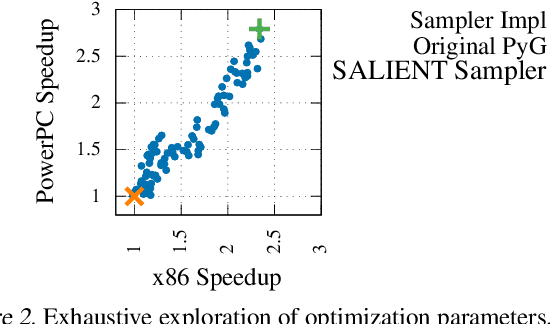
Improving the training and inference performance of graph neural networks (GNNs) is faced with a challenge uncommon in general neural networks: creating mini-batches requires a lot of computation and data movement due to the exponential growth of multi-hop graph neighborhoods along network layers. Such a unique challenge gives rise to a diverse set of system design choices. We argue in favor of performing mini-batch training with neighborhood sampling in a distributed multi-GPU environment, under which we identify major performance bottlenecks hitherto under-explored by developers: mini-batch preparation and transfer. We present a sequence of improvements to mitigate these bottlenecks, including a performance-engineered neighborhood sampler, a shared-memory parallelization strategy, and the pipelining of batch transfer with GPU computation. We also conduct an empirical analysis that supports the use of sampling for inference, showing that test accuracies are not materially compromised. Such an observation unifies training and inference, simplifying model implementation. We report comprehensive experimental results with several benchmark data sets and GNN architectures, including a demonstration that, for the ogbn-papers100M data set, our system SALIENT achieves a speedup of 3x over a standard PyTorch-Geometric implementation with a single GPU and a further 8x parallel speedup with 16 GPUs. Therein, training a 3-layer GraphSAGE model with sampling fanout (15, 10, 5) takes 2.0 seconds per epoch and inference with fanout (20, 20, 20) takes 2.4 seconds, attaining test accuracy 64.58%.
Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics
Jul 31, 2019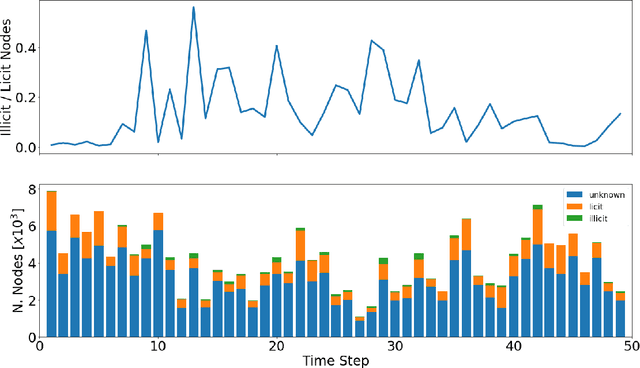
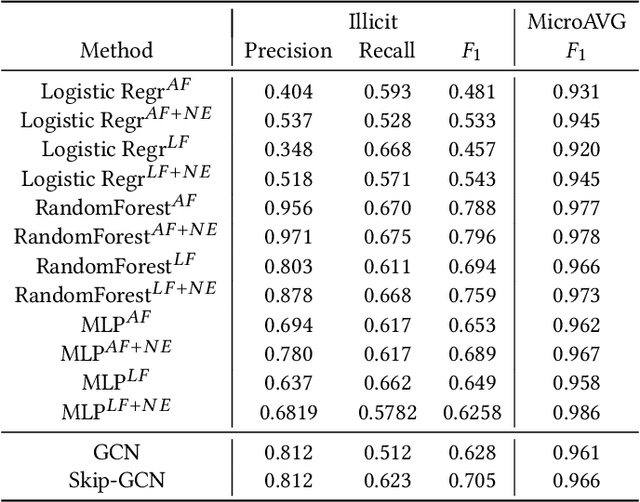
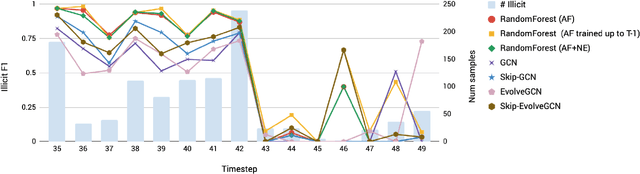

Anti-money laundering (AML) regulations play a critical role in safeguarding financial systems, but bear high costs for institutions and drive financial exclusion for those on the socioeconomic and international margins. The advent of cryptocurrency has introduced an intriguing paradox: pseudonymity allows criminals to hide in plain sight, but open data gives more power to investigators and enables the crowdsourcing of forensic analysis. Meanwhile advances in learning algorithms show great promise for the AML toolkit. In this workshop tutorial, we motivate the opportunity to reconcile the cause of safety with that of financial inclusion. We contribute the Elliptic Data Set, a time series graph of over 200K Bitcoin transactions (nodes), 234K directed payment flows (edges), and 166 node features, including ones based on non-public data; to our knowledge, this is the largest labelled transaction data set publicly available in any cryptocurrency. We share results from a binary classification task predicting illicit transactions using variations of Logistic Regression (LR), Random Forest (RF), Multilayer Perceptrons (MLP), and Graph Convolutional Networks (GCN), with GCN being of special interest as an emergent new method for capturing relational information. The results show the superiority of Random Forest (RF), but also invite algorithmic work to combine the respective powers of RF and graph methods. Lastly, we consider visualization for analysis and explainability, which is difficult given the size and dynamism of real-world transaction graphs, and we offer a simple prototype capable of navigating the graph and observing model performance on illicit activity over time. With this tutorial and data set, we hope to a) invite feedback in support of our ongoing inquiry, and b) inspire others to work on this societally important challenge.
Scalable Graph Learning for Anti-Money Laundering: A First Look
Nov 30, 2018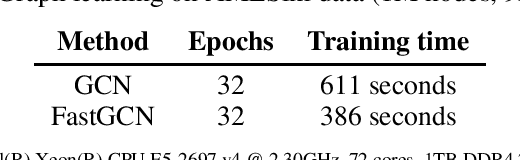
Organized crime inflicts human suffering on a genocidal scale: the Mexican drug cartels have murdered 150,000 people since 2006, upwards of 700,000 people per year are "exported" in a human trafficking industry enslaving an estimated 40 million people. These nefarious industries rely on sophisticated money laundering schemes to operate. Despite tremendous resources dedicated to anti-money laundering (AML) only a tiny fraction of illicit activity is prevented. The research community can help. In this brief paper, we map the structural and behavioral dynamics driving the technical challenge. We review AML methods, current and emergent. We provide a first look at scalable graph convolutional neural networks for forensic analysis of financial data, which is massive, dense, and dynamic. We report preliminary experimental results using a large synthetic graph (1M nodes, 9M edges) generated by a data simulator we created called AMLSim. We consider opportunities for high performance efficiency, in terms of computation and memory, and we share results from a simple graph compression experiment. Our results support our working hypothesis that graph deep learning for AML bears great promise in the fight against criminal financial activity.