 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Modular Autonomy Software for Autonomous Racing Vehicles
Aug 27, 2024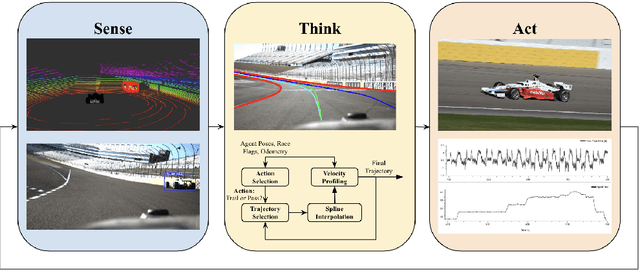



Autonomous motorsports aim to replicate the human racecar driver with software and sensors. As in traditional motorsports, Autonomous Racing Vehicles (ARVs) are pushed to their handling limits in multi-agent scenarios at extremely high ($\geq 150mph$) speeds. This Operational Design Domain (ODD) presents unique challenges across the autonomy stack. The Indy Autonomous Challenge (IAC) is an international competition aiming to advance autonomous vehicle development through ARV competitions. While far from challenging what a human racecar driver can do, the IAC is pushing the state of the art by facilitating full-sized ARV competitions. This paper details the MIT-Pitt-RW Team's approach to autonomous racing in the IAC. In this work, we present our modular and fast approach to agent detection, motion planning and controls to create an autonomy stack. We also provide analysis of the performance of the software stack in single and multi-agent scenarios for rapid deployment in a fast-paced competition environment. We also cover what did and did not work when deployed on a physical system the Dallara AV-21 platform and potential improvements to address these shortcomings. Finally, we convey lessons learned and discuss limitations and future directions for improvement.
* Published in Journal of Field Robotics
Accelerating Training and Inference of Graph Neural Networks with Fast Sampling and Pipelining
Oct 16, 2021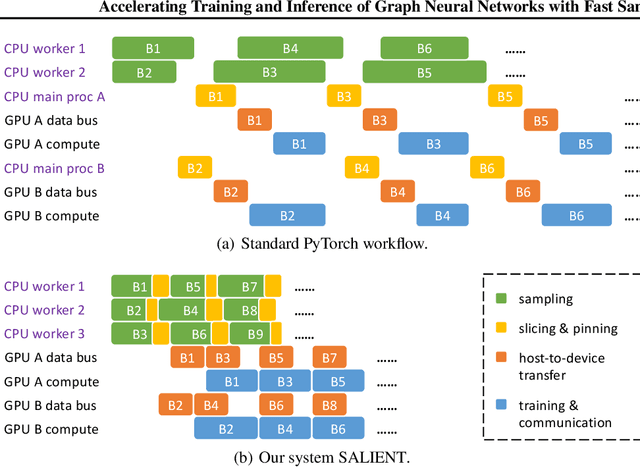
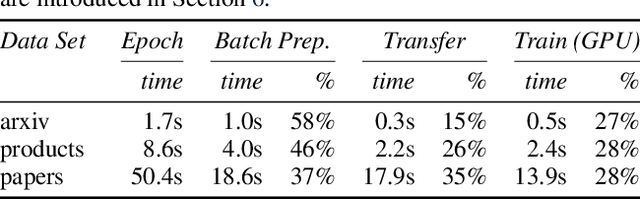
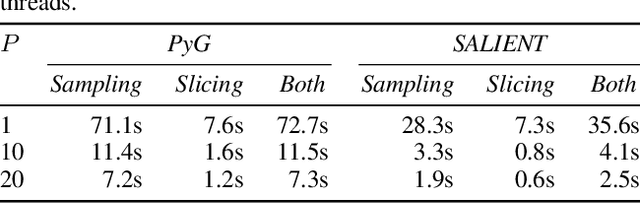
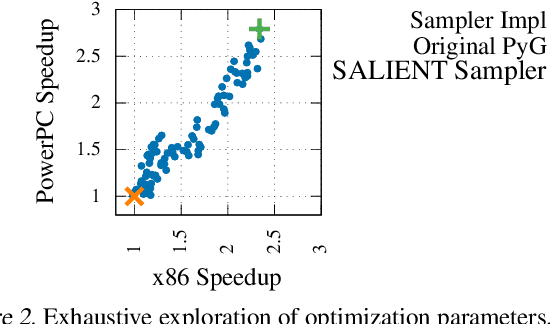
Improving the training and inference performance of graph neural networks (GNNs) is faced with a challenge uncommon in general neural networks: creating mini-batches requires a lot of computation and data movement due to the exponential growth of multi-hop graph neighborhoods along network layers. Such a unique challenge gives rise to a diverse set of system design choices. We argue in favor of performing mini-batch training with neighborhood sampling in a distributed multi-GPU environment, under which we identify major performance bottlenecks hitherto under-explored by developers: mini-batch preparation and transfer. We present a sequence of improvements to mitigate these bottlenecks, including a performance-engineered neighborhood sampler, a shared-memory parallelization strategy, and the pipelining of batch transfer with GPU computation. We also conduct an empirical analysis that supports the use of sampling for inference, showing that test accuracies are not materially compromised. Such an observation unifies training and inference, simplifying model implementation. We report comprehensive experimental results with several benchmark data sets and GNN architectures, including a demonstration that, for the ogbn-papers100M data set, our system SALIENT achieves a speedup of 3x over a standard PyTorch-Geometric implementation with a single GPU and a further 8x parallel speedup with 16 GPUs. Therein, training a 3-layer GraphSAGE model with sampling fanout (15, 10, 5) takes 2.0 seconds per epoch and inference with fanout (20, 20, 20) takes 2.4 seconds, attaining test accuracy 64.58%.