 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-aided multiscale modeling of physiologically-significant blood clots
May 25, 2022We have developed an AI-aided multiple time stepping (AI-MTS) algorithm and multiscale modeling framework (AI-MSM) and implemented them on the Summit-like supercomputer, AIMOS. AI-MSM is the first of its kind to integrate multi-physics, including intra-platelet, inter-platelet, and fluid-platelet interactions, into one system. It has simulated a record-setting multiscale blood clotting model of 102 million particles, of which 70 flowing and 180 aggregating platelets, under dissipative particle dynamics to coarse-grained molecular dynamics. By adaptively adjusting timestep sizes to match the characteristic time scales of the underlying dynamics, AI-MTS optimally balances speeds and accuracies of the simulations.
CASTELO: Clustered Atom Subtypes aidEd Lead Optimization -- a combined machine learning and molecular modeling method
Nov 27, 2020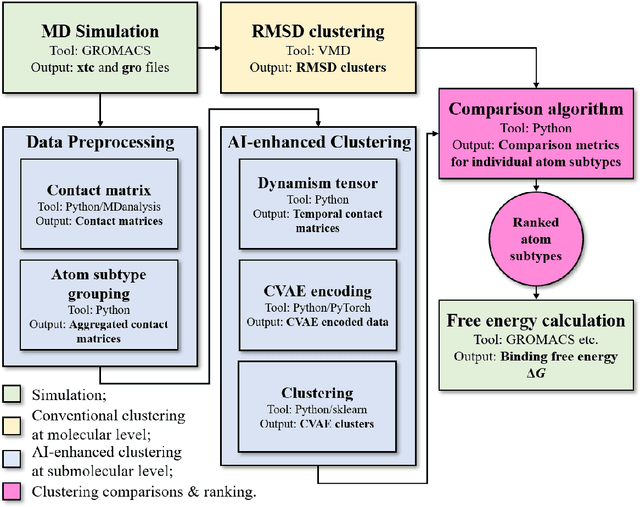

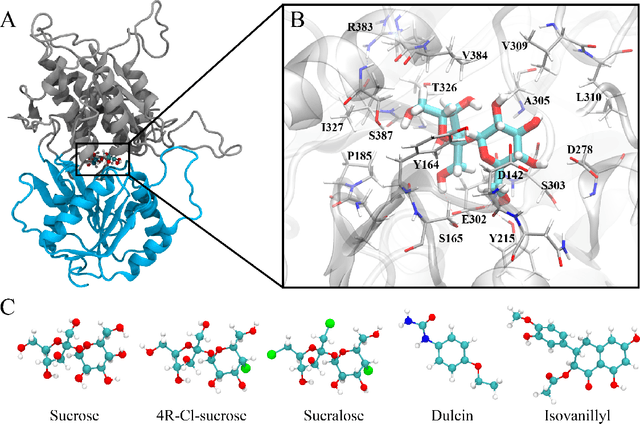
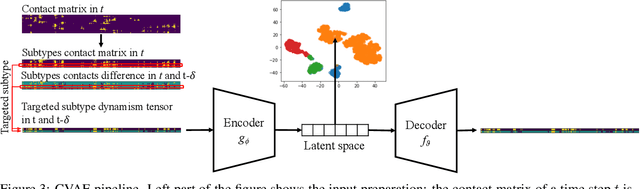
Drug discovery is a multi-stage process that comprises two costly major steps: pre-clinical research and clinical trials. Among its stages, lead optimization easily consumes more than half of the pre-clinical budget. We propose a combined machine learning and molecular modeling approach that automates lead optimization workflow \textit{in silico}. The initial data collection is achieved with physics-based molecular dynamics (MD) simulation. Contact matrices are calculated as the preliminary features extracted from the simulations. To take advantage of the temporal information from the simulations, we enhanced contact matrices data with temporal dynamism representation, which are then modeled with unsupervised convolutional variational autoencoder (CVAE). Finally, conventional clustering method and CVAE-based clustering method are compared with metrics to rank the submolecular structures and propose potential candidates for lead optimization. With no need for extensive structure-activity relationship database, our method provides new hints for drug modification hotspots which can be used to improve drug efficacy. Our workflow can potentially reduce the lead optimization turnaround time from months/years to days compared with the conventional labor-intensive process and thus can potentially become a valuable tool for medical researchers.
Accelerating Data Loading in Deep Neural Network Training
Oct 02, 2019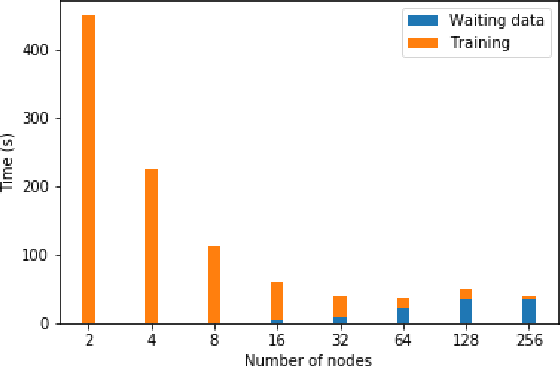
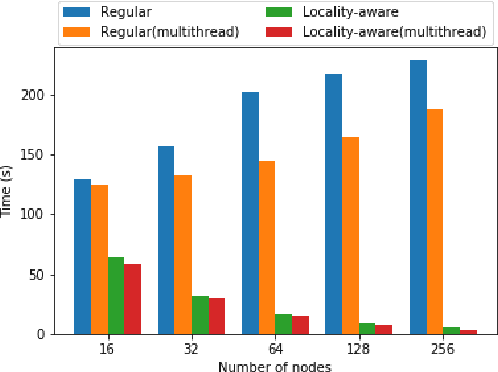
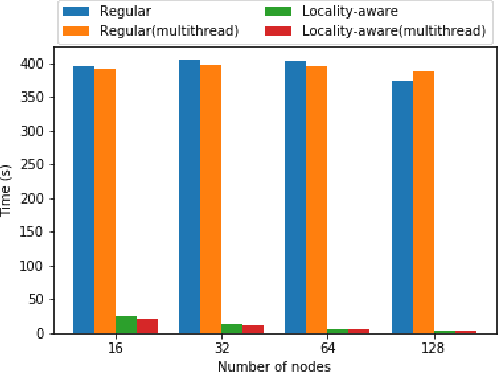
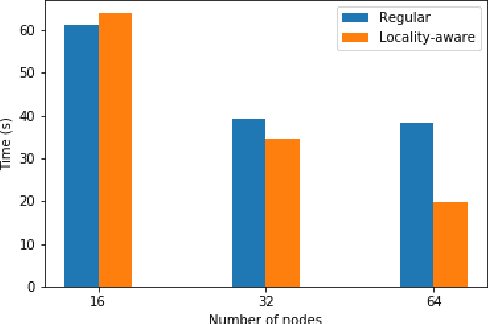
Data loading can dominate deep neural network training time on large-scale systems. We present a comprehensive study on accelerating data loading performance in large-scale distributed training. We first identify performance and scalability issues in current data loading implementations. We then propose optimizations that utilize CPU resources to the data loader design. We use an analytical model to characterize the impact of data loading on the overall training time and establish the performance trend as we scale up distributed training. Our model suggests that I/O rate limits the scalability of distributed training, which inspires us to design a locality-aware data loading method. By utilizing software caches, our method can drastically reduce the data loading communication volume in comparison with the original data loading implementation. Finally, we evaluate the proposed optimizations with various experiments. We achieved more than 30x speedup in data loading using 256 nodes with 1,024 learners.