 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Training of Deep Neural Network Acoustic Models for Automatic Speech Recognition
Paper and Code
Feb 24, 2020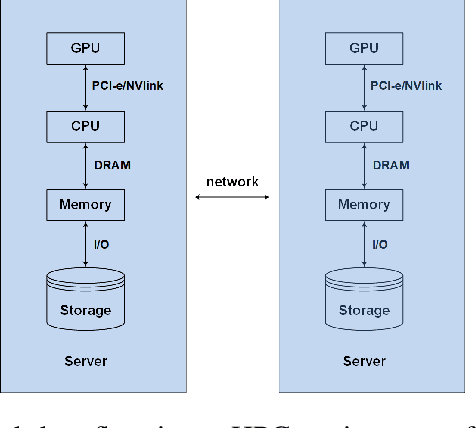
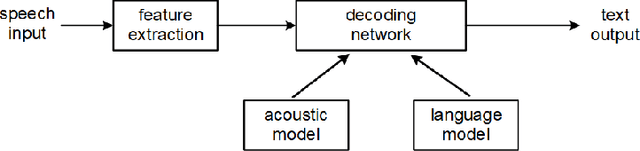
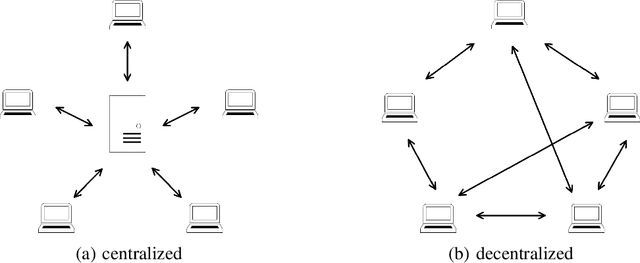
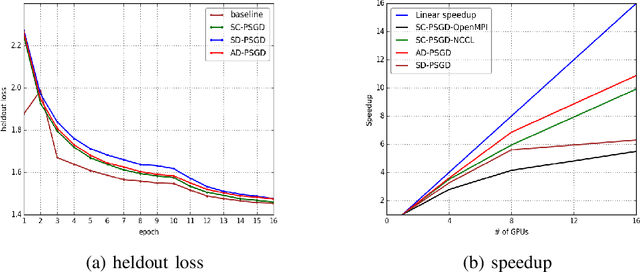
The past decade has witnessed great progress in Automatic Speech Recognition (ASR) due to advances in deep learning. The improvements in performance can be attributed to both improved models and large-scale training data. Key to training such models is the employment of efficient distributed learning techniques. In this article, we provide an overview of distributed training techniques for deep neural network acoustic models for ASR. Starting with the fundamentals of data parallel stochastic gradient descent (SGD) and ASR acoustic modeling, we will investigate various distributed training strategies and their realizations in high performance computing (HPC) environments with an emphasis on striking the balance between communication and computation. Experiments are carried out on a popular public benchmark to study the convergence, speedup and recognition performance of the investigated strategies.