 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASTransfer: Analyzing Architecture Transferability in Large Scale Neural Architecture Search
Jun 23, 2020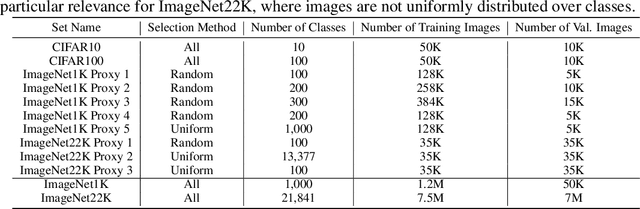
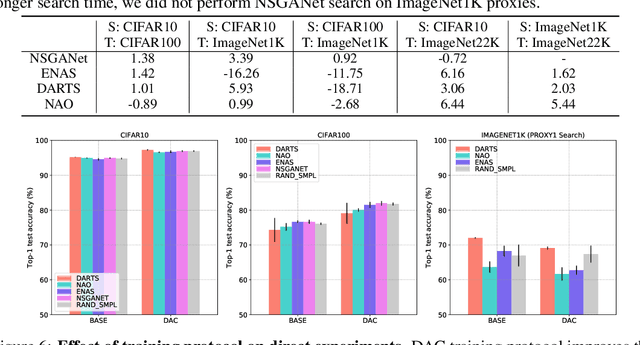
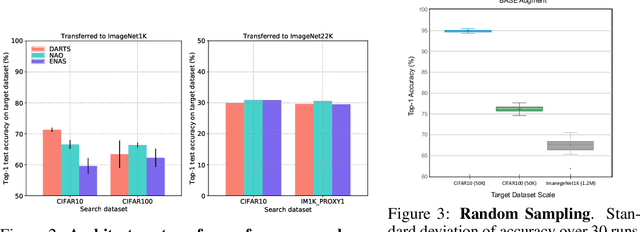
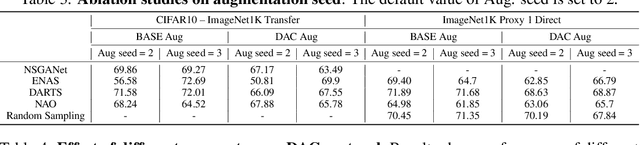
Neural Architecture Search (NAS) is an open and challenging problem in machine learning. While NAS offers great promise, the prohibitive computational demand of most of the existing NAS methods makes it difficult to directly search the architectures on large-scale tasks. The typical way of conducting large scale NAS is to search for an architectural building block on a small dataset (either using a proxy set from the large dataset or a completely different small scale dataset) and then transfer the block to a larger dataset. Despite a number of recent results that show the promise of transfer from proxy datasets, a comprehensive evaluation of different NAS methods studying the impact of different source datasets and training protocols has not yet been addressed. In this work, we propose to analyze the architecture transferability of different NAS methods by performing a series of experiments on large scale benchmarks such as ImageNet1K and ImageNet22K. We find that: (i) On average, transfer performance of architectures searched using completely different small datasets perform similarly to the architectures searched directly on proxy target datasets. However, design of proxy sets has considerable impact on rankings of different NAS methods. (ii) While the different NAS methods show similar performance on a source dataset (e.g., CIFAR10), they significantly differ on the transfer performance to a large dataset (e.g., ImageNet1K). (iii) Even on large datasets, the randomly sampled architecture baseline is very competitive and significantly outperforms many representative NAS methods. (iv) The training protocol has a larger impact on small datasets, but it fails to provide consistent improvements on large datasets. We believe that our NASTransfer benchmark will be key to designing future NAS strategies that consistently show superior transfer performance on large scale datasets.
Assessing Shape Bias Property of Convolutional Neural Networks
Mar 21, 2018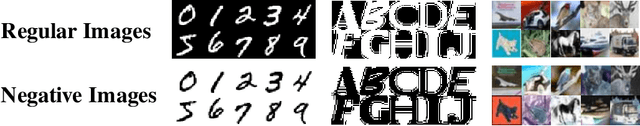
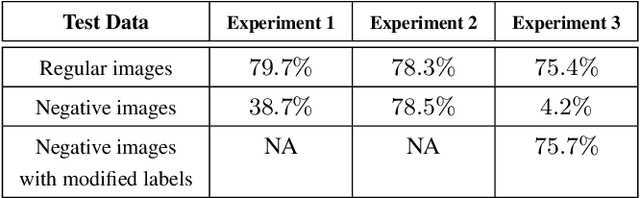
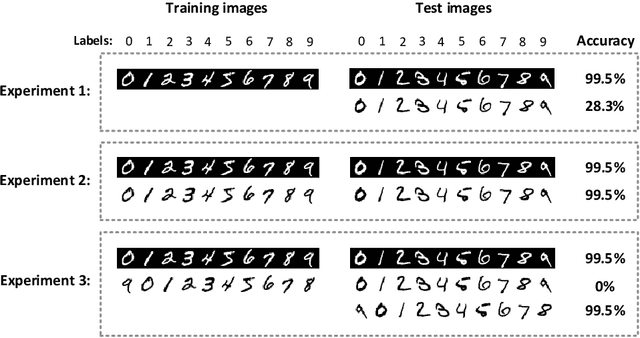
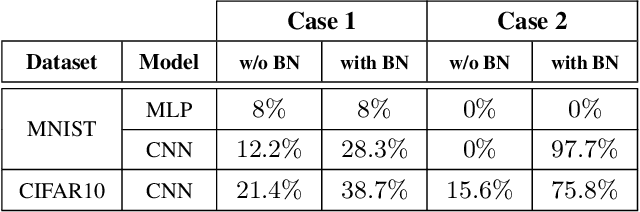
It is known that humans display "shape bias" when classifying new items, i.e., they prefer to categorize objects based on their shape rather than color. Convolutional Neural Networks (CNNs) are also designed to take into account the spatial structure of image data. In fact, experiments on image datasets, consisting of triples of a probe image, a shape-match and a color-match, have shown that one-shot learning models display shape bias as well. In this paper, we examine the shape bias property of CNNs. In order to conduct large scale experiments, we propose using the model accuracy on images with reversed brightness as a metric to evaluate the shape bias property. Such images, called negative images, contain objects that have the same shape as original images, but with different colors. Through extensive systematic experiments, we investigate the role of different factors, such as training data, model architecture, initialization and regularization techniques, on the shape bias property of CNNs. We show that it is possible to design different CNNs that achieve similar accuracy on original images, but perform significantly different on negative images, suggesting that CNNs do not intrinsically display shape bias. We then show that CNNs are able to learn and generalize the structures, when the model is properly initialized or data is properly augmented, and if batch normalization is used.
On the Limitation of Convolutional Neural Networks in Recognizing Negative Images
Aug 07, 2017
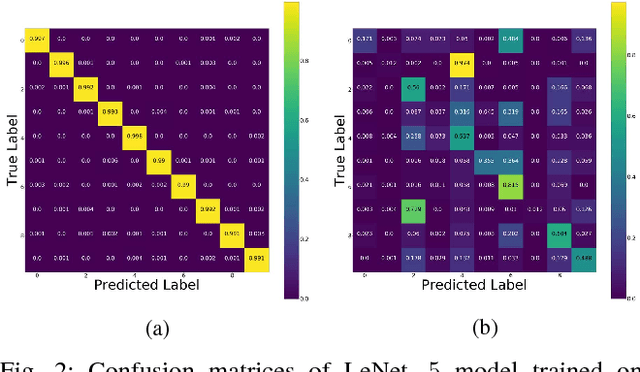
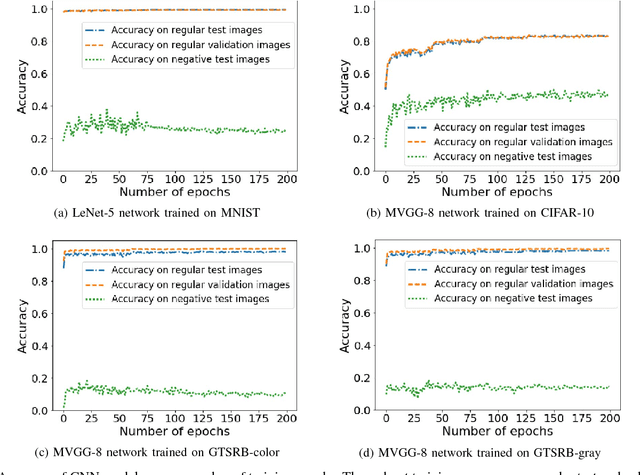
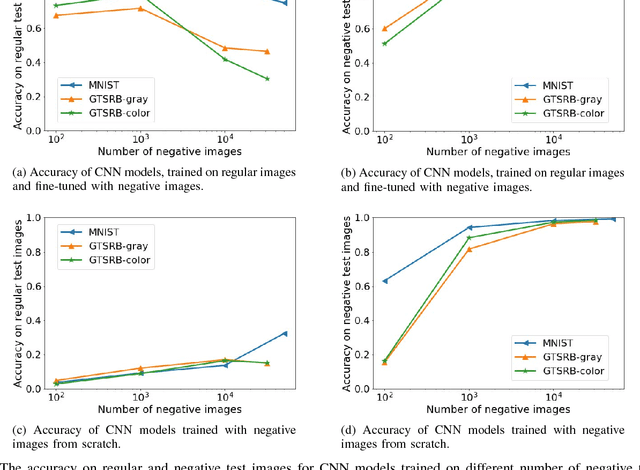
Convolutional Neural Networks (CNNs) have achieved state-of-the-art performance on a variety of computer vision tasks, particularly visual classification problems, where new algorithms reported to achieve or even surpass the human performance. In this paper, we examine whether CNNs are capable of learning the semantics of training data. To this end, we evaluate CNNs on negative images, since they share the same structure and semantics as regular images and humans can classify them correctly. Our experimental results indicate that when training on regular images and testing on negative images, the model accuracy is significantly lower than when it is tested on regular images. This leads us to the conjecture that current training methods do not effectively train models to generalize the concepts. We then introduce the notion of semantic adversarial examples - transformed inputs that semantically represent the same objects, but the model does not classify them correctly - and present negative images as one class of such inputs.