 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning API Functionality from Demonstrations for Tool-based Agents
May 30, 2025Digital tool-based agents that invoke external Application Programming Interfaces (APIs) often rely on documentation to understand API functionality. However, such documentation is frequently missing, outdated, privatized, or inconsistent-hindering the development of reliable, general-purpose agents. In this work, we propose learning API functionality directly from demonstrations as a new paradigm applicable in scenarios without documentation. Using existing API benchmarks, we collect demonstrations from both expert API-based agents and from self-exploration. To understand what information demonstrations must convey for successful task completion, we extensively study how the number of demonstrations and the use of LLM-generated summaries and evaluations affect the task success rate of the API-based agent. Our experiments across 3 datasets and 5 models show that learning functionality from demonstrations remains a non-trivial challenge, even for state-of-the-art LLMs. We find that providing explicit function calls and natural language critiques significantly improves the agent's task success rate due to more accurate parameter filling. We analyze failure modes, identify sources of error, and highlight key open challenges for future work in documentation-free, self-improving, API-based agents.
Multimodal Auto Validation For Self-Refinement in Web Agents
Oct 01, 2024As our world digitizes, web agents that can automate complex and monotonous tasks are becoming essential in streamlining workflows. This paper introduces an approach to improving web agent performance through multi-modal validation and self-refinement. We present a comprehensive study of different modalities (text, vision) and the effect of hierarchy for the automatic validation of web agents, building upon the state-of-the-art Agent-E web automation framework. We also introduce a self-refinement mechanism for web automation, using the developed auto-validator, that enables web agents to detect and self-correct workflow failures. Our results show significant gains on Agent-E's (a SOTA web agent) prior state-of-art performance, boosting task-completion rates from 76.2\% to 81.24\% on the subset of the WebVoyager benchmark. The approach presented in this paper paves the way for more reliable digital assistants in complex, real-world scenarios.
Building a Domain-specific Guardrail Model in Production
Jul 24, 2024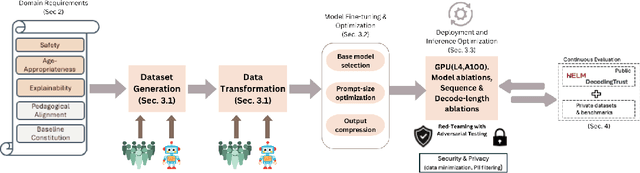
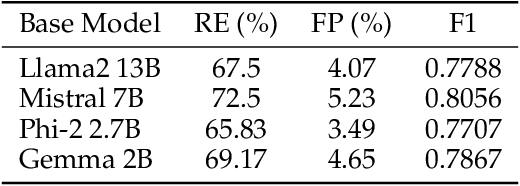

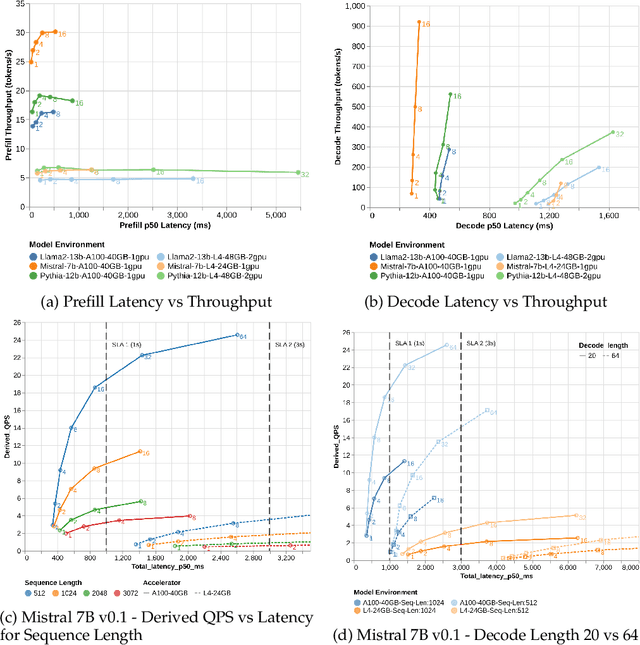
Generative AI holds the promise of enabling a range of sought-after capabilities and revolutionizing workflows in various consumer and enterprise verticals. However, putting a model in production involves much more than just generating an output. It involves ensuring the model is reliable, safe, performant and also adheres to the policy of operation in a particular domain. Guardrails as a necessity for models has evolved around the need to enforce appropriate behavior of models, especially when they are in production. In this paper, we use education as a use case, given its stringent requirements of the appropriateness of content in the domain, to demonstrate how a guardrail model can be trained and deployed in production. Specifically, we describe our experience in building a production-grade guardrail model for a K-12 educational platform. We begin by formulating the requirements for deployment to this sensitive domain. We then describe the training and benchmarking of our domain-specific guardrail model, which outperforms competing open- and closed- instruction-tuned models of similar and larger size, on proprietary education-related benchmarks and public benchmarks related to general aspects of safety. Finally, we detail the choices we made on architecture and the optimizations for deploying this service in production; these range across the stack from the hardware infrastructure to the serving layer to language model inference optimizations. We hope this paper will be instructive to other practitioners looking to create production-grade domain-specific services based on generative AI and large language models.
MathViz-E: A Case-study in Domain-Specialized Tool-Using Agents
Jul 24, 2024



There has been significant recent interest in harnessing LLMs to control software systems through multi-step reasoning, planning and tool-usage. While some promising results have been obtained, application to specific domains raises several general issues including the control of specialized domain tools, the lack of existing datasets for training and evaluation, and the non-triviality of automated system evaluation and improvement. In this paper, we present a case-study where we examine these issues in the context of a specific domain. Specifically, we present an automated math visualizer and solver system for mathematical pedagogy. The system orchestrates mathematical solvers and math graphing tools to produce accurate visualizations from simple natural language commands. We describe the creation of specialized data-sets, and also develop an auto-evaluator to easily evaluate the outputs of our system by comparing them to ground-truth expressions. We have open sourced the data-sets and code for the proposed system.
Agent-E: From Autonomous Web Navigation to Foundational Design Principles in Agentic Systems
Jul 17, 2024



AI Agents are changing the way work gets done, both in consumer and enterprise domains. However, the design patterns and architectures to build highly capable agents or multi-agent systems are still developing, and the understanding of the implication of various design choices and algorithms is still evolving. In this paper, we present our work on building a novel web agent, Agent-E \footnote{Our code is available at \url{https://github.com/EmergenceAI/Agent-E}}. Agent-E introduces numerous architectural improvements over prior state-of-the-art web agents such as hierarchical architecture, flexible DOM distillation and denoising method, and the concept of \textit{change observation} to guide the agent towards more accurate performance. We first present the results of an evaluation of Agent-E on WebVoyager benchmark dataset and show that Agent-E beats other SOTA text and multi-modal web agents on this benchmark in most categories by 10-30\%. We then synthesize our learnings from the development of Agent-E into general design principles for developing agentic systems. These include the use of domain-specific primitive skills, the importance of distillation and de-noising of environmental observations, the advantages of a hierarchical architecture, and the role of agentic self-improvement to enhance agent efficiency and efficacy as the agent gathers experience.
Automating question generation from educational text
Sep 26, 2023The use of question-based activities (QBAs) is wide-spread in education, traditionally forming an integral part of the learning and assessment process. In this paper, we design and evaluate an automated question generation tool for formative and summative assessment in schools. We present an expert survey of one hundred and four teachers, demonstrating the need for automated generation of QBAs, as a tool that can significantly reduce the workload of teachers and facilitate personalized learning experiences. Leveraging the recent advancements in generative AI, we then present a modular framework employing transformer based language models for automatic generation of multiple-choice questions (MCQs) from textual content. The presented solution, with distinct modules for question generation, correct answer prediction, and distractor formulation, enables us to evaluate different language models and generation techniques. Finally, we perform an extensive quantitative and qualitative evaluation, demonstrating trade-offs in the use of different techniques and models.
Math Programming based Reinforcement Learning for Multi-Echelon Inventory Management
Dec 04, 2021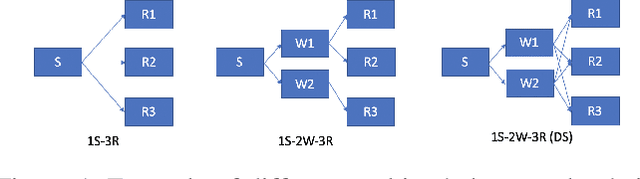
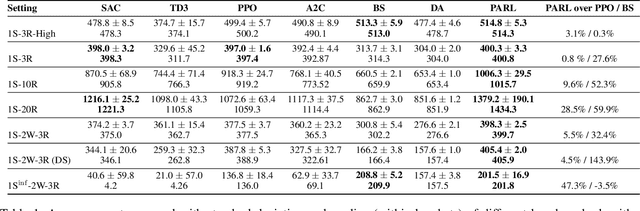
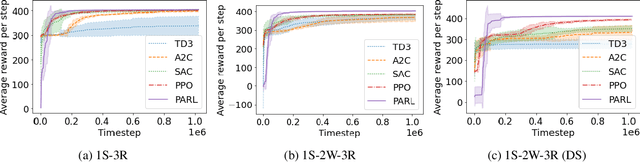

Reinforcement learning has lead to considerable break-throughs in diverse areas such as robotics, games and many others. But the application to RL in complex real-world decision making problems remains limited. Many problems in operations management (inventory and revenue management, for example) are characterized by large action spaces and stochastic system dynamics. These characteristics make the problem considerably harder to solve for existing RL methods that rely on enumeration techniques to solve per step action problems. To resolve these issues, we develop Programmable Actor Reinforcement Learning (PARL), a policy iteration method that uses techniques from integer programming and sample average approximation. Analytically, we show that the for a given critic, the learned policy in each iteration converges to the optimal policy as the underlying samples of the uncertainty go to infinity. Practically, we show that a properly selected discretization of the underlying uncertain distribution can yield near optimal actor policy even with very few samples from the underlying uncertainty. We then apply our algorithm to real-world inventory management problems with complex supply chain structures and show that PARL outperforms state-of-the-art RL and inventory optimization methods in these settings. We find that PARL outperforms commonly used base stock heuristic by 44.7% and the best performing RL method by up to 12.1% on average across different supply chain environments.
Nonstationary Reinforcement Learning with Linear Function Approximation
Oct 15, 2020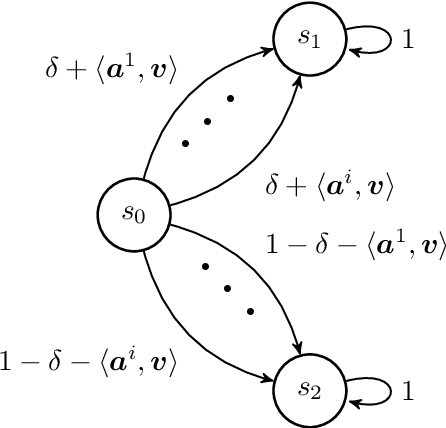
We consider reinforcement learning (RL) in episodic Markov decision processes (MDPs) with linear function approximation under drifting environment. Specifically, both the reward and state transition functions can evolve over time, as long as their respective total variations, quantified by suitable metrics, do not exceed certain \textit{variation budgets}. We first develop the $\texttt{LSVI-UCB-Restart}$ algorithm, an optimistic modification of least-squares value iteration combined with periodic restart, and establish its dynamic regret bound when variation budgets are known. We then propose a parameter-free algorithm, $\texttt{Ada-LSVI-UCB-Restart}$, that works without knowing the variation budgets, but with a slightly worse dynamic regret bound. We also derive the first minimax dynamic regret lower bound for nonstationary MDPs to show that our proposed algorithms are near-optimal. As a byproduct, we establish a minimax regret lower bound for linear MDPs, which is unsolved by \cite{jin2020provably}. In addition, we provide numerical experiments to demonstrate the effectiveness of our proposed algorithms. As far as we know, this is the first dynamic regret analysis in nonstationary reinforcement learning with function approximation.
Differentially Private Distributed Data Summarization under Covariate Shift
Oct 28, 2019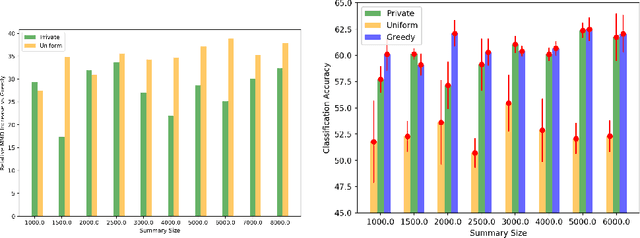
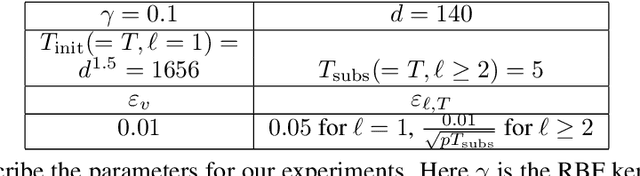
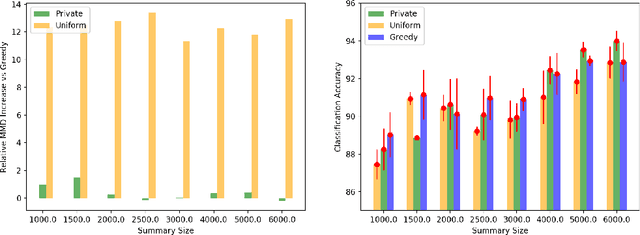
We envision AI marketplaces to be platforms where consumers, with very less data for a target task, can obtain a relevant model by accessing many private data sources with vast number of data samples. One of the key challenges is to construct a training dataset that matches a target task without compromising on privacy of the data sources. To this end, we consider the following distributed data summarizataion problem. Given K private source datasets denoted by $[D_i]_{i\in [K]}$ and a small target validation set $D_v$, which may involve a considerable covariate shift with respect to the sources, compute a summary dataset $D_s\subseteq \bigcup_{i\in [K]} D_i$ such that its statistical distance from the validation dataset $D_v$ is minimized. We use the popular Maximum Mean Discrepancy as the measure of statistical distance. The non-private problem has received considerable attention in prior art, for example in prototype selection (Kim et al., NIPS 2016). Our work is the first to obtain strong differential privacy guarantees while ensuring the quality guarantees of the non-private version. We study this problem in a Parsimonious Curator Privacy Model, where a trusted curator coordinates the summarization process while minimizing the amount of private information accessed. Our central result is a novel protocol that (a) ensures the curator accesses at most $O(K^{\frac{1}{3}}|D_s| + |D_v|)$ points (b) has formal privacy guarantees on the leakage of information between the data owners and (c) closely matches the best known non-private greedy algorithm. Our protocol uses two hash functions, one inspired by the Rahimi-Recht random features method and the second leverages state of the art differential privacy mechanisms. We introduce a novel "noiseless" differentially private auctioning protocol for winner notification and demonstrate the efficacy of our protocol using real-world datasets.