 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence WebVoyager: Toward Consistent and Transparent Evaluation of (Web) Agents in The Wild
Mar 30, 2026Reliable evaluation of AI agents operating in complex, real-world environments requires methodologies that are robust, transparent, and contextually aligned with the tasks agents are intended to perform. This study identifies persistent shortcomings in existing AI agent evaluation practices that are particularly acute in web agent evaluation, as exemplified by our audit of WebVoyager, including task-framing ambiguity and operational variability that hinder meaningful and reproducible performance comparisons. To address these challenges, we introduce Emergence WebVoyager, an enhanced version of the WebVoyager benchmark that standardizes evaluation methodology through clear guidelines for task instantiation, failure handling, annotation, and reporting. Emergence WebVoyager achieves an inter-annotator agreement of 95.9\%, indicating improved clarity and reliability in both task formulation and evaluation. Applying this framework to evaluate OpenAI Operator reveals substantial performance variation across domains and task types, with an overall success rate of 68.6\%, substantially lower than the 87\% previously reported by OpenAI, demonstrating the utility of our approach for more rigorous and comparable web agent evaluation.
Multimodal Auto Validation For Self-Refinement in Web Agents
Oct 01, 2024As our world digitizes, web agents that can automate complex and monotonous tasks are becoming essential in streamlining workflows. This paper introduces an approach to improving web agent performance through multi-modal validation and self-refinement. We present a comprehensive study of different modalities (text, vision) and the effect of hierarchy for the automatic validation of web agents, building upon the state-of-the-art Agent-E web automation framework. We also introduce a self-refinement mechanism for web automation, using the developed auto-validator, that enables web agents to detect and self-correct workflow failures. Our results show significant gains on Agent-E's (a SOTA web agent) prior state-of-art performance, boosting task-completion rates from 76.2\% to 81.24\% on the subset of the WebVoyager benchmark. The approach presented in this paper paves the way for more reliable digital assistants in complex, real-world scenarios.
Agent-E: From Autonomous Web Navigation to Foundational Design Principles in Agentic Systems
Jul 17, 2024



AI Agents are changing the way work gets done, both in consumer and enterprise domains. However, the design patterns and architectures to build highly capable agents or multi-agent systems are still developing, and the understanding of the implication of various design choices and algorithms is still evolving. In this paper, we present our work on building a novel web agent, Agent-E \footnote{Our code is available at \url{https://github.com/EmergenceAI/Agent-E}}. Agent-E introduces numerous architectural improvements over prior state-of-the-art web agents such as hierarchical architecture, flexible DOM distillation and denoising method, and the concept of \textit{change observation} to guide the agent towards more accurate performance. We first present the results of an evaluation of Agent-E on WebVoyager benchmark dataset and show that Agent-E beats other SOTA text and multi-modal web agents on this benchmark in most categories by 10-30\%. We then synthesize our learnings from the development of Agent-E into general design principles for developing agentic systems. These include the use of domain-specific primitive skills, the importance of distillation and de-noising of environmental observations, the advantages of a hierarchical architecture, and the role of agentic self-improvement to enhance agent efficiency and efficacy as the agent gathers experience.
Design and Evaluation of a Tutor Platform for Personalized Vocabulary Learning
Jul 09, 2018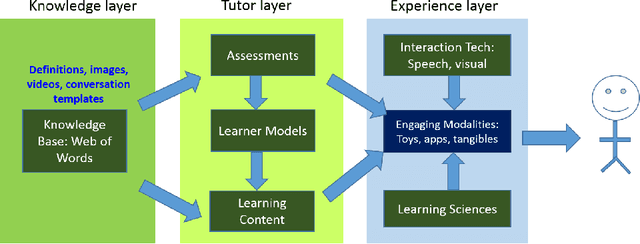
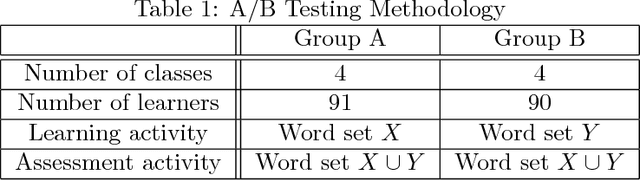
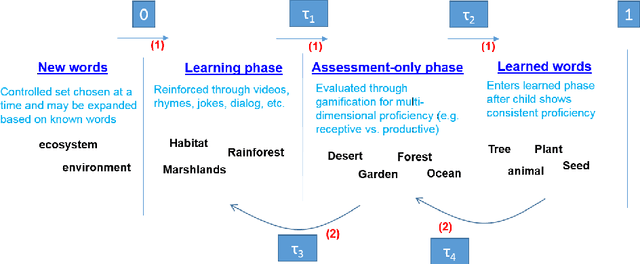

This paper presents our experiences in designing, implementing, and piloting an intelligent vocabulary learning tutor. The design builds on several intelligent tutoring design concepts, including graph-based knowledge representation, learner modeling, and adaptive learning content and assessment exposition. Specifically, we design a novel phased learner model approach to enable systematic exposure to words during vocabulary instruction. We also built an example application over the tutor platform that uses a learning activity involving videos and an assessment activity involving word to picture/image association. More importantly, the tutor adapts to the significant variation in children's knowledge at the beginning of kindergarten, and evolves the application at the speed of each individual learner. A pilot study with 180 kindergarten learners allowed the tutor to collect various kinds of activity information suitable for insights and interventions both at an individual- and class-level. The effort also demonstrates that we can do A/B testing for a variety of hypotheses at scale with such a framework.