 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Domain-specific Guardrail Model in Production
Jul 24, 2024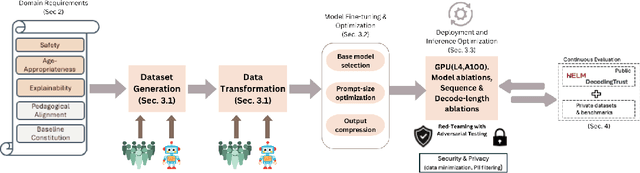
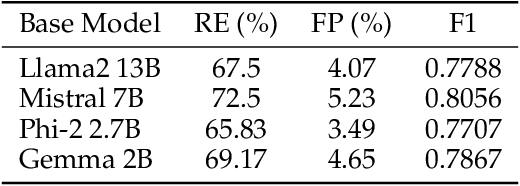

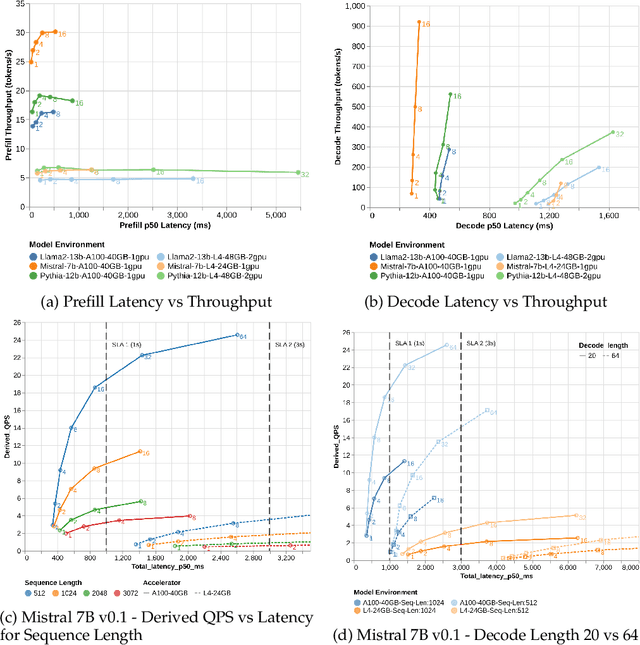
Generative AI holds the promise of enabling a range of sought-after capabilities and revolutionizing workflows in various consumer and enterprise verticals. However, putting a model in production involves much more than just generating an output. It involves ensuring the model is reliable, safe, performant and also adheres to the policy of operation in a particular domain. Guardrails as a necessity for models has evolved around the need to enforce appropriate behavior of models, especially when they are in production. In this paper, we use education as a use case, given its stringent requirements of the appropriateness of content in the domain, to demonstrate how a guardrail model can be trained and deployed in production. Specifically, we describe our experience in building a production-grade guardrail model for a K-12 educational platform. We begin by formulating the requirements for deployment to this sensitive domain. We then describe the training and benchmarking of our domain-specific guardrail model, which outperforms competing open- and closed- instruction-tuned models of similar and larger size, on proprietary education-related benchmarks and public benchmarks related to general aspects of safety. Finally, we detail the choices we made on architecture and the optimizations for deploying this service in production; these range across the stack from the hardware infrastructure to the serving layer to language model inference optimizations. We hope this paper will be instructive to other practitioners looking to create production-grade domain-specific services based on generative AI and large language models.
TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
Feb 27, 2023



Recommendation systems are a core feature of social media companies with their uses including recommending organic and promoted contents. Many modern recommendation systems are split into multiple stages - candidate generation and heavy ranking - to balance computational cost against recommendation quality. We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC. We show that a system that combines a real-time light ranker with sourcing strategies capable of capturing additional information provides validated gains. We present two strategies. The first strategy uses a notion of similarity in the interaction graph, while the second strategy caches previous scores from the ranking stage. The graph based strategy achieves a 4.08% revenue gain and the rankscore based strategy achieves a 1.38% gain. These two strategies have biases that complement both the light ranker and one another. Finally, we describe a set of metrics that we believe are valuable as a means of understanding the complex product trade offs inherent in industrial candidate generation systems.