 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Federated Learning over Vertically and Horizontally Partitioned Data for Financial Anomaly Detection
Oct 30, 2023The effective detection of evidence of financial anomalies requires collaboration among multiple entities who own a diverse set of data, such as a payment network system (PNS) and its partner banks. Trust among these financial institutions is limited by regulation and competition. Federated learning (FL) enables entities to collaboratively train a model when data is either vertically or horizontally partitioned across the entities. However, in real-world financial anomaly detection scenarios, the data is partitioned both vertically and horizontally and hence it is not possible to use existing FL approaches in a plug-and-play manner. Our novel solution, PV4FAD, combines fully homomorphic encryption (HE), secure multi-party computation (SMPC), differential privacy (DP), and randomization techniques to balance privacy and accuracy during training and to prevent inference threats at model deployment time. Our solution provides input privacy through HE and SMPC, and output privacy against inference time attacks through DP. Specifically, we show that, in the honest-but-curious threat model, banks do not learn any sensitive features about PNS transactions, and the PNS does not learn any information about the banks' dataset but only learns prediction labels. We also develop and analyze a DP mechanism to protect output privacy during inference. Our solution generates high-utility models by significantly reducing the per-bank noise level while satisfying distributed DP. To ensure high accuracy, our approach produces an ensemble model, in particular, a random forest. This enables us to take advantage of the well-known properties of ensembles to reduce variance and increase accuracy. Our solution won second prize in the first phase of the U.S. Privacy Enhancing Technologies (PETs) Prize Challenge.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020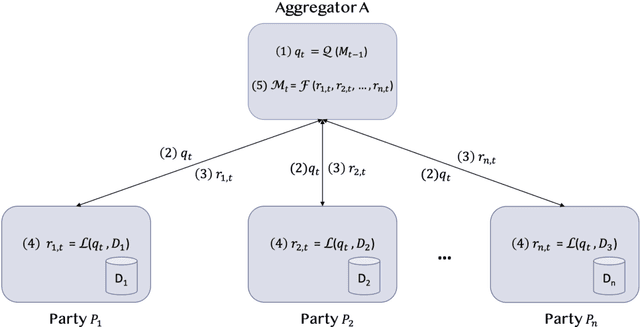
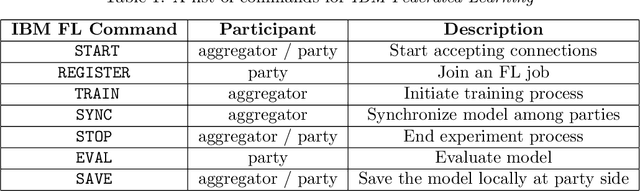
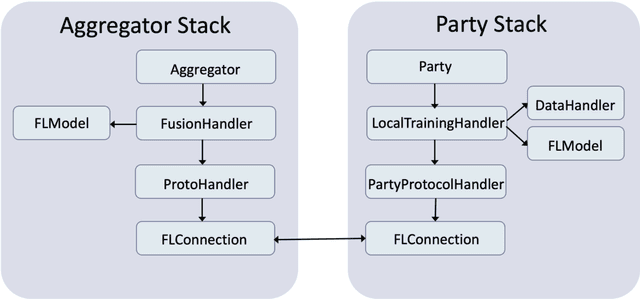
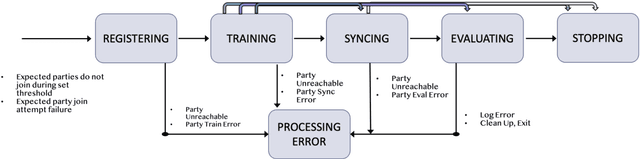
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.
Diffprivlib: The IBM Differential Privacy Library
Jul 04, 2019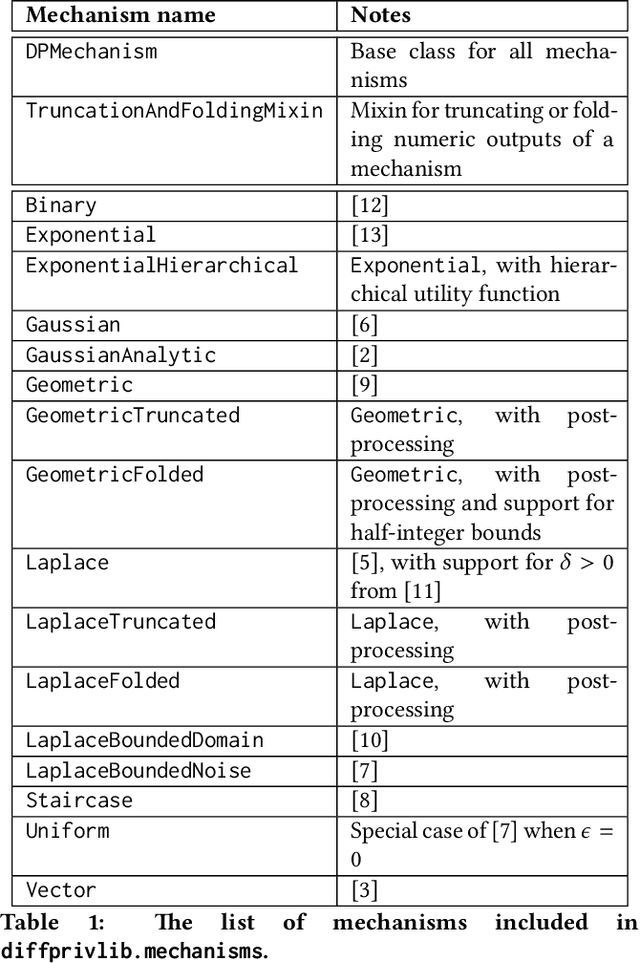
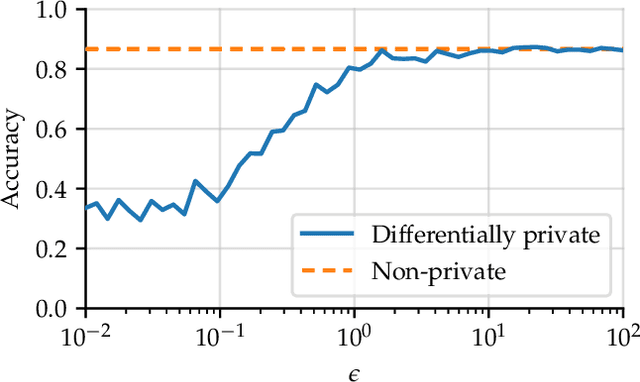
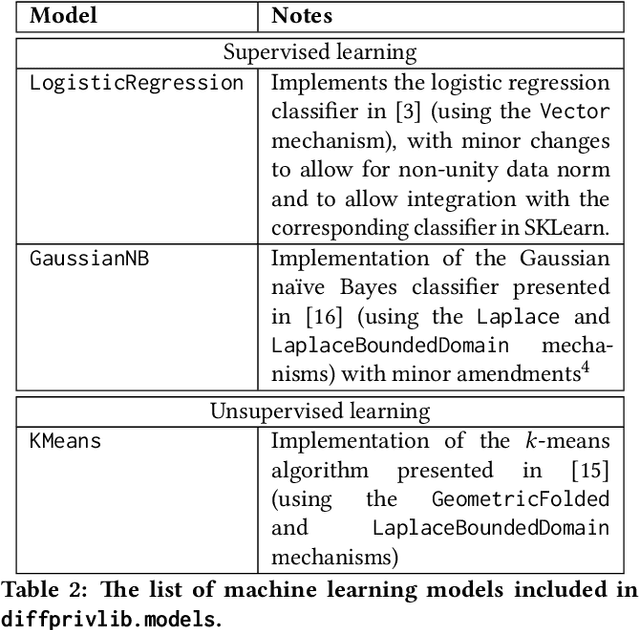
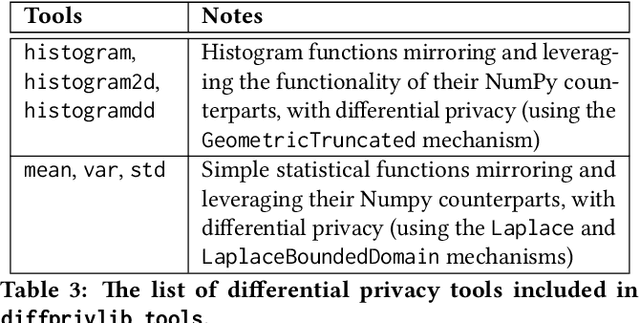
Since its conception in 2006, differential privacy has emerged as the de-facto standard in data privacy, owing to its robust mathematical guarantees, generalised applicability and rich body of literature. Over the years, researchers have studied differential privacy and its applicability to an ever-widening field of topics. Mechanisms have been created to optimise the process of achieving differential privacy, for various data types and scenarios. Until this work however, all previous work on differential privacy has been conducted on a ad-hoc basis, without a single, unifying codebase to implement results. In this work, we present the IBM Differential Privacy Library, a general purpose, open source library for investigating, experimenting and developing differential privacy applications in the Python programming language. The library includes a host of mechanisms, the building blocks of differential privacy, alongside a number of applications to machine learning and other data analytics tasks. Simplicity and accessibility has been prioritised in developing the library, making it suitable to a wide audience of users, from those using the library for their first investigations in data privacy, to the privacy experts looking to contribute their own models and mechanisms for others to use.