 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Experts' Judgment into Machine Learning Models
Apr 29, 2023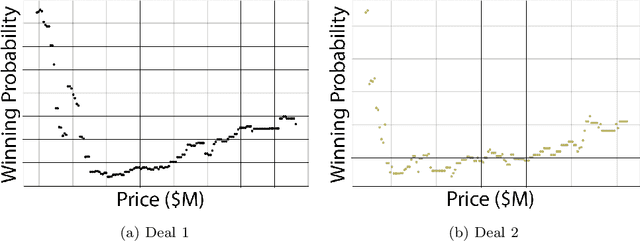
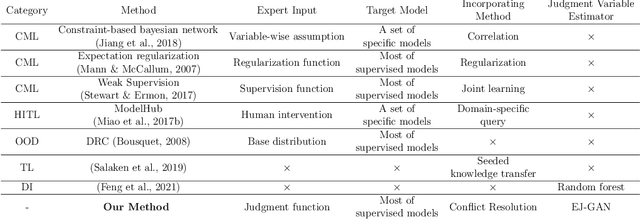
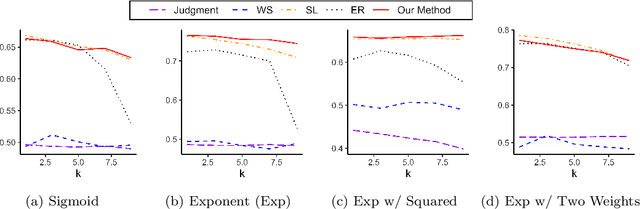
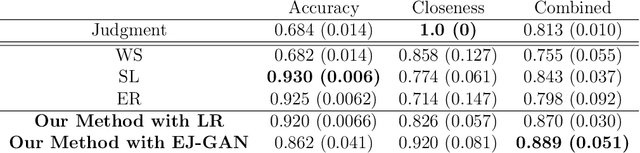
Machine learning (ML) models have been quite successful in predicting outcomes in many applications. However, in some cases, domain experts might have a judgment about the expected outcome that might conflict with the prediction of ML models. One main reason for this is that the training data might not be totally representative of the population. In this paper, we present a novel framework that aims at leveraging experts' judgment to mitigate the conflict. The underlying idea behind our framework is that we first determine, using a generative adversarial network, the degree of representation of an unlabeled data point in the training data. Then, based on such degree, we correct the \textcolor{black}{machine learning} model's prediction by incorporating the experts' judgment into it, where the higher that aforementioned degree of representation, the less the weight we put on the expert intuition that we add to our corrected output, and vice-versa. We perform multiple numerical experiments on synthetic data as well as two real-world case studies (one from the IT services industry and the other from the financial industry). All results show the effectiveness of our framework; it yields much higher closeness to the experts' judgment with minimal sacrifice in the prediction accuracy, when compared to multiple baseline methods. We also develop a new evaluation metric that combines prediction accuracy with the closeness to experts' judgment. Our framework yields statistically significant results when evaluated on that metric.
IBM Federated Learning: an Enterprise Framework White Paper V0.1
Jul 22, 2020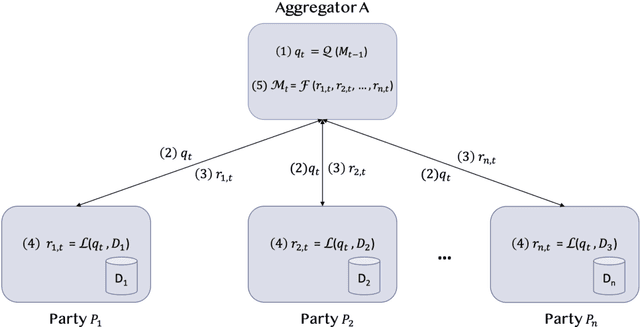
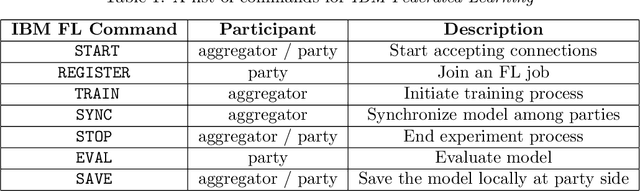
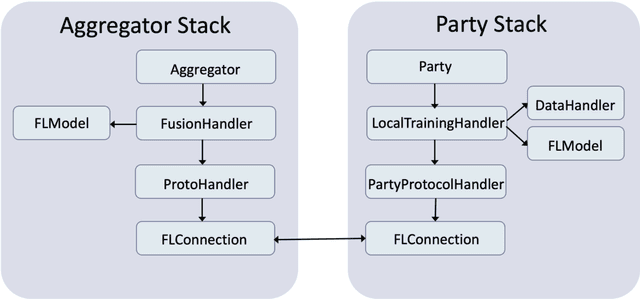
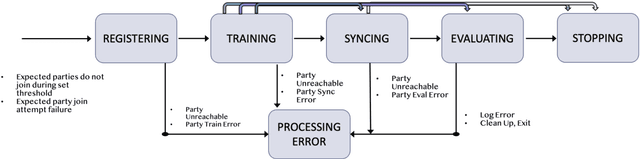
Federated Learning (FL) is an approach to conduct machine learning without centralizing training data in a single place, for reasons of privacy, confidentiality or data volume. However, solving federated machine learning problems raises issues above and beyond those of centralized machine learning. These issues include setting up communication infrastructure between parties, coordinating the learning process, integrating party results, understanding the characteristics of the training data sets of different participating parties, handling data heterogeneity, and operating with the absence of a verification data set. IBM Federated Learning provides infrastructure and coordination for federated learning. Data scientists can design and run federated learning jobs based on existing, centralized machine learning models and can provide high-level instructions on how to run the federation. The framework applies to both Deep Neural Networks as well as ``traditional'' approaches for the most common machine learning libraries. {\proj} enables data scientists to expand their scope from centralized to federated machine learning, minimizing the learning curve at the outset while also providing the flexibility to deploy to different compute environments and design custom fusion algorithms.