 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting In-Silicon Directed Evolution with Fine-Tuned Protein Language Model and Tree Search
Nov 19, 2025Protein evolution through amino acid sequence mutations is a cornerstone of life sciences. While current in-silicon directed evolution algorithms largely focus on designing heuristic search strategies, they overlook how to integrate the transformative protein language models, which encode rich evolutionary patterns, with reinforcement learning to learn to directly evolve proteins. To bridge this gap, we propose AlphaDE, a novel framework to optimize protein sequences by harnessing the innovative paradigms of large language models such as fine-tuning and test-time inference. First, AlphaDE fine-tunes pretrained protein language models using masked language modeling on homologous protein sequences to activate the evolutionary plausibility for the interested protein class. Second, AlphaDE introduces test-time inference based on Monte Carlo tree search, which effectively evolves proteins with evolutionary guidance from the fine-tuned protein language model. Extensive benchmark experiments show that AlphaDE remarkably outperforms previous state-of-the-art methods even with few-shot fine-tuning. A further case study demonstrates that AlphaDE supports condensing the protein sequence space of avGFP through computational evolution.
LMPNet for Weakly-supervised Keypoint Discovery
Jul 03, 2025



In this work, we explore the task of semantic object keypoint discovery weakly-supervised by only category labels. This is achieved by transforming discriminatively-trained intermediate layer filters into keypoint detectors. We begin by identifying three preferred characteristics of keypoint detectors: (i) spatially sparse activations, (ii) consistency and (iii) diversity. Instead of relying on hand-crafted loss terms, a novel computationally-efficient leaky max pooling (LMP) layer is proposed to explicitly encourage final conv-layer filters to learn "non-repeatable local patterns" that are well aligned with object keypoints. Informed by visualizations, a simple yet effective selection strategy is proposed to ensure consistent filter activations and attention mask-out is then applied to force the network to distribute its attention to the whole object instead of just the most discriminative region. For the final keypoint prediction, a learnable clustering layer is proposed to group keypoint proposals into keypoint predictions. The final model, named LMPNet, is highly interpretable in that it directly manipulates network filters to detect predefined concepts. Our experiments show that LMPNet can (i) automatically discover semantic keypoints that are robust to object pose and (ii) achieves strong prediction accuracy comparable to a supervised pose estimation model.
SmartHome-Bench: A Comprehensive Benchmark for Video Anomaly Detection in Smart Homes Using Multi-Modal Large Language Models
Jun 15, 2025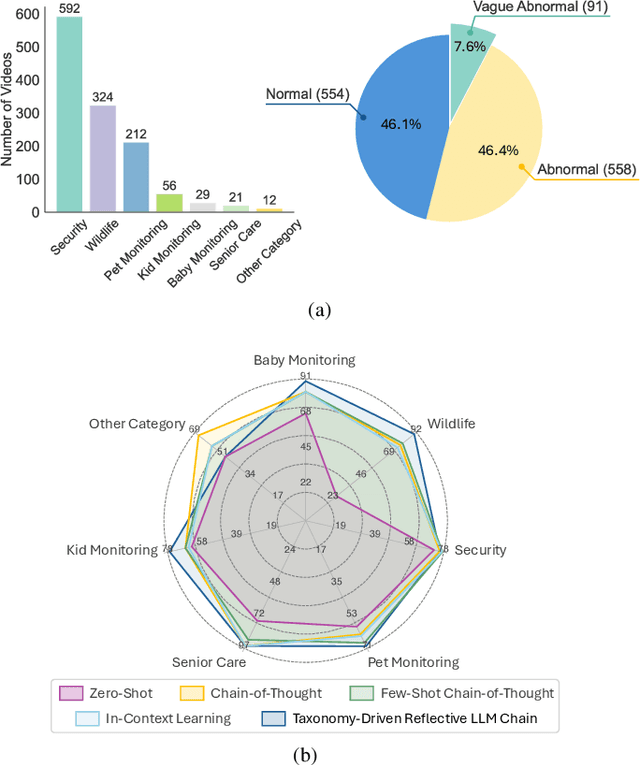
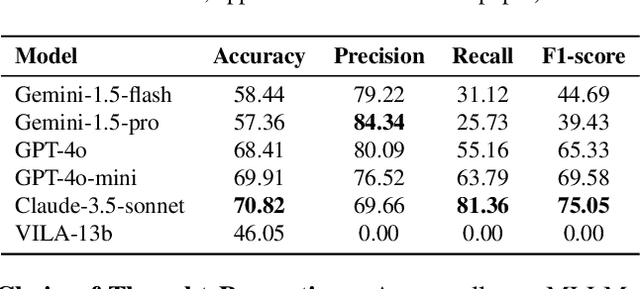

Video anomaly detection (VAD) is essential for enhancing safety and security by identifying unusual events across different environments. Existing VAD benchmarks, however, are primarily designed for general-purpose scenarios, neglecting the specific characteristics of smart home applications. To bridge this gap, we introduce SmartHome-Bench, the first comprehensive benchmark specially designed for evaluating VAD in smart home scenarios, focusing on the capabilities of multi-modal large language models (MLLMs). Our newly proposed benchmark consists of 1,203 videos recorded by smart home cameras, organized according to a novel anomaly taxonomy that includes seven categories, such as Wildlife, Senior Care, and Baby Monitoring. Each video is meticulously annotated with anomaly tags, detailed descriptions, and reasoning. We further investigate adaptation methods for MLLMs in VAD, assessing state-of-the-art closed-source and open-source models with various prompting techniques. Results reveal significant limitations in the current models' ability to detect video anomalies accurately. To address these limitations, we introduce the Taxonomy-Driven Reflective LLM Chain (TRLC), a new LLM chaining framework that achieves a notable 11.62% improvement in detection accuracy. The benchmark dataset and code are publicly available at https://github.com/Xinyi-0724/SmartHome-Bench-LLM.
OpenBA-V2: Reaching 77.3% High Compression Ratio with Fast Multi-Stage Pruning
May 09, 2024

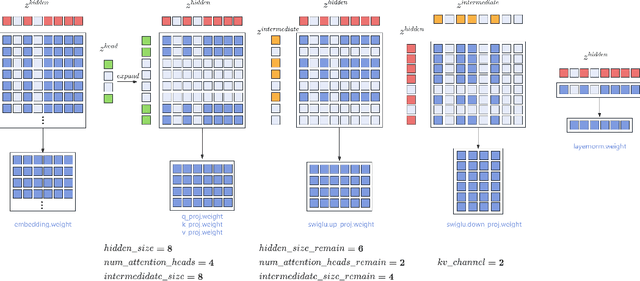
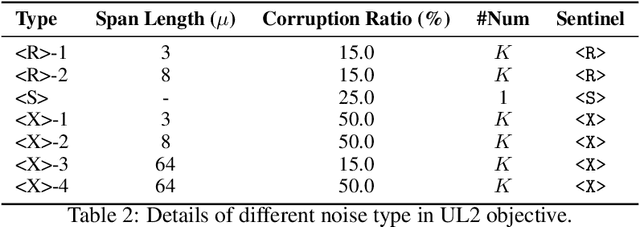
Large Language Models (LLMs) have played an important role in many fields due to their powerful capabilities.However, their massive number of parameters leads to high deployment requirements and incurs significant inference costs, which impedes their practical applications. Training smaller models is an effective way to address this problem. Therefore, we introduce OpenBA-V2, a 3.4B model derived from multi-stage compression and continual pre-training from the original 15B OpenBA model. OpenBA-V2 utilizes more data, more flexible training objectives, and techniques such as layer pruning, neural pruning, and vocabulary pruning to achieve a compression rate of 77.3\% with minimal performance loss. OpenBA-V2 demonstrates competitive performance compared to other open-source models of similar size, achieving results close to or on par with the 15B OpenBA model in downstream tasks such as common sense reasoning and Named Entity Recognition (NER). OpenBA-V2 illustrates that LLMs can be compressed into smaller ones with minimal performance loss by employing advanced training objectives and data strategies, which may help deploy LLMs in resource-limited scenarios.
OpenBA: An Open-sourced 15B Bilingual Asymmetric seq2seq Model Pre-trained from Scratch
Oct 01, 2023



Large language models (LLMs) with billions of parameters have demonstrated outstanding performance on various natural language processing tasks. This report presents OpenBA, an open-sourced 15B bilingual asymmetric seq2seq model, to contribute an LLM variant to the Chinese-oriented open-source model community. We enhance OpenBA with effective and efficient techniques as well as adopt a three-stage training strategy to train the model from scratch. Our solution can also achieve very competitive performance with only 380B tokens, which is better than LLaMA-70B on the BELEBELE benchmark, BLOOM-176B on the MMLU benchmark, GLM-130B on the C-Eval (hard) benchmark. This report provides the main details to pre-train an analogous model, including pre-training data processing, Bilingual Flan data collection, the empirical observations that inspire our model architecture design, training objectives of different stages, and other enhancement techniques. Additionally, we also provide the fine-tuning details of OpenBA on four downstream tasks. We have refactored our code to follow the design principles of the Huggingface Transformers Library, making it more convenient for developers to use, and released checkpoints of different training stages at https://huggingface.co/openBA. More details of our project are available at https://github.com/OpenNLG/openBA.git.
Incorporating Experts' Judgment into Machine Learning Models
Apr 29, 2023
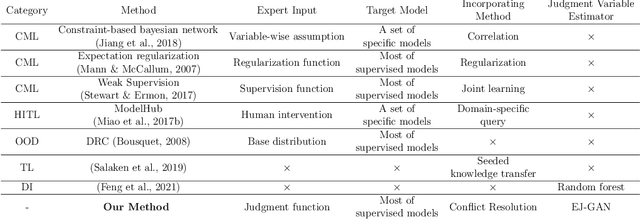
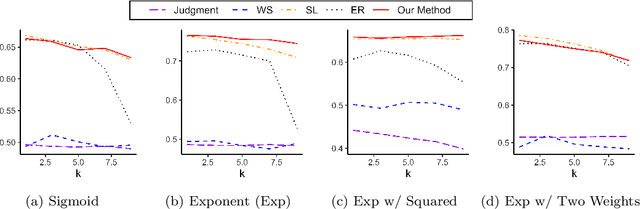
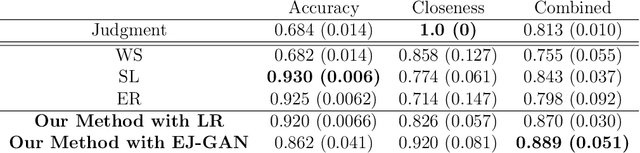
Machine learning (ML) models have been quite successful in predicting outcomes in many applications. However, in some cases, domain experts might have a judgment about the expected outcome that might conflict with the prediction of ML models. One main reason for this is that the training data might not be totally representative of the population. In this paper, we present a novel framework that aims at leveraging experts' judgment to mitigate the conflict. The underlying idea behind our framework is that we first determine, using a generative adversarial network, the degree of representation of an unlabeled data point in the training data. Then, based on such degree, we correct the \textcolor{black}{machine learning} model's prediction by incorporating the experts' judgment into it, where the higher that aforementioned degree of representation, the less the weight we put on the expert intuition that we add to our corrected output, and vice-versa. We perform multiple numerical experiments on synthetic data as well as two real-world case studies (one from the IT services industry and the other from the financial industry). All results show the effectiveness of our framework; it yields much higher closeness to the experts' judgment with minimal sacrifice in the prediction accuracy, when compared to multiple baseline methods. We also develop a new evaluation metric that combines prediction accuracy with the closeness to experts' judgment. Our framework yields statistically significant results when evaluated on that metric.
RenewNAT: Renewing Potential Translation for Non-Autoregressive Transformer
Mar 14, 2023



Non-autoregressive neural machine translation (NAT) models are proposed to accelerate the inference process while maintaining relatively high performance. However, existing NAT models are difficult to achieve the desired efficiency-quality trade-off. For one thing, fully NAT models with efficient inference perform inferior to their autoregressive counterparts. For another, iterative NAT models can, though, achieve comparable performance while diminishing the advantage of speed. In this paper, we propose RenewNAT, a flexible framework with high efficiency and effectiveness, to incorporate the merits of fully and iterative NAT models. RenewNAT first generates the potential translation results and then renews them in a single pass. It can achieve significant performance improvements at the same expense as traditional NAT models (without introducing additional model parameters and decoding latency). Experimental results on various translation benchmarks (e.g., \textbf{4} WMT) show that our framework consistently improves the performance of strong fully NAT methods (e.g., GLAT and DSLP) without additional speed overhead.
Reproducible and Portable Big Data Analytics in the Cloud
Dec 17, 2021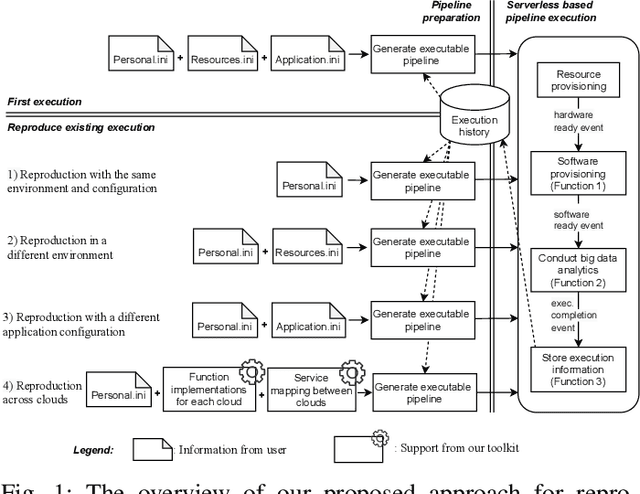
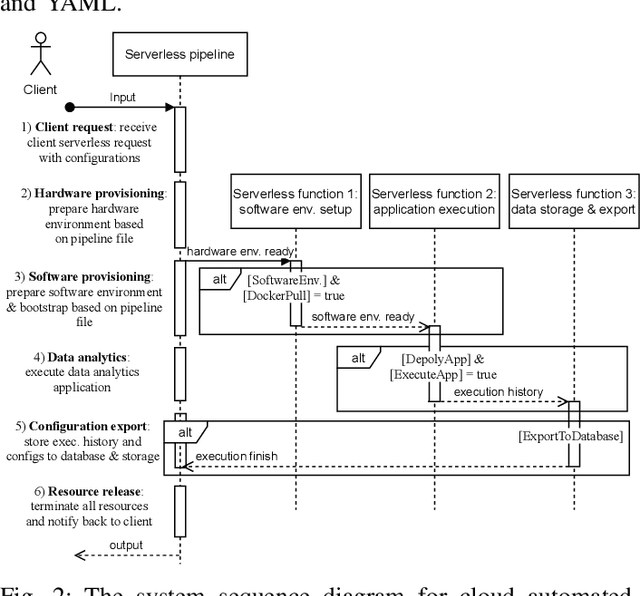
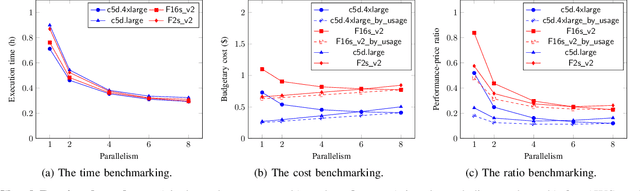
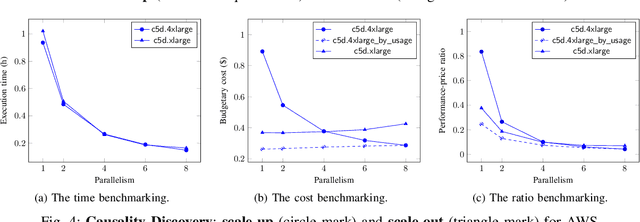
Cloud computing has become a major approach to enable reproducible computational experiments because of its support of on-demand hardware and software resource provisioning. Yet there are still two main difficulties in reproducing big data applications in the cloud. The first is how to automate end-to-end execution of big data analytics in the cloud including virtual distributed environment provisioning, network and security group setup, and big data analytics pipeline description and execution. The second is an application developed for one cloud, such as AWS or Azure, is difficult to reproduce in another cloud, a.k.a. vendor lock-in problem. To tackle these problems, we leverage serverless computing and containerization techniques for automatic scalable big data application execution and reproducibility, and utilize the adapter design pattern to enable application portability and reproducibility across different clouds. Based on the approach, we propose and develop an open-source toolkit that supports 1) on-demand distributed hardware and software environment provisioning, 2) automatic data and configuration storage for each execution, 3) flexible client modes based on user preferences, 4) execution history query, and 5) simple reproducibility of existing executions in the same environment or a different environment. We did extensive experiments on both AWS and Azure using three big data analytics applications that run on a virtual CPU/GPU cluster. Three main behaviors of our toolkit were benchmarked: i) execution overhead ratio for reproducibility support, ii) differences of reproducing the same application on AWS and Azure in terms of execution time, budgetary cost and cost-performance ratio, iii) differences between scale-out and scale-up approach for the same application on AWS and Azure.
Aligned to the Object, not to the Image: A Unified Pose-aligned Representation for Fine-grained Recognition
Sep 11, 2018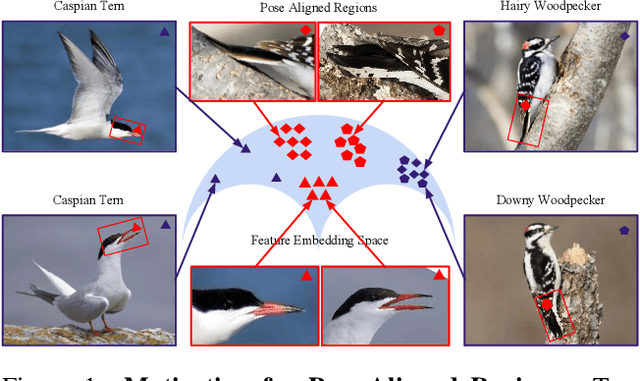
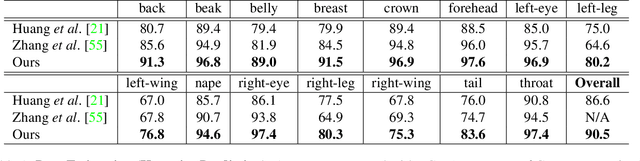


Dramatic appearance variation due to pose constitutes a great challenge in fine-grained recognition, one which recent methods using attention mechanisms or second-order statistics fail to adequately address. Modern CNNs typically lack an explicit understanding of object pose and are instead confused by entangled pose and appearance. In this paper, we propose a unified object representation built from a hierarchy of pose-aligned regions. Rather than representing an object by regions aligned to image axes, the proposed representation characterizes appearance relative to the object's pose using pose-aligned patches whose features are robust to variations in pose, scale and rotation. We propose an algorithm that performs pose estimation and forms the unified object representation as the concatenation of hierarchical pose-aligned regions features, which is then fed into a classification network. The proposed algorithm surpasses the performance of other approaches, increasing the state-of-the-art by nearly 2% on the widely-used CUB-200 dataset and by more than 8% on the much larger NABirds dataset. The effectiveness of this paradigm relative to competing methods suggests the critical importance of disentangling pose and appearance for continued progress in fine-grained recognition.
Neural Network Interpretation via Fine Grained Textual Summarization
Sep 06, 2018
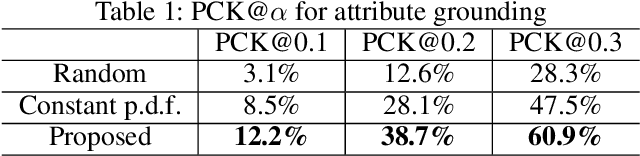
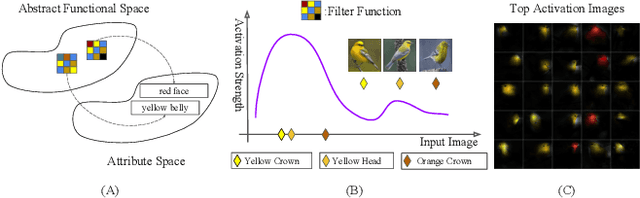

Current visualization based network interpretation methodssuffer from lacking semantic-level information. In this paper, we introduce the novel task of interpreting classification models using fine grained textual summarization. Along with the label prediction, the network will generate a sentence explaining its decision. Constructing a fully annotated dataset of filter|text pairs is unrealistic because of image to filter response function complexity. We instead propose a weakly-supervised learning algorithm leveraging off-the-shelf image caption annotations. Central to our algorithm is the filter-level attribute probability density function (p.d.f.), learned as a conditional probability through Bayesian inference with the input image and its feature map as latent variables. We show our algorithm faithfully reflects the features learned by the model using rigorous applications like attribute based image retrieval and unsupervised text grounding. We further show that the textual summarization process can help in understanding network failure patterns and can provide clues for further improvements.