 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality for Earth Science -- A Review on Time-series and Spatiotemporal Causality Methods
Apr 03, 2024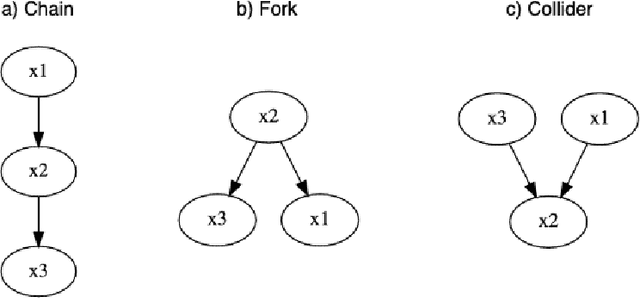

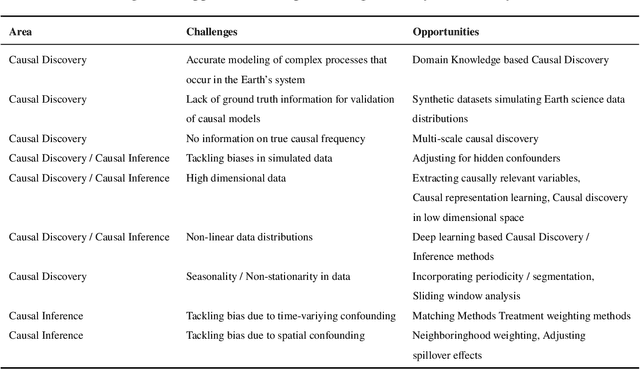
This survey paper covers the breadth and depth of time-series and spatiotemporal causality methods, and their applications in Earth Science. More specifically, the paper presents an overview of causal discovery and causal inference, explains the underlying causal assumptions, and enlists evaluation techniques and key terminologies of the domain area. The paper elicits the various state-of-the-art methods introduced for time-series and spatiotemporal causal analysis along with their strengths and limitations. The paper further describes the existing applications of several methods for answering specific Earth Science questions such as extreme weather events, sea level rise, teleconnections etc. This survey paper can serve as a primer for Data Science researchers interested in data-driven causal study as we share a list of resources, such as Earth Science datasets (synthetic, simulated and observational data) and open source tools for causal analysis. It will equally benefit the Earth Science community interested in taking an AI-driven approach to study the causality of different dynamic and thermodynamic processes as we present the open challenges and opportunities in performing causality-based Earth Science study.
MT-HCCAR: Multi-Task Deep Learning with Hierarchical Classification and Attention-based Regression for Cloud Property Retrieval
Jan 29, 2024In the realm of Earth science, effective cloud property retrieval, encompassing cloud masking, cloud phase classification, and cloud optical thickness (COT) prediction, remains pivotal. Traditional methodologies necessitate distinct models for each sensor instrument due to their unique spectral characteristics. Recent strides in Earth Science research have embraced machine learning and deep learning techniques to extract features from satellite datasets' spectral observations. However, prevailing approaches lack novel architectures accounting for hierarchical relationships among retrieval tasks. Moreover, considering the spectral diversity among existing sensors, the development of models with robust generalization capabilities over different sensor datasets is imperative. Surprisingly, there is a dearth of methodologies addressing the selection of an optimal model for diverse datasets. In response, this paper introduces MT-HCCAR, an end-to-end deep learning model employing multi-task learning to simultaneously tackle cloud masking, cloud phase retrieval (classification tasks), and COT prediction (a regression task). The MT-HCCAR integrates a hierarchical classification network (HC) and a classification-assisted attention-based regression network (CAR), enhancing precision and robustness in cloud labeling and COT prediction. Additionally, a comprehensive model selection method rooted in K-fold cross-validation, one standard error rule, and two introduced performance scores is proposed to select the optimal model over three simulated satellite datasets OCI, VIIRS, and ABI. The experiments comparing MT-HCCAR with baseline methods, the ablation studies, and the model selection affirm the superiority and the generalization capabilities of MT-HCCAR.
Reproducible and Portable Big Data Analytics in the Cloud
Dec 17, 2021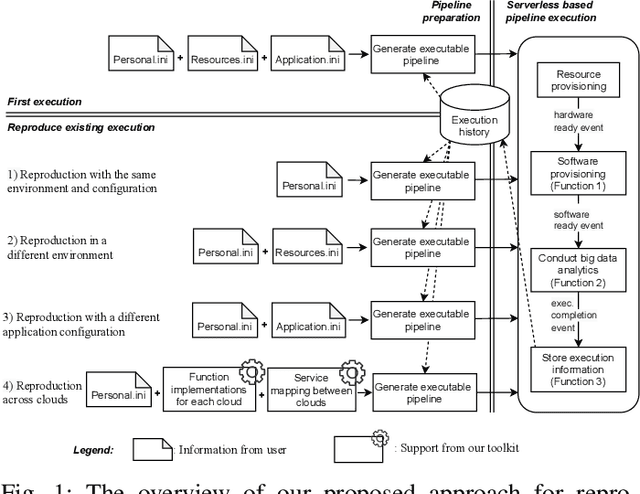
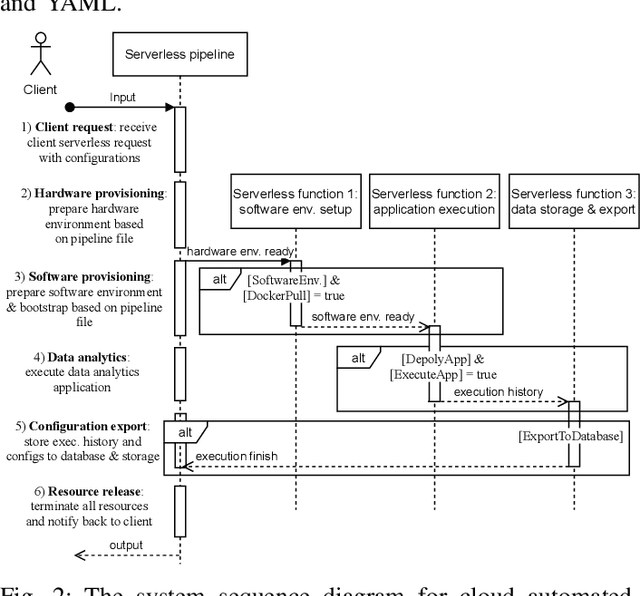
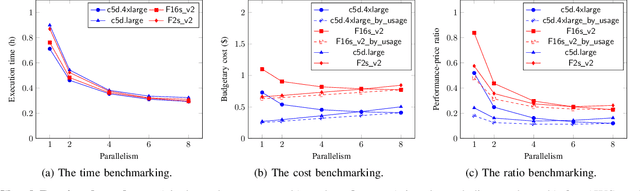
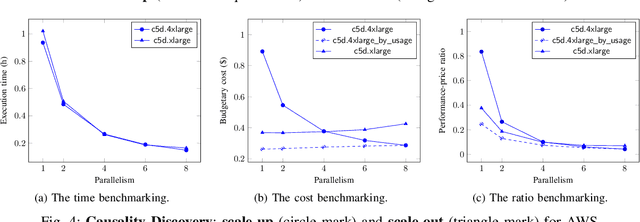
Cloud computing has become a major approach to enable reproducible computational experiments because of its support of on-demand hardware and software resource provisioning. Yet there are still two main difficulties in reproducing big data applications in the cloud. The first is how to automate end-to-end execution of big data analytics in the cloud including virtual distributed environment provisioning, network and security group setup, and big data analytics pipeline description and execution. The second is an application developed for one cloud, such as AWS or Azure, is difficult to reproduce in another cloud, a.k.a. vendor lock-in problem. To tackle these problems, we leverage serverless computing and containerization techniques for automatic scalable big data application execution and reproducibility, and utilize the adapter design pattern to enable application portability and reproducibility across different clouds. Based on the approach, we propose and develop an open-source toolkit that supports 1) on-demand distributed hardware and software environment provisioning, 2) automatic data and configuration storage for each execution, 3) flexible client modes based on user preferences, 4) execution history query, and 5) simple reproducibility of existing executions in the same environment or a different environment. We did extensive experiments on both AWS and Azure using three big data analytics applications that run on a virtual CPU/GPU cluster. Three main behaviors of our toolkit were benchmarked: i) execution overhead ratio for reproducibility support, ii) differences of reproducing the same application on AWS and Azure in terms of execution time, budgetary cost and cost-performance ratio, iii) differences between scale-out and scale-up approach for the same application on AWS and Azure.