 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Edge-Cloud Integrated Framework for Flexible and Dynamic Stream Analytics
May 11, 2022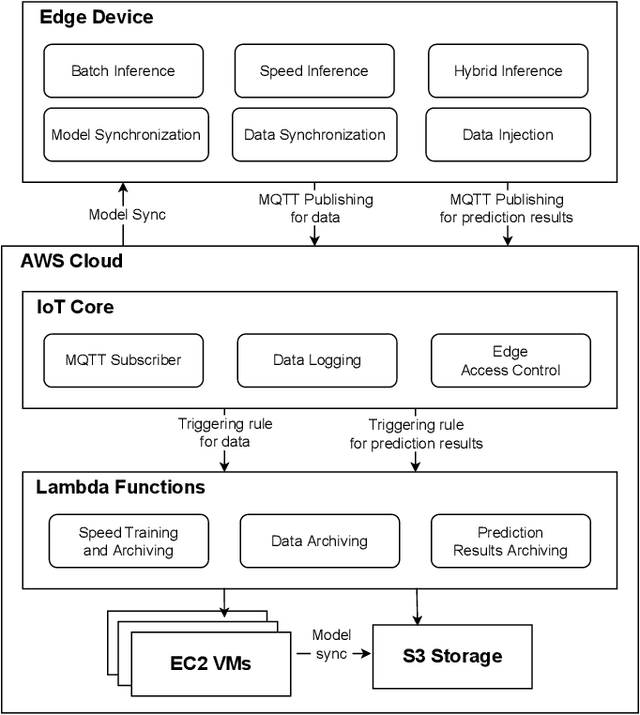
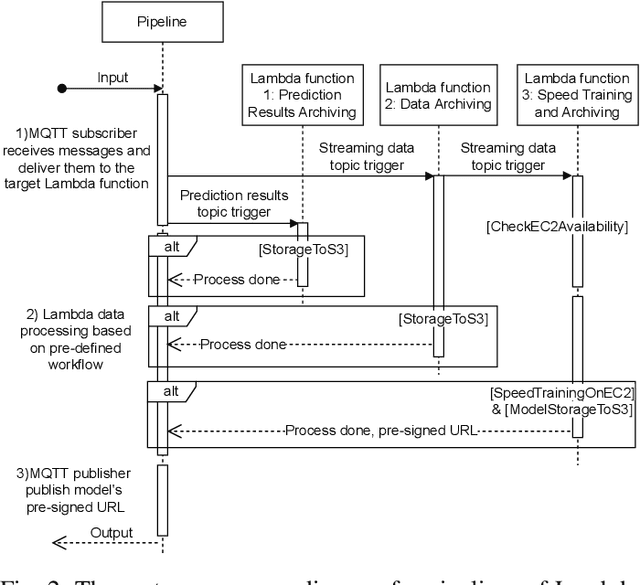
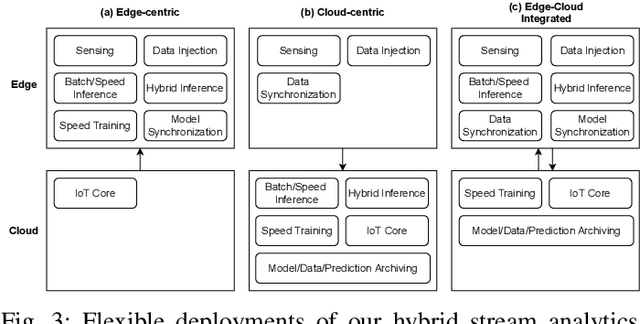
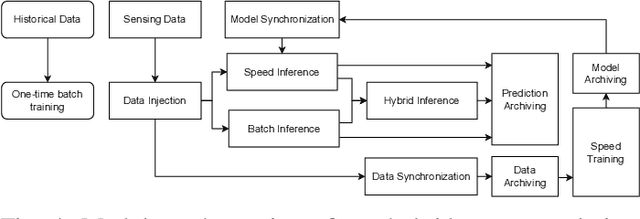
With the popularity of Internet of Things (IoT), edge computing and cloud computing, more and more stream analytics applications are being developed including real-time trend prediction and object detection on top of IoT sensing data. One popular type of stream analytics is the recurrent neural network (RNN) deep learning model based time series or sequence data prediction and forecasting. Different from traditional analytics that assumes data to be processed are available ahead of time and will not change, stream analytics deals with data that are being generated continuously and data trend/distribution could change (aka concept drift), which will cause prediction/forecasting accuracy to drop over time. One other challenge is to find the best resource provisioning for stream analytics to achieve good overall latency. In this paper, we study how to best leverage edge and cloud resources to achieve better accuracy and latency for RNN-based stream analytics. We propose a novel edge-cloud integrated framework for hybrid stream analytics that support low latency inference on the edge and high capacity training on the cloud. We study the flexible deployment of our hybrid learning framework, namely edge-centric, cloud-centric and edge-cloud integrated. Further, our hybrid learning framework can dynamically combine inference results from an RNN model pre-trained based on historical data and another RNN model re-trained periodically based on the most recent data. Using real-world and simulated stream datasets, our experiments show the proposed edge-cloud deployment is the best among all three deployment types in terms of latency. For accuracy, the experiments show our dynamic learning approach performs the best among all learning approaches for all three concept drift scenarios.
Reproducible and Portable Big Data Analytics in the Cloud
Dec 17, 2021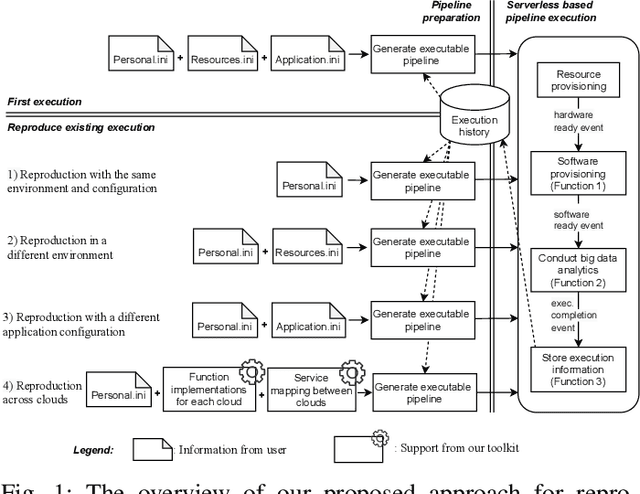
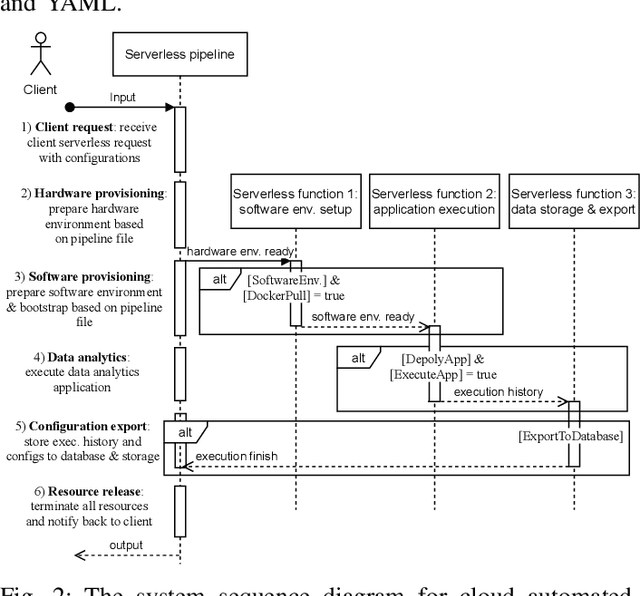
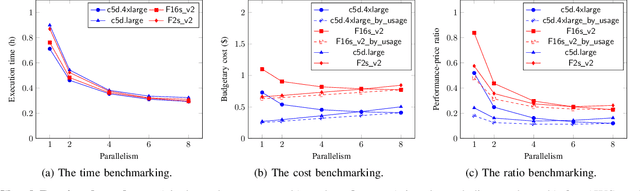
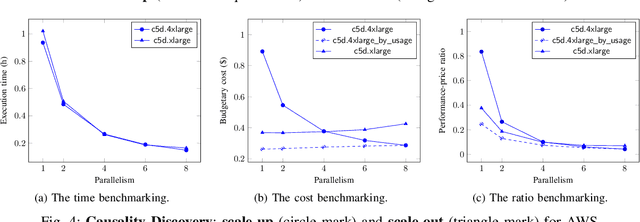
Cloud computing has become a major approach to enable reproducible computational experiments because of its support of on-demand hardware and software resource provisioning. Yet there are still two main difficulties in reproducing big data applications in the cloud. The first is how to automate end-to-end execution of big data analytics in the cloud including virtual distributed environment provisioning, network and security group setup, and big data analytics pipeline description and execution. The second is an application developed for one cloud, such as AWS or Azure, is difficult to reproduce in another cloud, a.k.a. vendor lock-in problem. To tackle these problems, we leverage serverless computing and containerization techniques for automatic scalable big data application execution and reproducibility, and utilize the adapter design pattern to enable application portability and reproducibility across different clouds. Based on the approach, we propose and develop an open-source toolkit that supports 1) on-demand distributed hardware and software environment provisioning, 2) automatic data and configuration storage for each execution, 3) flexible client modes based on user preferences, 4) execution history query, and 5) simple reproducibility of existing executions in the same environment or a different environment. We did extensive experiments on both AWS and Azure using three big data analytics applications that run on a virtual CPU/GPU cluster. Three main behaviors of our toolkit were benchmarked: i) execution overhead ratio for reproducibility support, ii) differences of reproducing the same application on AWS and Azure in terms of execution time, budgetary cost and cost-performance ratio, iii) differences between scale-out and scale-up approach for the same application on AWS and Azure.