 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuasiNav: Asymmetric Cost-Aware Navigation Planning with Constrained Quasimetric Reinforcement Learning
Oct 22, 2024Autonomous navigation in unstructured outdoor environments is inherently challenging due to the presence of asymmetric traversal costs, such as varying energy expenditures for uphill versus downhill movement. Traditional reinforcement learning methods often assume symmetric costs, which can lead to suboptimal navigation paths and increased safety risks in real-world scenarios. In this paper, we introduce QuasiNav, a novel reinforcement learning framework that integrates quasimetric embeddings to explicitly model asymmetric costs and guide efficient, safe navigation. QuasiNav formulates the navigation problem as a constrained Markov decision process (CMDP) and employs quasimetric embeddings to capture directionally dependent costs, allowing for a more accurate representation of the terrain. This approach is combined with adaptive constraint tightening within a constrained policy optimization framework to dynamically enforce safety constraints during learning. We validate QuasiNav across three challenging navigation scenarios-undulating terrains, asymmetric hill traversal, and directionally dependent terrain traversal-demonstrating its effectiveness in both simulated and real-world environments. Experimental results show that QuasiNav significantly outperforms conventional methods, achieving higher success rates, improved energy efficiency, and better adherence to safety constraints.
SERN: Simulation-Enhanced Realistic Navigation for Multi-Agent Robotic Systems in Contested Environments
Oct 22, 2024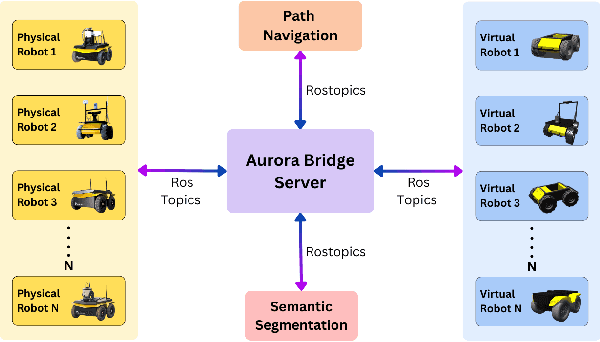
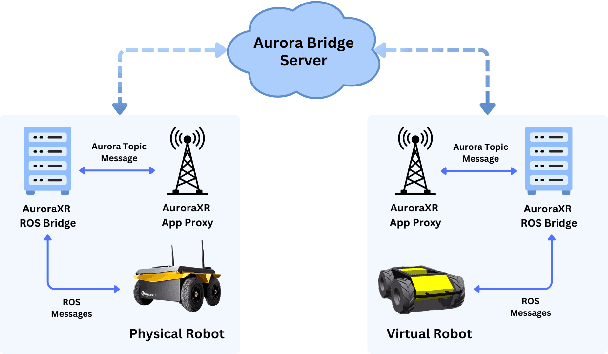
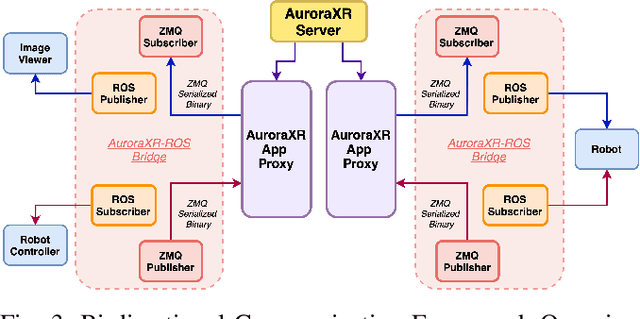
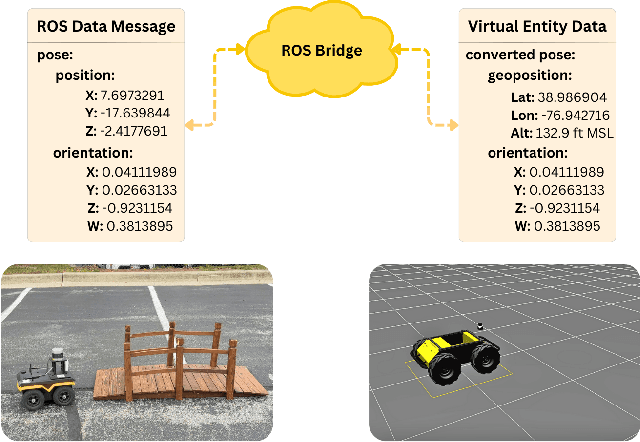
The increasing deployment of autonomous systems in complex environments necessitates efficient communication and task completion among multiple agents. This paper presents SERN (Simulation-Enhanced Realistic Navigation), a novel framework integrating virtual and physical environments for real-time collaborative decision-making in multi-robot systems. SERN addresses key challenges in asset deployment and coordination through a bi-directional communication framework using the AuroraXR ROS Bridge. Our approach advances the SOTA through accurate real-world representation in virtual environments using Unity high-fidelity simulator; synchronization of physical and virtual robot movements; efficient ROS data distribution between remote locations; and integration of SOTA semantic segmentation for enhanced environmental perception. Our evaluations show a 15% to 24% improvement in latency and up to a 15% increase in processing efficiency compared to traditional ROS setups. Real-world and virtual simulation experiments with multiple robots demonstrate synchronization accuracy, achieving less than 5 cm positional error and under 2-degree rotational error. These results highlight SERN's potential to enhance situational awareness and multi-agent coordination in diverse, contested environments.
TopoNav: Topological Navigation for Efficient Exploration in Sparse Reward Environments
Feb 06, 2024
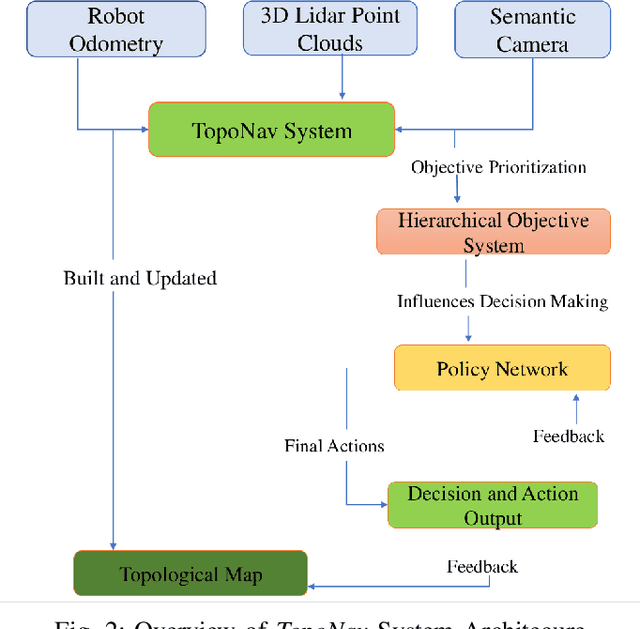


Autonomous robots exploring unknown areas face a significant challenge -- navigating effectively without prior maps and with limited external feedback. This challenge intensifies in sparse reward environments, where traditional exploration techniques often fail. In this paper, we introduce TopoNav, a novel framework that empowers robots to overcome these constraints and achieve efficient, adaptable, and goal-oriented exploration. TopoNav's fundamental building blocks are active topological mapping, intrinsic reward mechanisms, and hierarchical objective prioritization. Throughout its exploration, TopoNav constructs a dynamic topological map that captures key locations and pathways. It utilizes intrinsic rewards to guide the robot towards designated sub-goals within this map, fostering structured exploration even in sparse reward settings. To ensure efficient navigation, TopoNav employs the Hierarchical Objective-Driven Active Topologies framework, enabling the robot to prioritize immediate tasks like obstacle avoidance while maintaining focus on the overall goal. We demonstrate TopoNav's effectiveness in simulated environments that replicate real-world conditions. Our results reveal significant improvements in exploration efficiency, navigational accuracy, and adaptability to unforeseen obstacles, showcasing its potential to revolutionize autonomous exploration in a wide range of applications, including search and rescue, environmental monitoring, and planetary exploration.
HeteroEdge: Addressing Asymmetry in Heterogeneous Collaborative Autonomous Systems
May 05, 2023



Gathering knowledge about surroundings and generating situational awareness for IoT devices is of utmost importance for systems developed for smart urban and uncontested environments. For example, a large-area surveillance system is typically equipped with multi-modal sensors such as cameras and LIDARs and is required to execute deep learning algorithms for action, face, behavior, and object recognition. However, these systems face power and memory constraints due to their ubiquitous nature, making it crucial to optimize data processing, deep learning algorithm input, and model inference communication. In this paper, we propose a self-adaptive optimization framework for a testbed comprising two Unmanned Ground Vehicles (UGVs) and two NVIDIA Jetson devices. This framework efficiently manages multiple tasks (storage, processing, computation, transmission, inference) on heterogeneous nodes concurrently. It involves compressing and masking input image frames, identifying similar frames, and profiling devices to obtain boundary conditions for optimization.. Finally, we propose and optimize a novel parameter split-ratio, which indicates the proportion of the data required to be offloaded to another device while considering the networking bandwidth, busy factor, memory (CPU, GPU, RAM), and power constraints of the devices in the testbed. Our evaluations captured while executing multiple tasks (e.g., PoseNet, SegNet, ImageNet, DetectNet, DepthNet) simultaneously, reveal that executing 70% (split-ratio=70%) of the data on the auxiliary node minimizes the offloading latency by approx. 33% (18.7 ms/image to 12.5 ms/image) and the total operation time by approx. 47% (69.32s to 36.43s) compared to the baseline configuration (executing on the primary node).
An Edge-Cloud Integrated Framework for Flexible and Dynamic Stream Analytics
May 11, 2022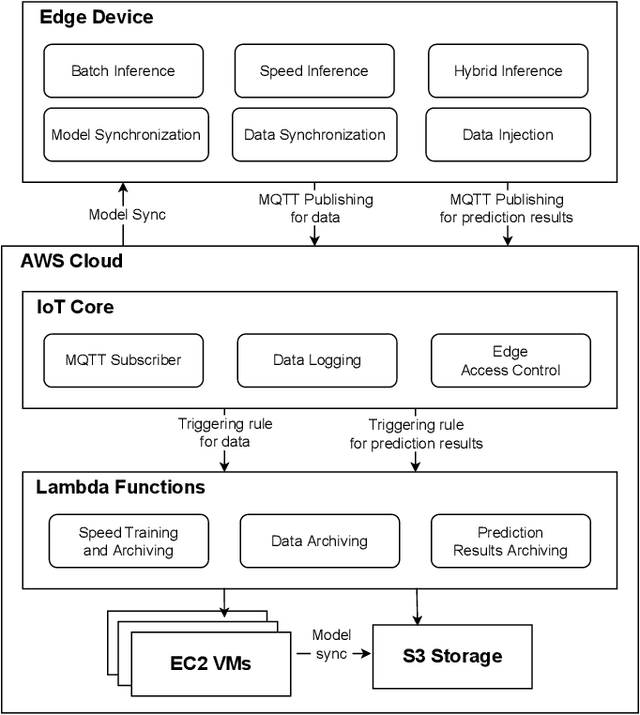
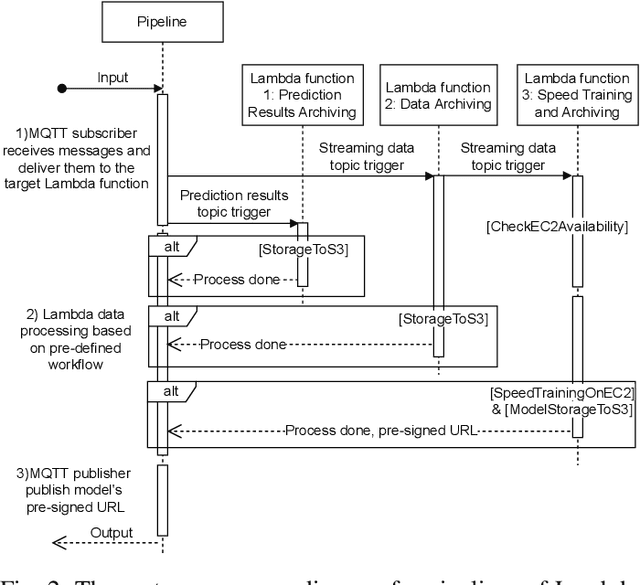
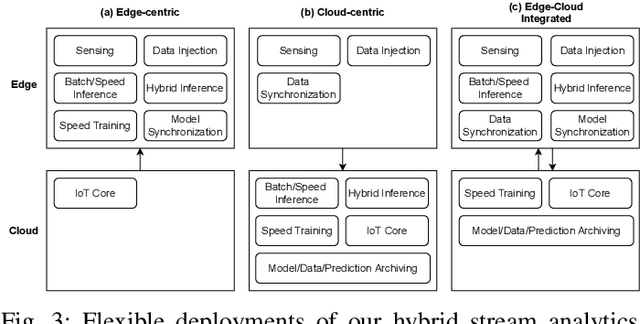
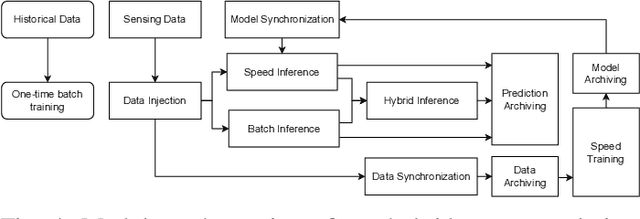
With the popularity of Internet of Things (IoT), edge computing and cloud computing, more and more stream analytics applications are being developed including real-time trend prediction and object detection on top of IoT sensing data. One popular type of stream analytics is the recurrent neural network (RNN) deep learning model based time series or sequence data prediction and forecasting. Different from traditional analytics that assumes data to be processed are available ahead of time and will not change, stream analytics deals with data that are being generated continuously and data trend/distribution could change (aka concept drift), which will cause prediction/forecasting accuracy to drop over time. One other challenge is to find the best resource provisioning for stream analytics to achieve good overall latency. In this paper, we study how to best leverage edge and cloud resources to achieve better accuracy and latency for RNN-based stream analytics. We propose a novel edge-cloud integrated framework for hybrid stream analytics that support low latency inference on the edge and high capacity training on the cloud. We study the flexible deployment of our hybrid learning framework, namely edge-centric, cloud-centric and edge-cloud integrated. Further, our hybrid learning framework can dynamically combine inference results from an RNN model pre-trained based on historical data and another RNN model re-trained periodically based on the most recent data. Using real-world and simulated stream datasets, our experiments show the proposed edge-cloud deployment is the best among all three deployment types in terms of latency. For accuracy, the experiments show our dynamic learning approach performs the best among all learning approaches for all three concept drift scenarios.
Top-K Ranking Deep Contextual Bandits for Information Selection Systems
Jan 28, 2022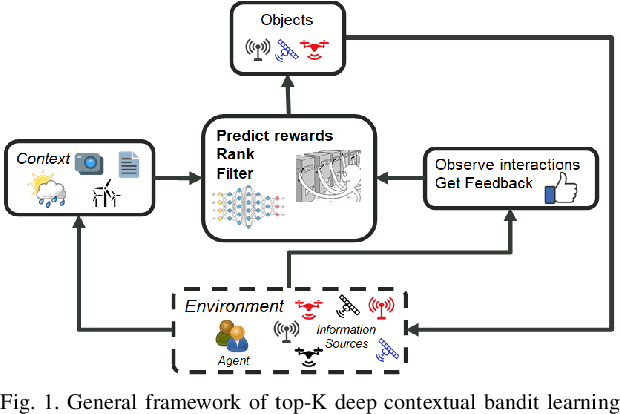

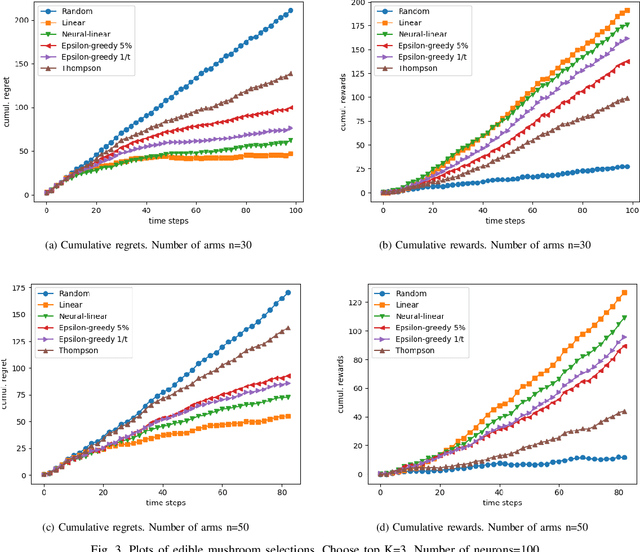
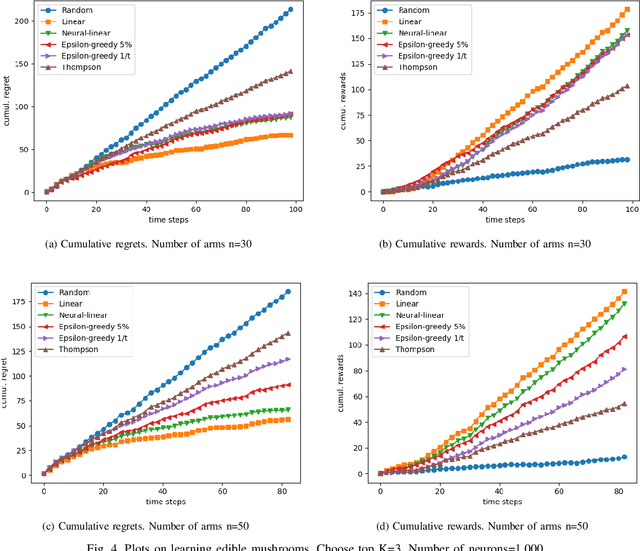
In today's technology environment, information is abundant, dynamic, and heterogeneous in nature. Automated filtering and prioritization of information is based on the distinction between whether the information adds substantial value toward one's goal or not. Contextual multi-armed bandit has been widely used for learning to filter contents and prioritize according to user interest or relevance. Learn-to-Rank technique optimizes the relevance ranking on items, allowing the contents to be selected accordingly. We propose a novel approach to top-K rankings under the contextual multi-armed bandit framework. We model the stochastic reward function with a neural network to allow non-linear approximation to learn the relationship between rewards and contexts. We demonstrate the approach and evaluate the the performance of learning from the experiments using real world data sets in simulated scenarios. Empirical results show that this approach performs well under the complexity of a reward structure and high dimensional contextual features.
Reproducible and Portable Big Data Analytics in the Cloud
Dec 17, 2021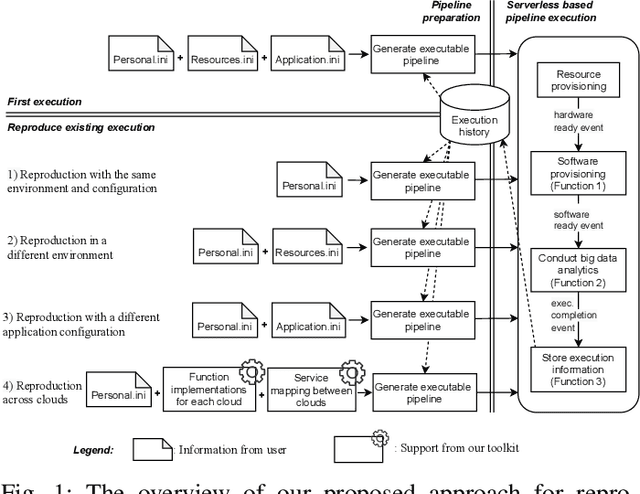
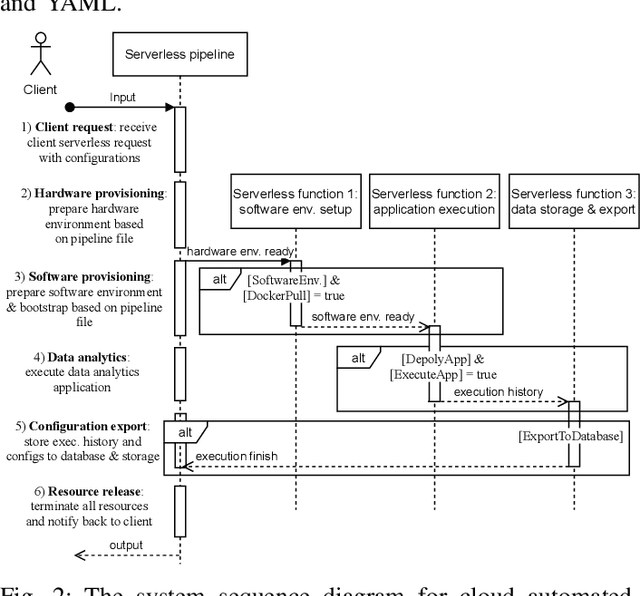
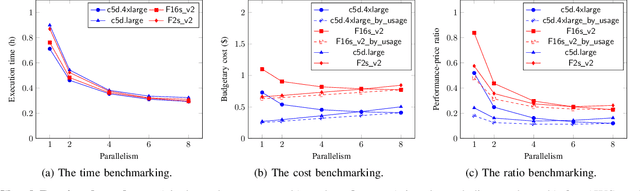
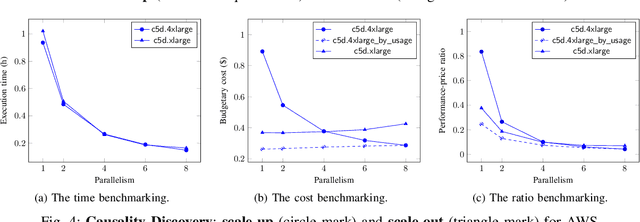
Cloud computing has become a major approach to enable reproducible computational experiments because of its support of on-demand hardware and software resource provisioning. Yet there are still two main difficulties in reproducing big data applications in the cloud. The first is how to automate end-to-end execution of big data analytics in the cloud including virtual distributed environment provisioning, network and security group setup, and big data analytics pipeline description and execution. The second is an application developed for one cloud, such as AWS or Azure, is difficult to reproduce in another cloud, a.k.a. vendor lock-in problem. To tackle these problems, we leverage serverless computing and containerization techniques for automatic scalable big data application execution and reproducibility, and utilize the adapter design pattern to enable application portability and reproducibility across different clouds. Based on the approach, we propose and develop an open-source toolkit that supports 1) on-demand distributed hardware and software environment provisioning, 2) automatic data and configuration storage for each execution, 3) flexible client modes based on user preferences, 4) execution history query, and 5) simple reproducibility of existing executions in the same environment or a different environment. We did extensive experiments on both AWS and Azure using three big data analytics applications that run on a virtual CPU/GPU cluster. Three main behaviors of our toolkit were benchmarked: i) execution overhead ratio for reproducibility support, ii) differences of reproducing the same application on AWS and Azure in terms of execution time, budgetary cost and cost-performance ratio, iii) differences between scale-out and scale-up approach for the same application on AWS and Azure.
Deep Upper Confidence Bound Algorithm for Contextual Bandit Ranking of Information Selection
Oct 08, 2021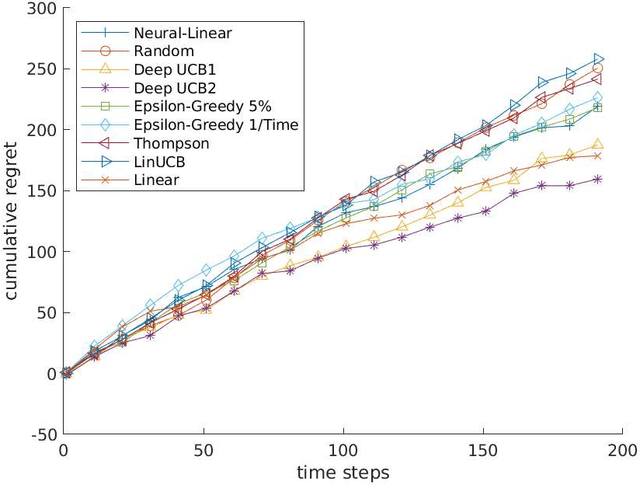
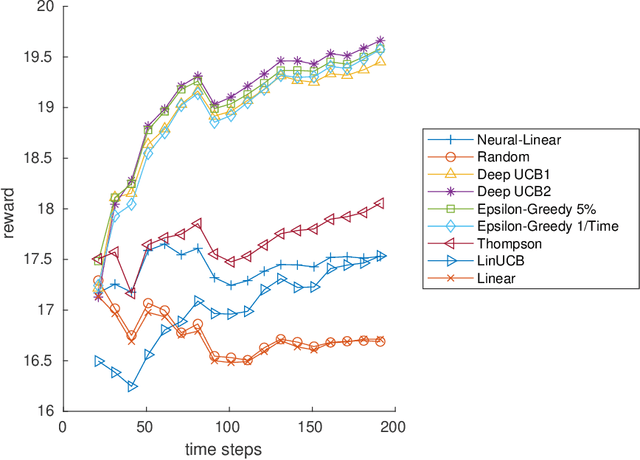
Contextual multi-armed bandits (CMAB) have been widely used for learning to filter and prioritize information according to a user's interest. In this work, we analyze top-K ranking under the CMAB framework where the top-K arms are chosen iteratively to maximize a reward. The context, which represents a set of observable factors related to the user, is used to increase prediction accuracy compared to a standard multi-armed bandit. Contextual bandit methods have mostly been studied under strict linearity assumptions, but we drop that assumption and learn non-linear stochastic reward functions with deep neural networks. We introduce a novel algorithm called the Deep Upper Confidence Bound (UCB) algorithm. Deep UCB balances exploration and exploitation with a separate neural network to model the learning convergence. We compare the performance of many bandit algorithms varying K over real-world data sets with high-dimensional data and non-linear reward functions. Empirical results show that the performance of Deep UCB often outperforms though it is sensitive to the problem and reward setup. Additionally, we prove theoretical regret bounds on Deep UCB giving convergence to optimality for the weak class of CMAB problems.