 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Varying Causal Treatment for Quantifying the Causal Effect of Short-Term Variations on Arctic Sea Ice Dynamics
Jan 25, 2026Quantifying the causal relationship between ice melt and freshwater distribution is critical, as these complex interactions manifest as regional fluctuations in sea surface height (SSH). Leveraging SSH as a proxy for sea ice dynamics enables improved understanding of the feedback mechanisms driving polar climate change and global sea-level rise. However, conventional deep learning models often struggle with reliable treatment effect estimation in spatiotemporal settings due to unobserved confounders and the absence of physical constraints. To address these challenges, we propose the Knowledge-Guided Causal Model Variational Autoencoder (KGCM-VAE) to quantify causal mechanisms between sea ice thickness and SSH. The proposed framework integrates a velocity modulation scheme in which smoothed velocity signals are dynamically amplified via a sigmoid function governed by SSH transitions to generate physically grounded causal treatments. In addition, the model incorporates Maximum Mean Discrepancy (MMD) to balance treated and control covariate distributions in the latent space, along with a causal adjacency-constrained decoder to ensure alignment with established physical structures. Experimental results on both synthetic and real-world Arctic datasets demonstrate that KGCM-VAE achieves superior PEHE compared to state-of-the-art benchmarks. Ablation studies further confirm the effectiveness of the approach, showing that the joint application of MMD and causal adjacency constraints yields a 1.88\% reduction in estimation error.
PhysE-Inv: A Physics-Encoded Inverse Modeling approach for Arctic Snow Depth Prediction
Jan 23, 2026The accurate estimation of Arctic snow depth ($h_s$) remains a critical time-varying inverse problem due to the extreme scarcity and noise inherent in associated sea ice parameters. Existing process-based and data-driven models are either highly sensitive to sparse data or lack the physical interpretability required for climate-critical applications. To address this gap, we introduce PhysE-Inv, a novel framework that integrates a sophisticated sequential architecture, an LSTM Encoder-Decoder with Multi-head Attention and physics-guided contrastive learning, with physics-guided inference.Our core innovation lies in a surjective, physics-constrained inversion methodology. This methodology first leverages the hydrostatic balance forward model as a target-formulation proxy, enabling effective learning in the absence of direct $h_s$ ground truth; second, it uses reconstruction physics regularization over a latent space to dynamically discover hidden physical parameters from noisy, incomplete time-series input. Evaluated against state-of-the-art baselines, PhysE-Inv significantly improves prediction performance, reducing error by 20\% while demonstrating superior physical consistency and resilience to data sparsity compared to empirical methods. This approach pioneers a path for noise-tolerant, interpretable inverse modeling, with wide applicability in geospatial and cryospheric domains.
FAConvLSTM: Factorized-Attention ConvLSTM for Efficient Feature Extraction in Multivariate Climate Data
Jan 16, 2026Learning physically meaningful spatiotemporal representations from high-resolution multivariate Earth observation data is challenging due to strong local dynamics, long-range teleconnections, multi-scale interactions, and nonstationarity. While ConvLSTM2D is a commonly used baseline, its dense convolutional gating incurs high computational cost and its strictly local receptive fields limit the modeling of long-range spatial structure and disentangled climate dynamics. To address these limitations, we propose FAConvLSTM, a Factorized-Attention ConvLSTM layer designed as a drop-in replacement for ConvLSTM2D that simultaneously improves efficiency, spatial expressiveness, and physical interpretability. FAConvLSTM factorizes recurrent gate computations using lightweight [1 times 1] bottlenecks and shared depthwise spatial mixing, substantially reducing channel complexity while preserving recurrent dynamics. Multi-scale dilated depthwise branches and squeeze-and-excitation recalibration enable efficient modeling of interacting physical processes across spatial scales, while peephole connections enhance temporal precision. To capture teleconnection-scale dependencies without incurring global attention cost, FAConvLSTM incorporates a lightweight axial spatial attention mechanism applied sparsely in time. A dedicated subspace head further produces compact per timestep embeddings refined through temporal self-attention with fixed seasonal positional encoding. Experiments on multivariate spatiotemporal climate data shows superiority demonstrating that FAConvLSTM yields more stable, interpretable, and robust latent representations than standard ConvLSTM, while significantly reducing computational overhead.
Learning Subglacial Bed Topography from Sparse Radar with Physics-Guided Residuals
Nov 18, 2025Accurate subglacial bed topography is essential for ice sheet modeling, yet radar observations are sparse and uneven. We propose a physics-guided residual learning framework that predicts bed thickness residuals over a BedMachine prior and reconstructs bed from the observed surface. A DeepLabV3+ decoder over a standard encoder (e.g.,ResNet-50) is trained with lightweight physics and data terms: multi-scale mass conservation, flow-aligned total variation, Laplacian damping, non-negativity of thickness, a ramped prior-consistency term, and a masked Huber fit to radar picks modulated by a confidence map. To measure real-world generalization, we adopt leakage-safe blockwise hold-outs (vertical/horizontal) with safety buffers and report metrics only on held-out cores. Across two Greenland sub-regions, our approach achieves strong test-core accuracy and high structural fidelity, outperforming U-Net, Attention U-Net, FPN, and a plain CNN. The residual-over-prior design, combined with physics, yields spatially coherent, physically plausible beds suitable for operational mapping under domain shift.
B-TGAT: A Bi-directional Temporal Graph Attention Transformer for Clustering Multivariate Spatiotemporal Data
Sep 16, 2025



Clustering high-dimensional multivariate spatiotemporal climate data is challenging due to complex temporal dependencies, evolving spatial interactions, and non-stationary dynamics. Conventional clustering methods, including recurrent and convolutional models, often struggle to capture both local and global temporal relationships while preserving spatial context. We present a time-distributed hybrid U-Net autoencoder that integrates a Bi-directional Temporal Graph Attention Transformer (B-TGAT) to guide efficient temporal clustering of multidimensional spatiotemporal climate datasets. The encoder and decoder are equipped with ConvLSTM2D modules that extract joint spatial--temporal features by modeling localized dynamics and spatial correlations over time, and skip connections that preserve multiscale spatial details during feature compression and reconstruction. At the bottleneck, B-TGAT integrates graph-based spatial modeling with attention-driven temporal encoding, enabling adaptive weighting of temporal neighbors and capturing both short and long-range dependencies across regions. This architecture produces discriminative latent embeddings optimized for clustering. Experiments on three distinct spatiotemporal climate datasets demonstrate superior cluster separability, temporal stability, and alignment with known climate transitions compared to state-of-the-art baselines. The integration of ConvLSTM2D, U-Net skip connections, and B-TGAT enhances temporal clustering performance while providing interpretable insights into complex spatiotemporal variability, advancing both methodological development and climate science applications.
Improving Greenland Bed Topography Mapping with Uncertainty-Aware Graph Learning on Sparse Radar Data
Sep 10, 2025Accurate maps of Greenland's subglacial bed are essential for sea-level projections, but radar observations are sparse and uneven. We introduce GraphTopoNet, a graph-learning framework that fuses heterogeneous supervision and explicitly models uncertainty via Monte Carlo dropout. Spatial graphs built from surface observables (elevation, velocity, mass balance) are augmented with gradient features and polynomial trends to capture both local variability and broad structure. To handle data gaps, we employ a hybrid loss that combines confidence-weighted radar supervision with dynamically balanced regularization. Applied to three Greenland subregions, GraphTopoNet outperforms interpolation, convolutional, and graph-based baselines, reducing error by up to 60 percent while preserving fine-scale glacial features. The resulting bed maps improve reliability for operational modeling, supporting agencies engaged in climate forecasting and policy. More broadly, GraphTopoNet shows how graph machine learning can convert sparse, uncertain geophysical observations into actionable knowledge at continental scale.
Cloud Optical Thickness Retrievals Using Angle Invariant Attention Based Deep Learning Models
May 30, 2025Cloud Optical Thickness (COT) is a critical cloud property influencing Earth's climate, weather, and radiation budget. Satellite radiance measurements enable global COT retrieval, but challenges like 3D cloud effects, viewing angles, and atmospheric interference must be addressed to ensure accurate estimation. Traditionally, the Independent Pixel Approximation (IPA) method, which treats individual pixels independently, has been used for COT estimation. However, IPA introduces significant bias due to its simplified assumptions. Recently, deep learning-based models have shown improved performance over IPA but lack robustness, as they are sensitive to variations in radiance intensity, distortions, and cloud shadows. These models also introduce substantial errors in COT estimation under different solar and viewing zenith angles. To address these challenges, we propose a novel angle-invariant, attention-based deep model called Cloud-Attention-Net with Angle Coding (CAAC). Our model leverages attention mechanisms and angle embeddings to account for satellite viewing geometry and 3D radiative transfer effects, enabling more accurate retrieval of COT. Additionally, our multi-angle training strategy ensures angle invariance. Through comprehensive experiments, we demonstrate that CAAC significantly outperforms existing state-of-the-art deep learning models, reducing cloud property retrieval errors by at least a factor of nine.
DeepTopoNet: A Framework for Subglacial Topography Estimation on the Greenland Ice Sheets
May 29, 2025Understanding Greenland's subglacial topography is critical for projecting the future mass loss of the ice sheet and its contribution to global sea-level rise. However, the complex and sparse nature of observational data, particularly information about the bed topography under the ice sheet, significantly increases the uncertainty in model projections. Bed topography is traditionally measured by airborne ice-penetrating radar that measures the ice thickness directly underneath the aircraft, leaving data gap of tens of kilometers in between flight lines. This study introduces a deep learning framework, which we call as DeepTopoNet, that integrates radar-derived ice thickness observations and BedMachine Greenland data through a novel dynamic loss-balancing mechanism. Among all efforts to reconstruct bed topography, BedMachine has emerged as one of the most widely used datasets, combining mass conservation principles and ice thickness measurements to generate high-resolution bed elevation estimates. The proposed loss function adaptively adjusts the weighting between radar and BedMachine data, ensuring robustness in areas with limited radar coverage while leveraging the high spatial resolution of BedMachine predictions i.e. bed estimates. Our approach incorporates gradient-based and trend surface features to enhance model performance and utilizes a CNN architecture designed for subgrid-scale predictions. By systematically testing on the Upernavik Isstr{\o}m) region, the model achieves high accuracy, outperforming baseline methods in reconstructing subglacial terrain. This work demonstrates the potential of deep learning in bridging observational gaps, providing a scalable and efficient solution to inferring subglacial topography.
BACON: A fully explainable AI model with graded logic for decision making problems
May 20, 2025As machine learning models and autonomous agents are increasingly deployed in high-stakes, real-world domains such as healthcare, security, finance, and robotics, the need for transparent and trustworthy explanations has become critical. To ensure end-to-end transparency of AI decisions, we need models that are not only accurate but also fully explainable and human-tunable. We introduce BACON, a novel framework for automatically training explainable AI models for decision making problems using graded logic. BACON achieves high predictive accuracy while offering full structural transparency and precise, logic-based symbolic explanations, enabling effective human-AI collaboration and expert-guided refinement. We evaluate BACON with a diverse set of scenarios: classic Boolean approximation, Iris flower classification, house purchasing decisions and breast cancer diagnosis. In each case, BACON provides high-performance models while producing compact, human-verifiable decision logic. These results demonstrate BACON's potential as a practical and principled approach for delivering crisp, trustworthy explainable AI.
Enhancing Satellite Object Localization with Dilated Convolutions and Attention-aided Spatial Pooling
May 08, 2025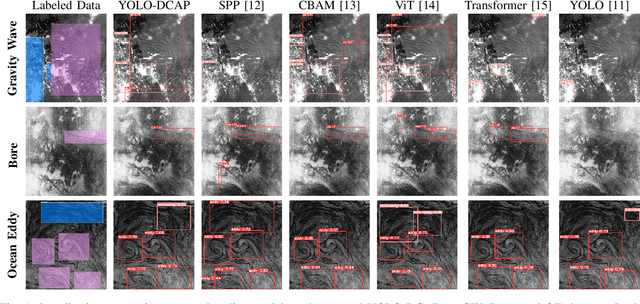
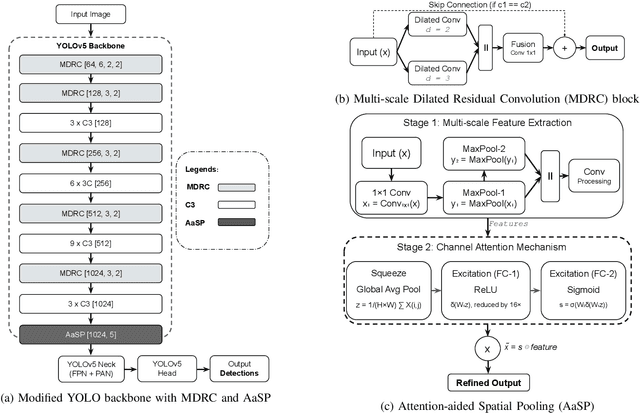
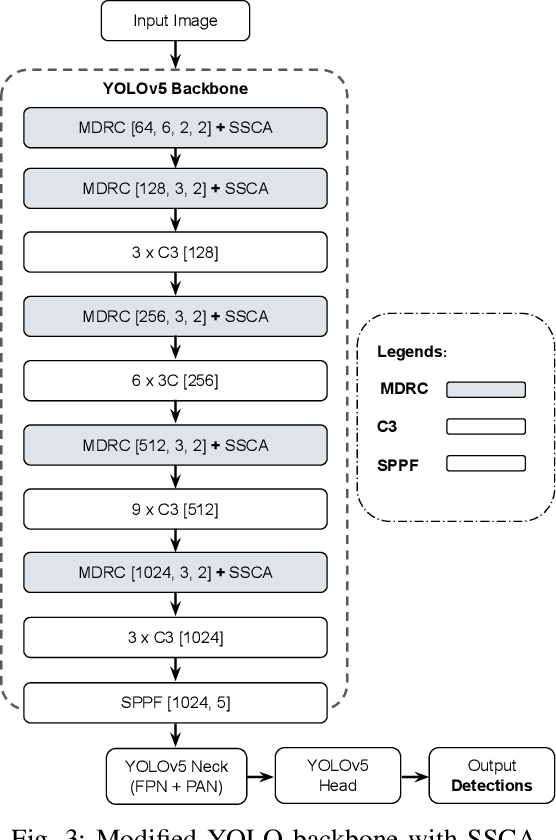
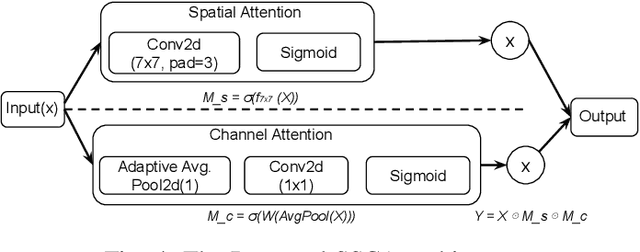
Object localization in satellite imagery is particularly challenging due to the high variability of objects, low spatial resolution, and interference from noise and dominant features such as clouds and city lights. In this research, we focus on three satellite datasets: upper atmospheric Gravity Waves (GW), mesospheric Bores (Bore), and Ocean Eddies (OE), each presenting its own unique challenges. These challenges include the variability in the scale and appearance of the main object patterns, where the size, shape, and feature extent of objects of interest can differ significantly. To address these challenges, we introduce YOLO-DCAP, a novel enhanced version of YOLOv5 designed to improve object localization in these complex scenarios. YOLO-DCAP incorporates a Multi-scale Dilated Residual Convolution (MDRC) block to capture multi-scale features at scale with varying dilation rates, and an Attention-aided Spatial Pooling (AaSP) module to focus on the global relevant spatial regions, enhancing feature selection. These structural improvements help to better localize objects in satellite imagery. Experimental results demonstrate that YOLO-DCAP significantly outperforms both the YOLO base model and state-of-the-art approaches, achieving an average improvement of 20.95% in mAP50 and 32.23% in IoU over the base model, and 7.35% and 9.84% respectively over state-of-the-art alternatives, consistently across all three satellite datasets. These consistent gains across all three satellite datasets highlight the robustness and generalizability of the proposed approach. Our code is open sourced at https://github.com/AI-4-atmosphere-remote-sensing/satellite-object-localization.