 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening for Expert Identified Linguistic Features: Assessment of Audio Deepfake Discernment among Undergraduate Students
Nov 21, 2024


This paper evaluates the impact of training undergraduate students to improve their audio deepfake discernment ability by listening for expert-defined linguistic features. Such features have been shown to improve performance of AI algorithms; here, we ascertain whether this improvement in AI algorithms also translates to improvement of the perceptual awareness and discernment ability of listeners. With humans as the weakest link in any cybersecurity solution, we propose that listener discernment is a key factor for improving trustworthiness of audio content. In this study we determine whether training that familiarizes listeners with English language variation can improve their abilities to discern audio deepfakes. We focus on undergraduate students, as this demographic group is constantly exposed to social media and the potential for deception and misinformation online. To the best of our knowledge, our work is the first study to uniquely address English audio deepfake discernment through such techniques. Our research goes beyond informational training by introducing targeted linguistic cues to listeners as a deepfake discernment mechanism, via a training module. In a pre-/post- experimental design, we evaluated the impact of the training across 264 students as a representative cross section of all students at the University of Maryland, Baltimore County, and across experimental and control sections. Findings show that the experimental group showed a statistically significant decrease in their unsurety when evaluating audio clips and an improvement in their ability to correctly identify clips they were initially unsure about. While results are promising, future research will explore more robust and comprehensive trainings for greater impact.
Toward Transdisciplinary Approaches to Audio Deepfake Discernment
Nov 08, 2024This perspective calls for scholars across disciplines to address the challenge of audio deepfake detection and discernment through an interdisciplinary lens across Artificial Intelligence methods and linguistics. With an avalanche of tools for the generation of realistic-sounding fake speech on one side, the detection of deepfakes is lagging on the other. Particularly hindering audio deepfake detection is the fact that current AI models lack a full understanding of the inherent variability of language and the complexities and uniqueness of human speech. We see the promising potential in recent transdisciplinary work that incorporates linguistic knowledge into AI approaches to provide pathways for expert-in-the-loop and to move beyond expert agnostic AI-based methods for more robust and comprehensive deepfake detection.
ALDAS: Audio-Linguistic Data Augmentation for Spoofed Audio Detection
Oct 21, 2024Spoofed audio, i.e. audio that is manipulated or AI-generated deepfake audio, is difficult to detect when only using acoustic features. Some recent innovative work involving AI-spoofed audio detection models augmented with phonetic and phonological features of spoken English, manually annotated by experts, led to improved model performance. While this augmented model produced substantial improvements over traditional acoustic features based models, a scalability challenge motivates inquiry into auto labeling of features. In this paper we propose an AI framework, Audio-Linguistic Data Augmentation for Spoofed audio detection (ALDAS), for auto labeling linguistic features. ALDAS is trained on linguistic features selected and extracted by sociolinguistics experts; these auto labeled features are used to evaluate the quality of ALDAS predictions. Findings indicate that while the detection enhancement is not as substantial as when involving the pure ground truth linguistic features, there is improvement in performance while achieving auto labeling. Labels generated by ALDAS are also validated by the sociolinguistics experts.
Investigating Causal Cues: Strengthening Spoofed Audio Detection with Human-Discernible Linguistic Features
Sep 09, 2024



Several types of spoofed audio, such as mimicry, replay attacks, and deepfakes, have created societal challenges to information integrity. Recently, researchers have worked with sociolinguistics experts to label spoofed audio samples with Expert Defined Linguistic Features (EDLFs) that can be discerned by the human ear: pitch, pause, word-initial and word-final release bursts of consonant stops, audible intake or outtake of breath, and overall audio quality. It is established that there is an improvement in several deepfake detection algorithms when they augmented the traditional and common features of audio data with these EDLFs. In this paper, using a hybrid dataset comprised of multiple types of spoofed audio augmented with sociolinguistic annotations, we investigate causal discovery and inferences between the discernible linguistic features and the label in the audio clips, comparing the findings of the causal models with the expert ground truth validation labeling process. Our findings suggest that the causal models indicate the utility of incorporating linguistic features to help discern spoofed audio, as well as the overall need and opportunity to incorporate human knowledge into models and techniques for strengthening AI models. The causal discovery and inference can be used as a foundation of training humans to discern spoofed audio as well as automating EDLFs labeling for the purpose of performance improvement of the common AI-based spoofed audio detectors.
Independent Component Analysis for Trustworthy Cyberspace during High Impact Events: An Application to Covid-19
Jun 06, 2020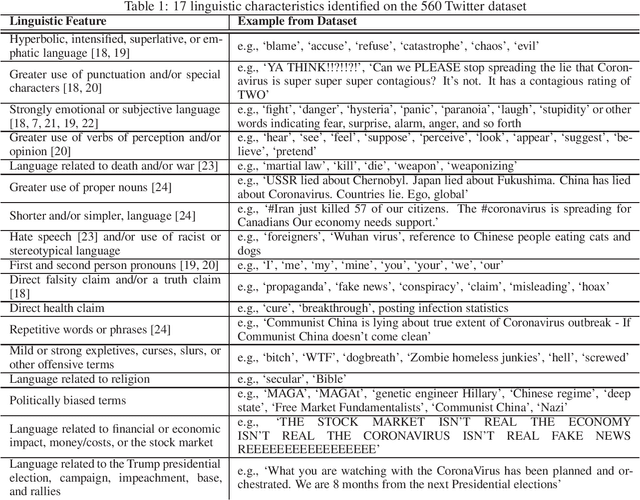
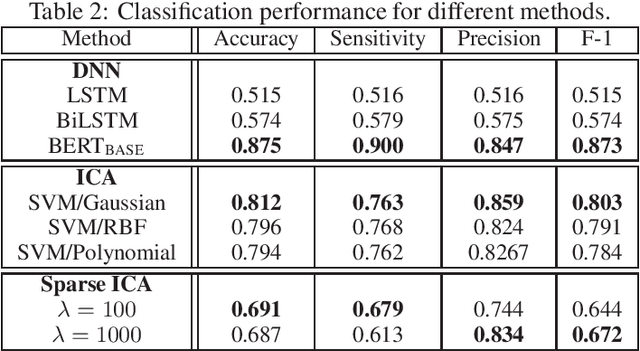
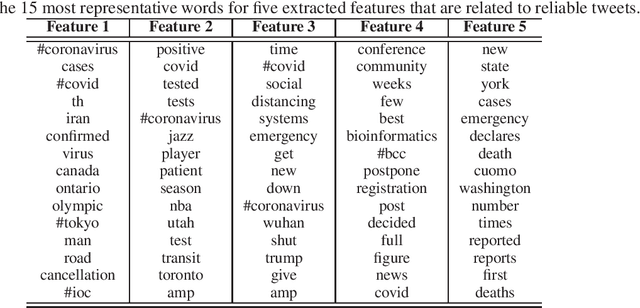
Social media has become an important communication channel during high impact events, such as the COVID-19 pandemic. As misinformation in social media can rapidly spread, creating social unrest, curtailing the spread of misinformation during such events is a significant data challenge. While recent solutions that are based on machine learning have shown promise for the detection of misinformation, most widely used methods include approaches that rely on either handcrafted features that cannot be optimal for all scenarios, or those that are based on deep learning where the interpretation of the prediction results is not directly accessible. In this work, we propose a data-driven solution that is based on the ICA model, such that knowledge discovery and detection of misinformation are achieved jointly. To demonstrate the effectiveness of our method and compare its performance with deep learning methods, we developed a labeled COVID-19 Twitter dataset based on socio-linguistic criteria.