 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Audio Deepfake Detection in Variable Conditions via Quantum-Kernel SVMs
Dec 21, 2025Detecting synthetic speech is challenging when labeled data are scarce and recording conditions vary. Existing end-to-end deep models often overfit or fail to generalize, and while kernel methods can remain competitive, their performance heavily depends on the chosen kernel. Here, we show that using a quantum kernel in audio deepfake detection reduces falsepositive rates without increasing model size. Quantum feature maps embed data into high-dimensional Hilbert spaces, enabling the use of expressive similarity measures and compact classifiers. Building on this motivation, we compare quantum-kernel SVMs (QSVMs) with classical SVMs using identical mel-spectrogram preprocessing and stratified 5-fold cross-validation across four corpora (ASVspoof 2019 LA, ASVspoof 5 (2024), ADD23, and an In-the-Wild set). QSVMs achieve consistently lower equalerror rates (EER): 0.183 vs. 0.299 on ASVspoof 5 (2024), 0.081 vs. 0.188 on ADD23, 0.346 vs. 0.399 on ASVspoof 2019, and 0.355 vs. 0.413 In-the-Wild. At the EER operating point (where FPR equals FNR), these correspond to absolute false-positiverate reductions of 0.116 (38.8%), 0.107 (56.9%), 0.053 (13.3%), and 0.058 (14.0%), respectively. We also report how consistent the results are across cross-validation folds and margin-based measures of class separation, using identical settings for both models. The only modification is the kernel; the features and SVM remain unchanged, no additional trainable parameters are introduced, and the quantum kernel is computed on a conventional computer.
Advancing climate model interpretability: Feature attribution for Arctic melt anomalies
Feb 11, 2025
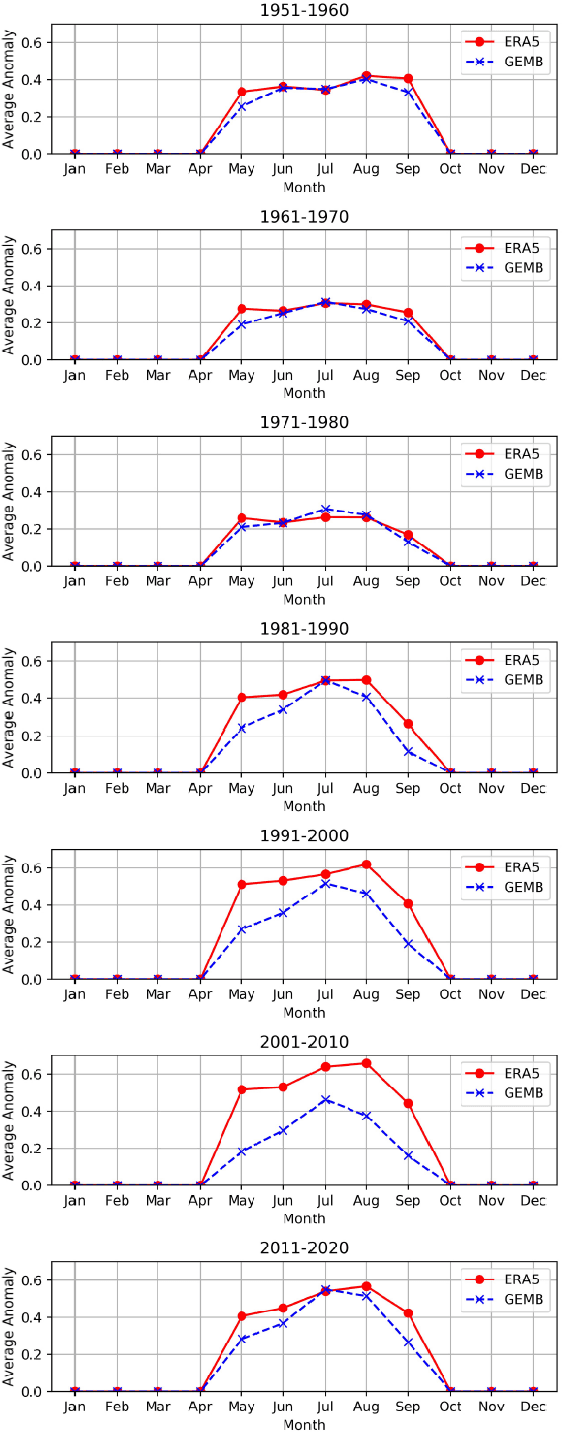

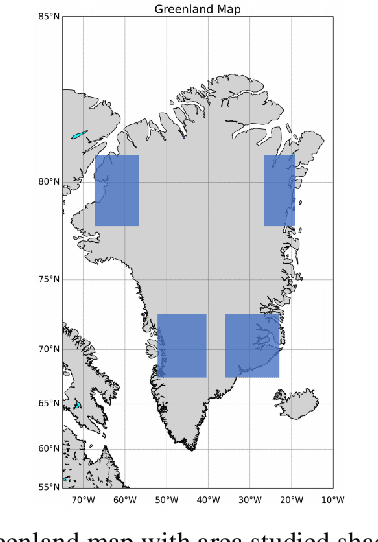
The focus of our work is improving the interpretability of anomalies in climate models and advancing our understanding of Arctic melt dynamics. The Arctic and Antarctic ice sheets are experiencing rapid surface melting and increased freshwater runoff, contributing significantly to global sea level rise. Understanding the mechanisms driving snowmelt in these regions is crucial. ERA5, a widely used reanalysis dataset in polar climate studies, offers extensive climate variables and global data assimilation. However, its snowmelt model employs an energy imbalance approach that may oversimplify the complexity of surface melt. In contrast, the Glacier Energy and Mass Balance (GEMB) model incorporates additional physical processes, such as snow accumulation, firn densification, and meltwater percolation/refreezing, providing a more detailed representation of surface melt dynamics. In this research, we focus on analyzing surface snowmelt dynamics of the Greenland Ice Sheet using feature attribution for anomalous melt events in ERA5 and GEMB models. We present a novel unsupervised attribution method leveraging counterfactual explanation method to analyze detected anomalies in ERA5 and GEMB. Our anomaly detection results are validated using MEaSUREs ground-truth data, and the attributions are evaluated against established feature ranking methods, including XGBoost, Shapley values, and Random Forest. Our attribution framework identifies the physics behind each model and the climate features driving melt anomalies. These findings demonstrate the utility of our attribution method in enhancing the interpretability of anomalies in climate models and advancing our understanding of Arctic melt dynamics.
Listening for Expert Identified Linguistic Features: Assessment of Audio Deepfake Discernment among Undergraduate Students
Nov 21, 2024


This paper evaluates the impact of training undergraduate students to improve their audio deepfake discernment ability by listening for expert-defined linguistic features. Such features have been shown to improve performance of AI algorithms; here, we ascertain whether this improvement in AI algorithms also translates to improvement of the perceptual awareness and discernment ability of listeners. With humans as the weakest link in any cybersecurity solution, we propose that listener discernment is a key factor for improving trustworthiness of audio content. In this study we determine whether training that familiarizes listeners with English language variation can improve their abilities to discern audio deepfakes. We focus on undergraduate students, as this demographic group is constantly exposed to social media and the potential for deception and misinformation online. To the best of our knowledge, our work is the first study to uniquely address English audio deepfake discernment through such techniques. Our research goes beyond informational training by introducing targeted linguistic cues to listeners as a deepfake discernment mechanism, via a training module. In a pre-/post- experimental design, we evaluated the impact of the training across 264 students as a representative cross section of all students at the University of Maryland, Baltimore County, and across experimental and control sections. Findings show that the experimental group showed a statistically significant decrease in their unsurety when evaluating audio clips and an improvement in their ability to correctly identify clips they were initially unsure about. While results are promising, future research will explore more robust and comprehensive trainings for greater impact.
Toward Transdisciplinary Approaches to Audio Deepfake Discernment
Nov 08, 2024This perspective calls for scholars across disciplines to address the challenge of audio deepfake detection and discernment through an interdisciplinary lens across Artificial Intelligence methods and linguistics. With an avalanche of tools for the generation of realistic-sounding fake speech on one side, the detection of deepfakes is lagging on the other. Particularly hindering audio deepfake detection is the fact that current AI models lack a full understanding of the inherent variability of language and the complexities and uniqueness of human speech. We see the promising potential in recent transdisciplinary work that incorporates linguistic knowledge into AI approaches to provide pathways for expert-in-the-loop and to move beyond expert agnostic AI-based methods for more robust and comprehensive deepfake detection.
Investigating Causal Cues: Strengthening Spoofed Audio Detection with Human-Discernible Linguistic Features
Sep 09, 2024Several types of spoofed audio, such as mimicry, replay attacks, and deepfakes, have created societal challenges to information integrity. Recently, researchers have worked with sociolinguistics experts to label spoofed audio samples with Expert Defined Linguistic Features (EDLFs) that can be discerned by the human ear: pitch, pause, word-initial and word-final release bursts of consonant stops, audible intake or outtake of breath, and overall audio quality. It is established that there is an improvement in several deepfake detection algorithms when they augmented the traditional and common features of audio data with these EDLFs. In this paper, using a hybrid dataset comprised of multiple types of spoofed audio augmented with sociolinguistic annotations, we investigate causal discovery and inferences between the discernible linguistic features and the label in the audio clips, comparing the findings of the causal models with the expert ground truth validation labeling process. Our findings suggest that the causal models indicate the utility of incorporating linguistic features to help discern spoofed audio, as well as the overall need and opportunity to incorporate human knowledge into models and techniques for strengthening AI models. The causal discovery and inference can be used as a foundation of training humans to discern spoofed audio as well as automating EDLFs labeling for the purpose of performance improvement of the common AI-based spoofed audio detectors.
Harnessing Feature Clustering For Enhanced Anomaly Detection With Variational Autoencoder And Dynamic Threshold
Jul 14, 2024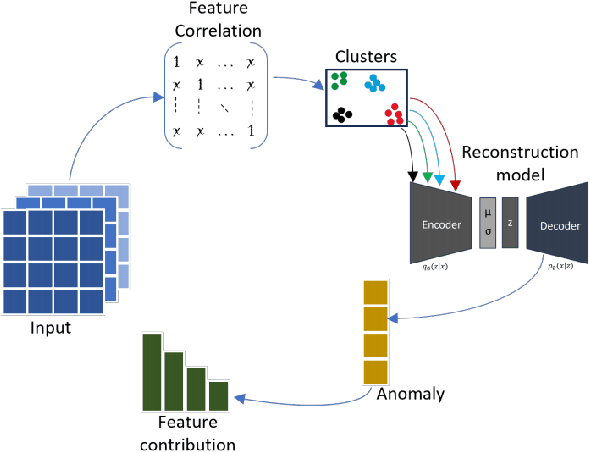
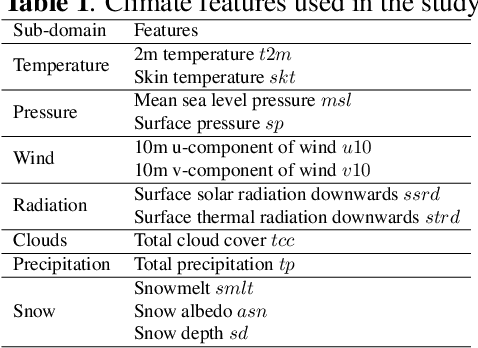
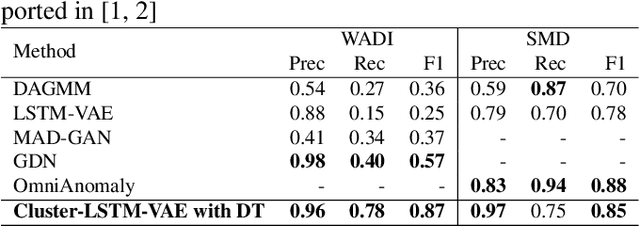
We introduce an anomaly detection method for multivariate time series data with the aim of identifying critical periods and features influencing extreme climate events like snowmelt in the Arctic. This method leverages the Variational Autoencoder (VAE) integrated with dynamic thresholding and correlation-based feature clustering. This framework enhances the VAE's ability to identify localized dependencies and learn the temporal relationships in climate data, thereby improving the detection of anomalies as demonstrated by its higher F1-score on benchmark datasets. The study's main contributions include the development of a robust anomaly detection method, improving feature representation within VAEs through clustering, and creating a dynamic threshold algorithm for localized anomaly detection. This method offers explainability of climate anomalies across different regions.
Narrative to Trajectory (N2T+): Extracting Routes of Life or Death from Human Trafficking Text Corpora
May 09, 2024Climate change and political unrest in certain regions of the world are imposing extreme hardship on many communities and are forcing millions of vulnerable populations to abandon their homelands and seek refuge in safer lands. As international laws are not fully set to deal with the migration crisis, people are relying on networks of exploiting smugglers to escape the devastation in order to live in stability. During the smuggling journey, migrants can become victims of human trafficking if they fail to pay the smuggler and may be forced into coerced labor. Government agencies and anti-trafficking organizations try to identify the trafficking routes based on stories of survivors in order to gain knowledge and help prevent such crimes. In this paper, we propose a system called Narrative to Trajectory (N2T+), which extracts trajectories of trafficking routes. N2T+ uses Data Science and Natural Language Processing techniques to analyze trafficking narratives, automatically extract relevant location names, disambiguate possible name ambiguities, and plot the trafficking route on a map. In a comparative evaluation we show that the proposed multi-dimensional approach offers significantly higher geolocation detection than other state of the art techniques.
Creating Geospatial Trajectories from Human Trafficking Text Corpora
May 09, 2024Human trafficking is a crime that affects the lives of millions of people across the globe. Traffickers exploit the victims through forced labor, involuntary sex, or organ harvesting. Migrant smuggling could also be seen as a form of human trafficking when the migrant fails to pay the smuggler and is forced into coerced activities. Several news agencies and anti-trafficking organizations have reported trafficking survivor stories that include the names of locations visited along the trafficking route. Identifying such routes can provide knowledge that is essential to preventing such heinous crimes. In this paper we propose a Narrative to Trajectory (N2T) information extraction system that analyzes reported narratives, extracts relevant information through the use of Natural Language Processing (NLP) techniques, and applies geospatial augmentation in order to automatically plot trajectories of human trafficking routes. We evaluate N2T on human trafficking text corpora and demonstrate that our approach of utilizing data preprocessing and augmenting database techniques with NLP libraries outperforms existing geolocation detection methods.
Audio Deepfake Perceptions in College Going Populations
Dec 06, 2021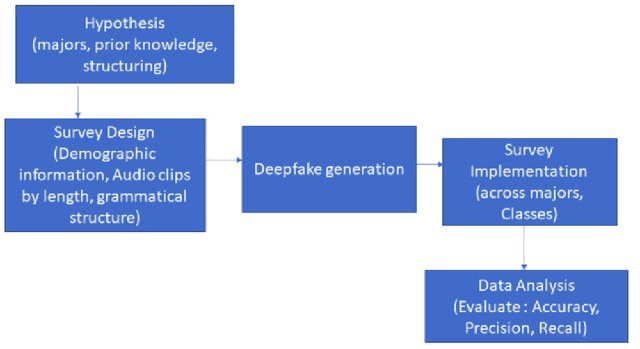
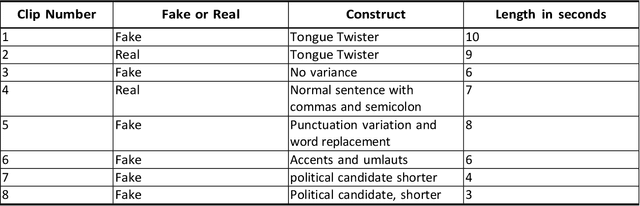

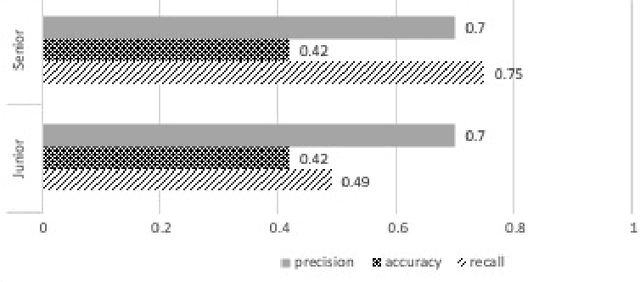
Deepfake is content or material that is generated or manipulated using AI methods, to pass off as real. There are four different deepfake types: audio, video, image and text. In this research we focus on audio deepfakes and how people perceive it. There are several audio deepfake generation frameworks, but we chose MelGAN which is a non-autoregressive and fast audio deepfake generating framework, requiring fewer parameters. This study tries to assess audio deepfake perceptions among college students from different majors. This study also answers the question of how their background and major can affect their perception towards AI generated deepfakes. We also analyzed the results based on different aspects of: grade level, complexity of the grammar used in the audio clips, length of the audio clips, those who knew the term deepfakes and those who did not, as well as the political angle. It is interesting that the results show when an audio clip has a political connotation, it can affect what people think about whether it is real or fake, even if the content is fairly similar. This study also explores the question of how background and major can affect perception towards deepfakes.
How Deep Are the Fakes? Focusing on Audio Deepfake: A Survey
Nov 28, 2021
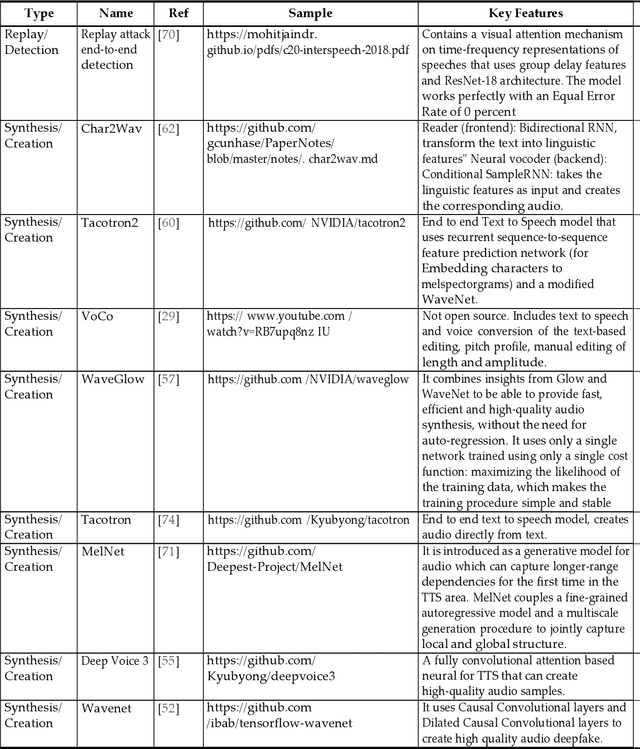
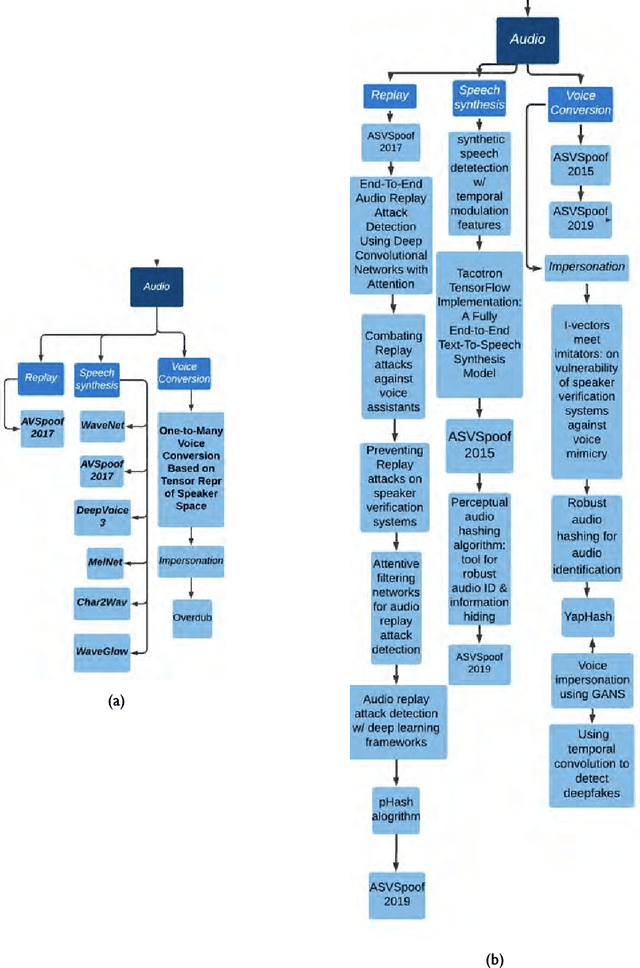
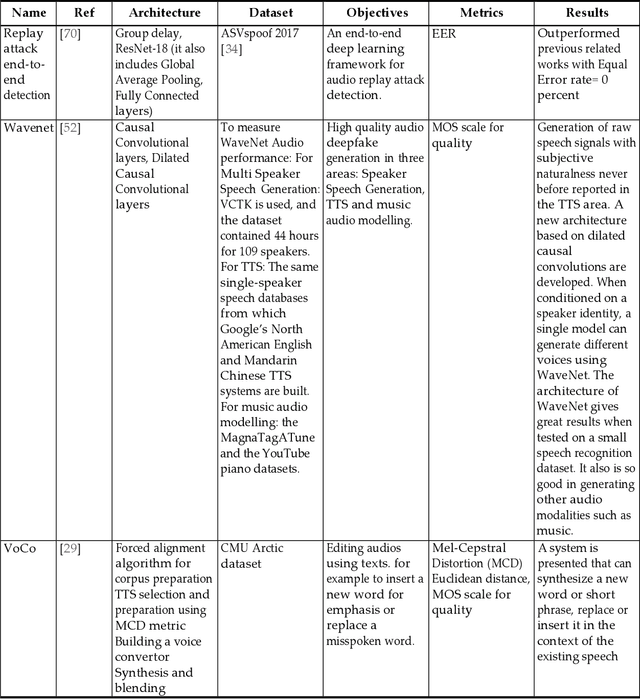
Deepfake is content or material that is synthetically generated or manipulated using artificial intelligence (AI) methods, to be passed off as real and can include audio, video, image, and text synthesis. This survey has been conducted with a different perspective compared to existing survey papers, that mostly focus on just video and image deepfakes. This survey not only evaluates generation and detection methods in the different deepfake categories, but mainly focuses on audio deepfakes that are overlooked in most of the existing surveys. This paper critically analyzes and provides a unique source of audio deepfake research, mostly ranging from 2016 to 2020. To the best of our knowledge, this is the first survey focusing on audio deepfakes in English. This survey provides readers with a summary of 1) different deepfake categories 2) how they could be created and detected 3) the most recent trends in this domain and shortcomings in detection methods 4) audio deepfakes, how they are created and detected in more detail which is the main focus of this paper. We found that Generative Adversarial Networks(GAN), Convolutional Neural Networks (CNN), and Deep Neural Networks (DNN) are common ways of creating and detecting deepfakes. In our evaluation of over 140 methods we found that the majority of the focus is on video deepfakes and in particular in the generation of video deepfakes. We found that for text deepfakes there are more generation methods but very few robust methods for detection, including fake news detection, which has become a controversial area of research because of the potential of heavy overlaps with human generation of fake content. This paper is an abbreviated version of the full survey and reveals a clear need to research audio deepfakes and particularly detection of audio deepfakes.