 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Simulation Study of the Fairness and Accuracy of Predictive Policing Systems in Baltimore City
Jan 30, 2026There are ongoing discussions about predictive policing systems, such as those deployed in Los Angeles, California and Baltimore, Maryland, being unfair, for example, by exhibiting racial bias. Studies found that unfairness may be due to feedback loops and being trained on historically biased recorded data. However, comparative studies on predictive policing systems are few and are not sufficiently comprehensive. In this work, we perform a comprehensive comparative simulation study on the fairness and accuracy of predictive policing technologies in Baltimore. Our results suggest that the situation around bias in predictive policing is more complex than was previously assumed. While predictive policing exhibited bias due to feedback loops as was previously reported, we found that the traditional alternative, hot spots policing, had similar issues. Predictive policing was found to be more fair and accurate than hot spots policing in the short term, although it amplified bias faster, suggesting the potential for worse long-run behavior. In Baltimore, in some cases the bias in these systems tended toward over-policing in White neighborhoods, unlike in previous studies. Overall, this work demonstrates a methodology for city-specific evaluation and behavioral-tendency comparison of predictive policing systems, showing how such simulations can reveal inequities and long-term tendencies.
You've Changed: Detecting Modification of Black-Box Large Language Models
Apr 14, 2025

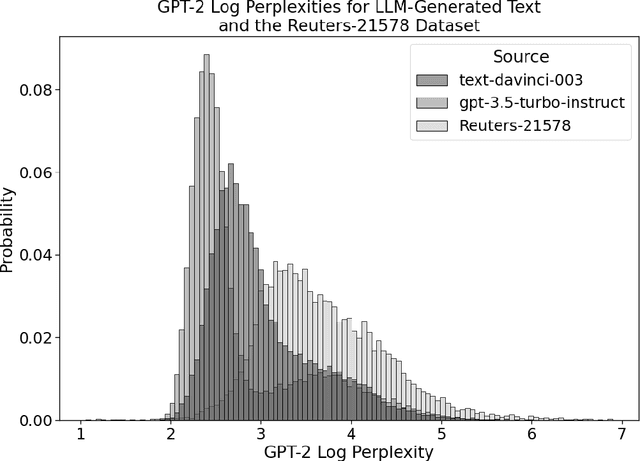

Large Language Models (LLMs) are often provided as a service via an API, making it challenging for developers to detect changes in their behavior. We present an approach to monitor LLMs for changes by comparing the distributions of linguistic and psycholinguistic features of generated text. Our method uses a statistical test to determine whether the distributions of features from two samples of text are equivalent, allowing developers to identify when an LLM has changed. We demonstrate the effectiveness of our approach using five OpenAI completion models and Meta's Llama 3 70B chat model. Our results show that simple text features coupled with a statistical test can distinguish between language models. We also explore the use of our approach to detect prompt injection attacks. Our work enables frequent LLM change monitoring and avoids computationally expensive benchmark evaluations.
ALDAS: Audio-Linguistic Data Augmentation for Spoofed Audio Detection
Oct 21, 2024Spoofed audio, i.e. audio that is manipulated or AI-generated deepfake audio, is difficult to detect when only using acoustic features. Some recent innovative work involving AI-spoofed audio detection models augmented with phonetic and phonological features of spoken English, manually annotated by experts, led to improved model performance. While this augmented model produced substantial improvements over traditional acoustic features based models, a scalability challenge motivates inquiry into auto labeling of features. In this paper we propose an AI framework, Audio-Linguistic Data Augmentation for Spoofed audio detection (ALDAS), for auto labeling linguistic features. ALDAS is trained on linguistic features selected and extracted by sociolinguistics experts; these auto labeled features are used to evaluate the quality of ALDAS predictions. Findings indicate that while the detection enhancement is not as substantial as when involving the pure ground truth linguistic features, there is improvement in performance while achieving auto labeling. Labels generated by ALDAS are also validated by the sociolinguistics experts.
GenderAlign: An Alignment Dataset for Mitigating Gender Bias in Large Language Models
Jun 20, 2024



Large Language Models (LLMs) are prone to generating content that exhibits gender biases, raising significant ethical concerns. Alignment, the process of fine-tuning LLMs to better align with desired behaviors, is recognized as an effective approach to mitigate gender biases. Although proprietary LLMs have made significant strides in mitigating gender bias, their alignment datasets are not publicly available. The commonly used and publicly available alignment dataset, HH-RLHF, still exhibits gender bias to some extent. There is a lack of publicly available alignment datasets specifically designed to address gender bias. Hence, we developed a new dataset named GenderAlign, aiming at mitigating a comprehensive set of gender biases in LLMs. This dataset comprises 8k single-turn dialogues, each paired with a "chosen" and a "rejected" response. Compared to the "rejected" responses, the "chosen" responses demonstrate lower levels of gender bias and higher quality. Furthermore, we categorized the gender biases in the "rejected" responses of GenderAlign into 4 principal categories. The experimental results show the effectiveness of GenderAlign in reducing gender bias in LLMs.
Teach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023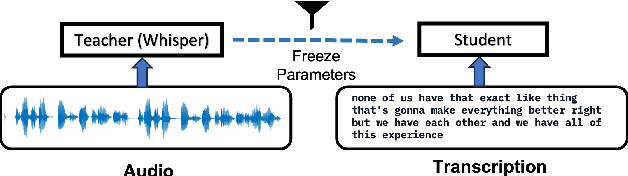



Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
Tell Me Something That Will Help Me Trust You: A Survey of Trust Calibration in Human-Agent Interaction
May 06, 2022
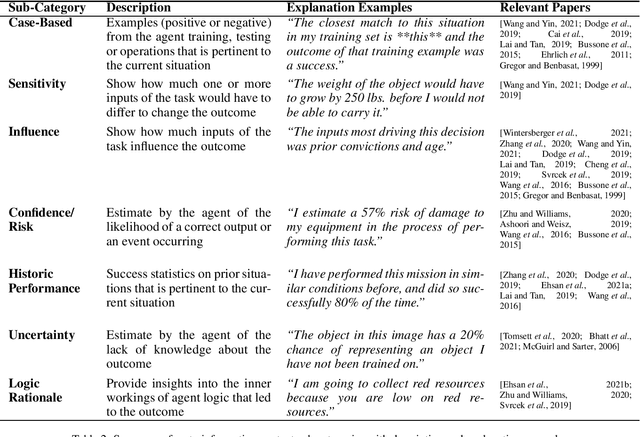
When a human receives a prediction or recommended course of action from an intelligent agent, what additional information, beyond the prediction or recommendation itself, does the human require from the agent to decide whether to trust or reject the prediction or recommendation? In this paper we survey literature in the area of trust between a single human supervisor and a single agent subordinate to determine the nature and extent of this additional information and to characterize it into a taxonomy that can be leveraged by future researchers and intelligent agent practitioners. By examining this question from a human-centered, information-focused point of view, we can begin to compare and contrast different implementations and also provide insight and directions for future work.
Fair Representation Learning for Heterogeneous Information Networks
Apr 18, 2021
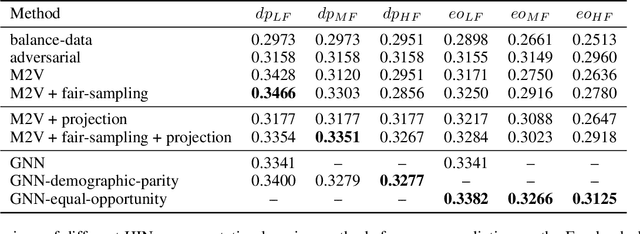
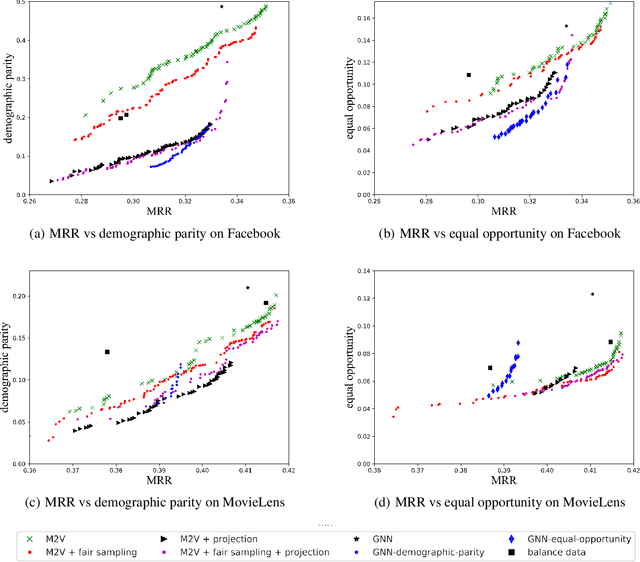
Recently, much attention has been paid to the societal impact of AI, especially concerns regarding its fairness. A growing body of research has identified unfair AI systems and proposed methods to debias them, yet many challenges remain. Representation learning for Heterogeneous Information Networks (HINs), a fundamental building block used in complex network mining, has socially consequential applications such as automated career counseling, but there have been few attempts to ensure that it will not encode or amplify harmful biases, e.g. sexism in the job market. To address this gap, in this paper we propose a comprehensive set of de-biasing methods for fair HINs representation learning, including sampling-based, projection-based, and graph neural networks (GNNs)-based techniques. We systematically study the behavior of these algorithms, especially their capability in balancing the trade-off between fairness and prediction accuracy. We evaluate the performance of the proposed methods in an automated career counseling application where we mitigate gender bias in career recommendation. Based on the evaluation results on two datasets, we identify the most effective fair HINs representation learning techniques under different conditions.
Causal Feature Selection with Dimension Reduction for Interpretable Text Classification
Oct 09, 2020



Text features that are correlated with class labels, but do not directly cause them, are sometimesuseful for prediction, but they may not be insightful. As an alternative to traditional correlation-basedfeature selection, causal inference could reveal more principled, meaningful relationships betweentext features and labels. To help researchers gain insight into text data, e.g. for social scienceapplications, in this paper we investigate a class of matching-based causal inference methods fortext feature selection. Features used in document classification are often high dimensional, howeverexisting causal feature selection methods use Propensity Score Matching (PSM) which is known to beless effective in high-dimensional spaces. We propose a new causal feature selection framework thatcombines dimension reduction with causal inference to improve text feature selection. Experiments onboth synthetic and real-world data demonstrate the promise of our methods in improving classificationand enhancing interpretability.
Neural Fair Collaborative Filtering
Sep 02, 2020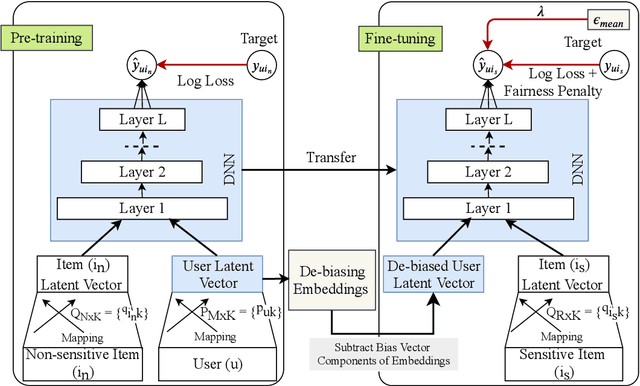
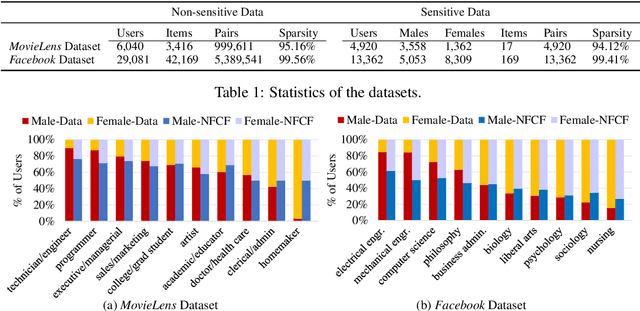
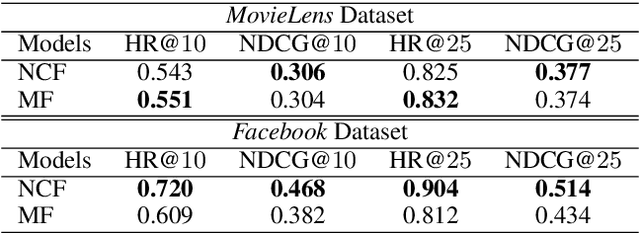
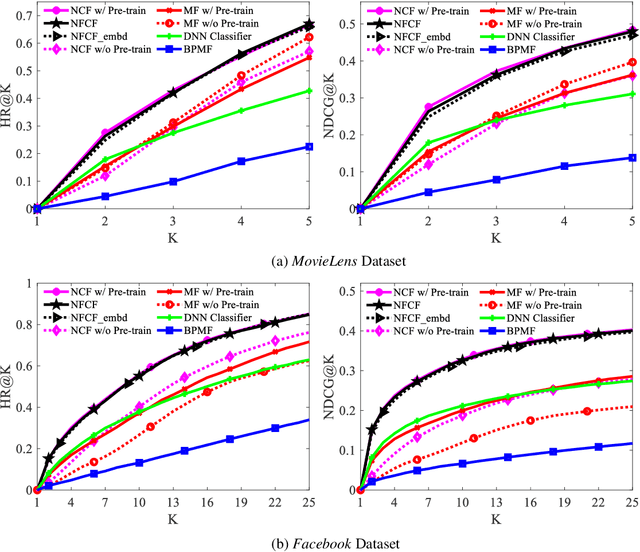
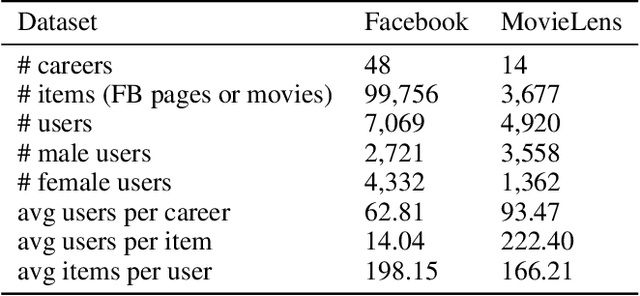
A growing proportion of human interactions are digitized on social media platforms and subjected to algorithmic decision-making, and it has become increasingly important to ensure fair treatment from these algorithms. In this work, we investigate gender bias in collaborative-filtering recommender systems trained on social media data. We develop neural fair collaborative filtering (NFCF), a practical framework for mitigating gender bias in recommending sensitive items (e.g. jobs, academic concentrations, or courses of study) using a pre-training and fine-tuning approach to neural collaborative filtering, augmented with bias correction techniques. We show the utility of our methods for gender de-biased career and college major recommendations on the MovieLens dataset and a Facebook dataset, respectively, and achieve better performance and fairer behavior than several state-of-the-art models.
Estimating Buildings' Parameters over Time Including Prior Knowledge
Jan 09, 2019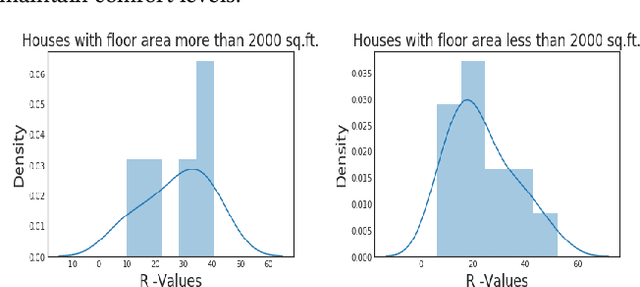
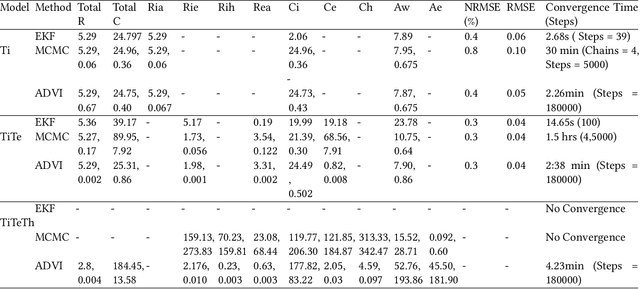
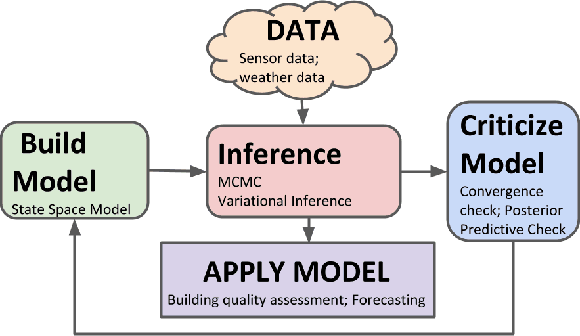
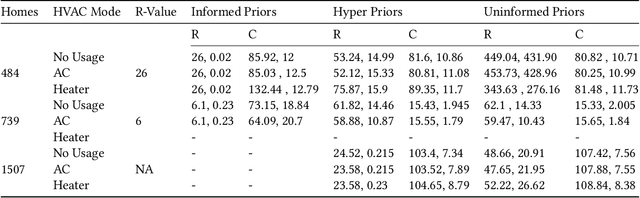
Modeling buildings' heat dynamics is a complex process which depends on various factors including weather, building thermal capacity, insulation preservation, and residents' behavior. Gray-box models offer a causal inference of those dynamics expressed in few parameters specific to built environments. These parameters can provide compelling insights into the characteristics of building artifacts and have various applications such as forecasting HVAC usage, indoor temperature control monitoring of built environments, etc. In this paper, we present a systematic study of modeling buildings' thermal characteristics and thus derive the parameters of built conditions with a Bayesian approach. We build a Bayesian state-space model that can adapt and incorporate buildings' thermal equations and propose a generalized solution that can easily adapt prior knowledge regarding the parameters. We show that a faster approximate approach using variational inference for parameter estimation can provide similar parameters as that of a more time-consuming Markov Chain Monte Carlo (MCMC) approach. We perform extensive evaluations on two datasets to understand the generative process and show that the Bayesian approach is more interpretable. We further study the effects of prior selection for the model parameters and transfer learning, where we learn parameters from one season and use them to fit the model in the other. We perform extensive evaluations on controlled and real data traces to enumerate buildings' parameter within a 95% credible interval.