 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeach me with a Whisper: Enhancing Large Language Models for Analyzing Spoken Transcripts using Speech Embeddings
Nov 13, 2023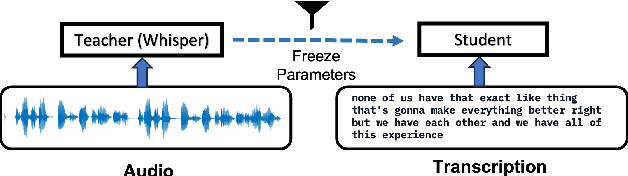



Speech data has rich acoustic and paralinguistic information with important cues for understanding a speaker's tone, emotion, and intent, yet traditional large language models such as BERT do not incorporate this information. There has been an increased interest in multi-modal language models leveraging audio and/or visual information and text. However, current multi-modal language models require both text and audio/visual data streams during inference/test time. In this work, we propose a methodology for training language models leveraging spoken language audio data but without requiring the audio stream during prediction time. This leads to an improved language model for analyzing spoken transcripts while avoiding an audio processing overhead at test time. We achieve this via an audio-language knowledge distillation framework, where we transfer acoustic and paralinguistic information from a pre-trained speech embedding (OpenAI Whisper) teacher model to help train a student language model on an audio-text dataset. In our experiments, the student model achieves consistent improvement over traditional language models on tasks analyzing spoken transcripts.
Learning User Embeddings from Temporal Social Media Data: A Survey
May 17, 2021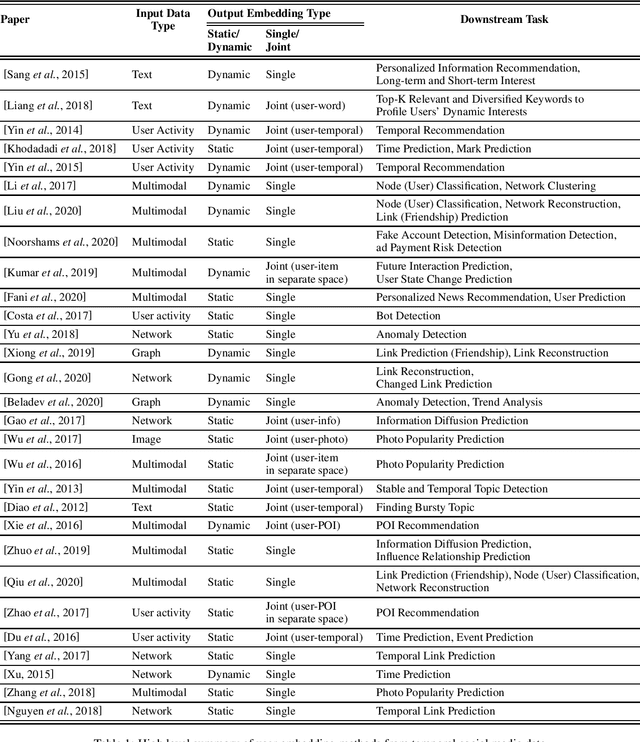
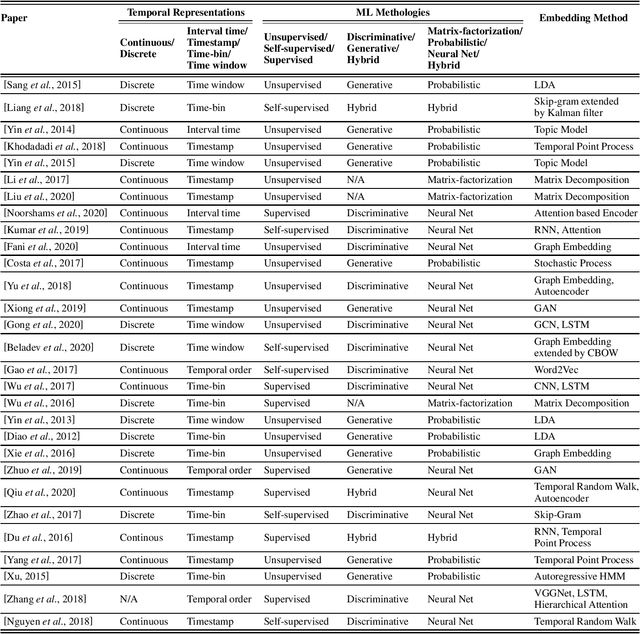
User-generated data on social media contain rich information about who we are, what we like and how we make decisions. In this paper, we survey representative work on learning a concise latent user representation (a.k.a. user embedding) that can capture the main characteristics of a social media user. The learned user embeddings can later be used to support different downstream user analysis tasks such as personality modeling, suicidal risk assessment and purchase decision prediction. The temporal nature of user-generated data on social media has largely been overlooked in much of the existing user embedding literature. In this survey, we focus on research that bridges the gap by incorporating temporal/sequential information in user representation learning. We categorize relevant papers along several key dimensions, identify limitations in the current work and suggest future research directions.