 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCR Graph Features for Manipulation Detection in Documents
Sep 14, 2020

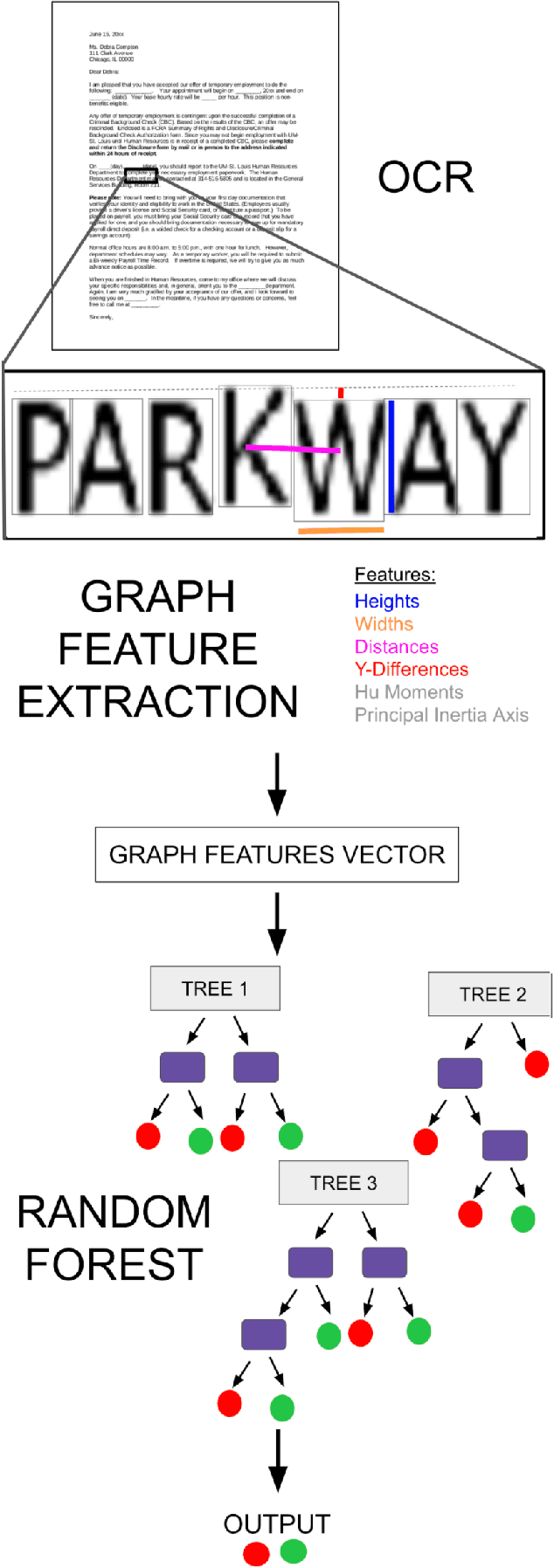

Detecting manipulations in digital documents is becoming increasingly important for information verification purposes. Due to the proliferation of image editing software, altering key information in documents has become widely accessible. Nearly all approaches in this domain rely on a procedural approach, using carefully generated features and a hand-tuned scoring system, rather than a data-driven and generalizable approach. We frame this issue as a graph comparison problem using the character bounding boxes, and propose a model that leverages graph features using OCR (Optical Character Recognition). Our model relies on a data-driven approach to detect alterations by training a random forest classifier on the graph-based OCR features. We evaluate our algorithm's forgery detection performance on dataset constructed from real business documents with slight forgery imperfections. Our proposed model dramatically outperforms the most closely-related document manipulation detection model on this task.
MRZ code extraction from visa and passport documents using convolutional neural networks
Sep 11, 2020
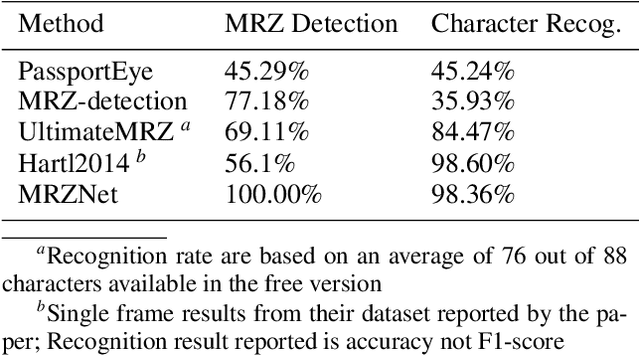

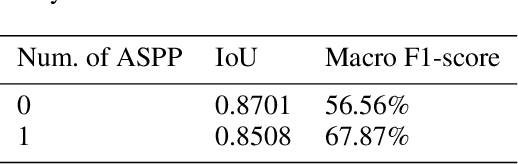
Detecting and extracting information from Machine-Readable Zone (MRZ) on passports and visas is becoming increasingly important for verifying document authenticity. However, computer vision methods for performing similar tasks, such as optical character recognition (OCR), fail to extract the MRZ given digital images of passports with reasonable accuracy. We present a specially designed model based on convolutional neural networks that is able to successfully extract MRZ information from digital images of passports of arbitrary orientation and size. Our model achieved 100% MRZ detection rate and 98.36% character recognition macro-f1 score on a passport and visa dataset.
NoPeek: Information leakage reduction to share activations in distributed deep learning
Aug 20, 2020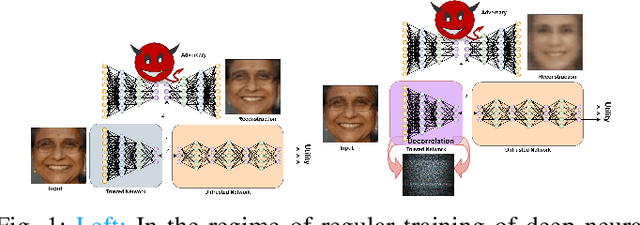
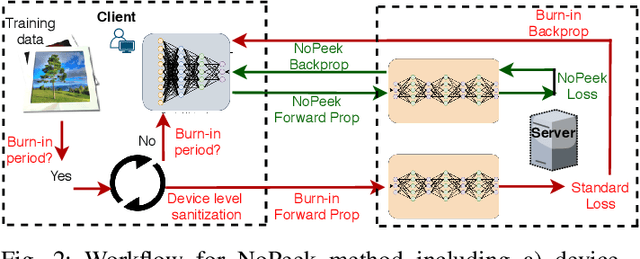
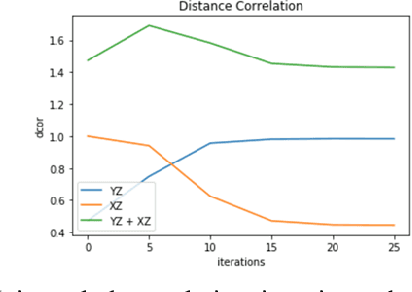
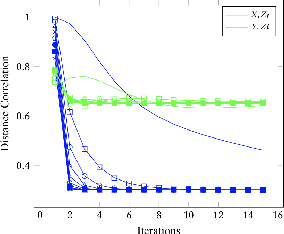
For distributed machine learning with sensitive data, we demonstrate how minimizing distance correlation between raw data and intermediary representations reduces leakage of sensitive raw data patterns across client communications while maintaining model accuracy. Leakage (measured using distance correlation between input and intermediate representations) is the risk associated with the invertibility of raw data from intermediary representations. This can prevent client entities that hold sensitive data from using distributed deep learning services. We demonstrate that our method is resilient to such reconstruction attacks and is based on reduction of distance correlation between raw data and learned representations during training and inference with image datasets. We prevent such reconstruction of raw data while maintaining information required to sustain good classification accuracies.
Printing and Scanning Attack for Image Counter Forensics
Apr 27, 2020


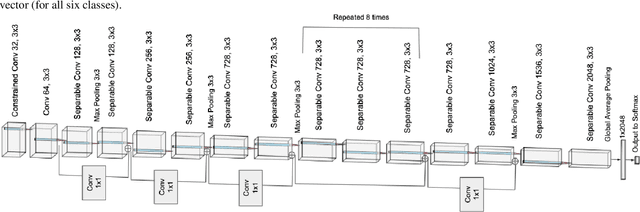
Examining the authenticity of images has become increasingly important as manipulation tools become more accessible and advanced. Recent work has shown that while CNN-based image manipulation detectors can successfully identify manipulations, they are also vulnerable to adversarial attacks, ranging from simple double JPEG compression to advanced pixel-based perturbation. Rephrase(hailey): In this paper we explore another method of highly plausible attack: printing and scanning. We demonstrate the vulnerability of two state-of-the-art models to this type of attack. We also propose a new machine learning model that performs comparably to these state-of-the-art models when trained and validated on printed and scanned images. Of the three models, our proposed model performs the best when trained and validated on images from a single printer. To facilitate this exploration, we create a dataset of over 6,000 printed and scanned image blocks. Further analysis suggests that variation between images produced from different printers is significant, large enough that good validation accuracy on images from one printer does not imply similar validation accuracy on images from a different printer.
Maximal adversarial perturbations for obfuscation: Hiding certain attributes while preserving rest
Sep 27, 2019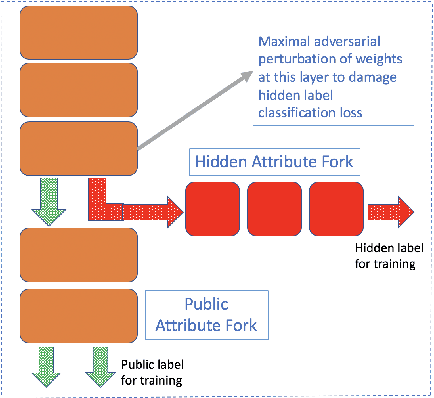
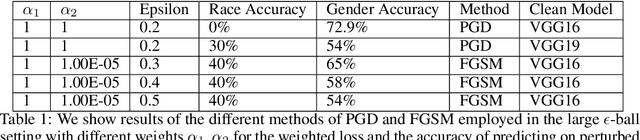
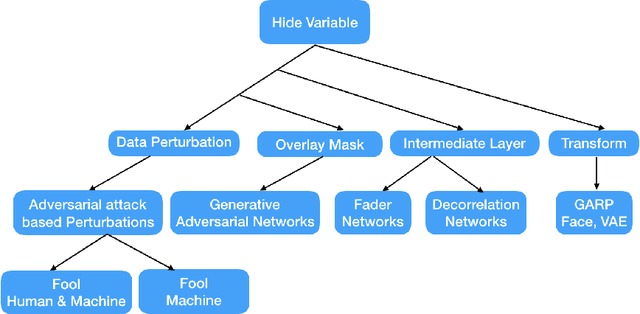

In this paper we investigate the usage of adversarial perturbations for the purpose of privacy from human perception and model (machine) based detection. We employ adversarial perturbations for obfuscating certain variables in raw data while preserving the rest. Current adversarial perturbation methods are used for data poisoning with minimal perturbations of the raw data such that the machine learning model's performance is adversely impacted while the human vision cannot perceive the difference in the poisoned dataset due to minimal nature of perturbations. We instead apply relatively maximal perturbations of raw data to conditionally damage model's classification of one attribute while preserving the model performance over another attribute. In addition, the maximal nature of perturbation helps adversely impact human perception in classifying hidden attribute apart from impacting model performance. We validate our result qualitatively by showing the obfuscated dataset and quantitatively by showing the inability of models trained on clean data to predict the hidden attribute from the perturbed dataset while being able to predict the rest of attributes.
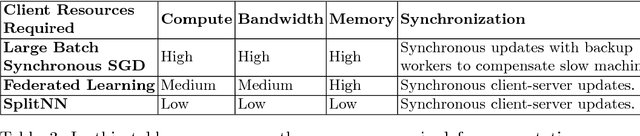
Detailed comparison of communication efficiency of split learning and federated learning
Sep 18, 2019
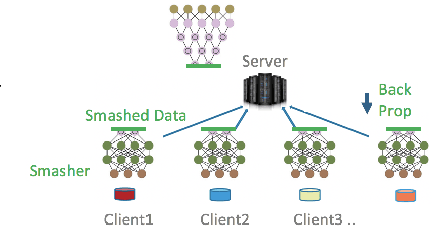
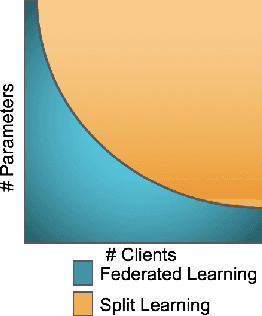
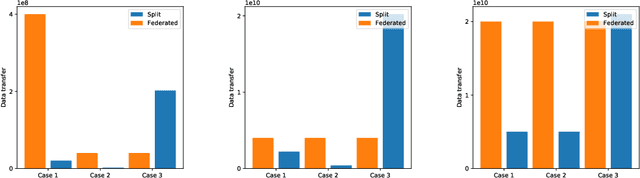
We compare communication efficiencies of two compelling distributed machine learning approaches of split learning and federated learning. We show useful settings under which each method outperforms the other in terms of communication efficiency. We consider various practical scenarios of distributed learning setup and juxtapose the two methods under various real-life scenarios. We consider settings of small and large number of clients as well as small models (1M - 6M parameters), large models (10M - 200M parameters) and very large models (1 Billion-100 Billion parameters). We show that increasing number of clients or increasing model size favors split learning setup over the federated while increasing the number of data samples while keeping the number of clients or model size low makes federated learning more communication efficient.
No Peek: A Survey of private distributed deep learning
Dec 08, 2018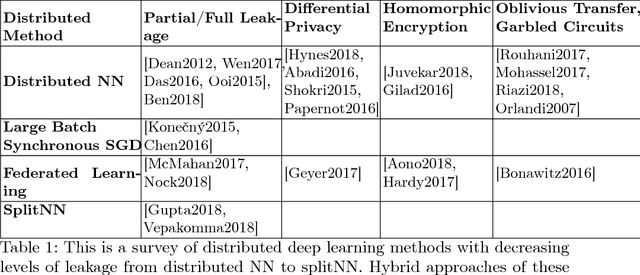
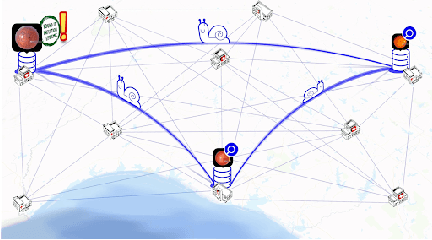
We survey distributed deep learning models for training or inference without accessing raw data from clients. These methods aim to protect confidential patterns in data while still allowing servers to train models. The distributed deep learning methods of federated learning, split learning and large batch stochastic gradient descent are compared in addition to private and secure approaches of differential privacy, homomorphic encryption, oblivious transfer and garbled circuits in the context of neural networks. We study their benefits, limitations and trade-offs with regards to computational resources, data leakage and communication efficiency and also share our anticipated future trends.
Split learning for health: Distributed deep learning without sharing raw patient data
Dec 03, 2018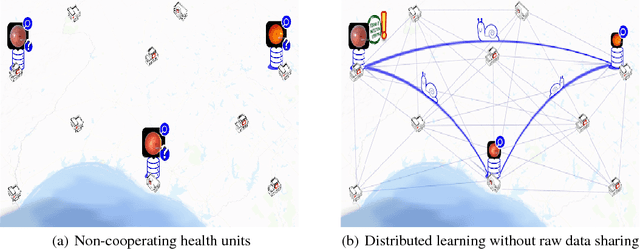

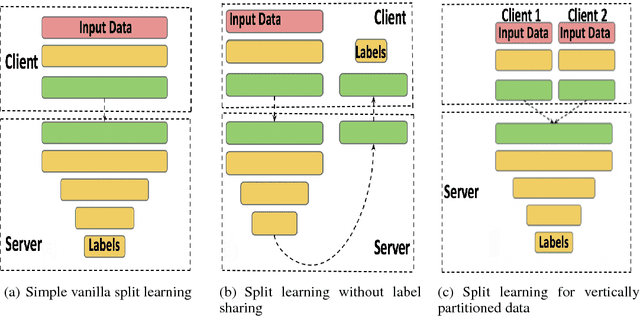

Can health entities collaboratively train deep learning models without sharing sensitive raw data? This paper proposes several configurations of a distributed deep learning method called SplitNN to facilitate such collaborations. SplitNN does not share raw data or model details with collaborating institutions. The proposed configurations of splitNN cater to practical settings of i) entities holding different modalities of patient data, ii) centralized and local health entities collaborating on multiple tasks and iii) learning without sharing labels. We compare performance and resource efficiency trade-offs of splitNN and other distributed deep learning methods like federated learning, large batch synchronous stochastic gradient descent and show highly encouraging results for splitNN.
Distributed learning of deep neural network over multiple agents
Oct 14, 2018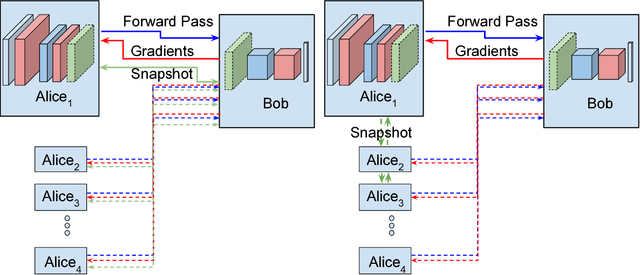
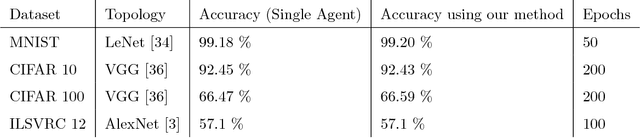

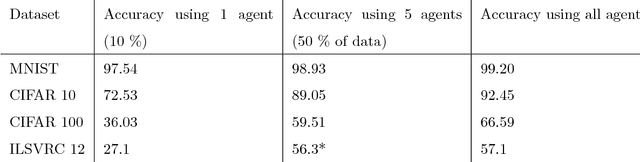
In domains such as health care and finance, shortage of labeled data and computational resources is a critical issue while developing machine learning algorithms. To address the issue of labeled data scarcity in training and deployment of neural network-based systems, we propose a new technique to train deep neural networks over several data sources. Our method allows for deep neural networks to be trained using data from multiple entities in a distributed fashion. We evaluate our algorithm on existing datasets and show that it obtains performance which is similar to a regular neural network trained on a single machine. We further extend it to incorporate semi-supervised learning when training with few labeled samples, and analyze any security concerns that may arise. Our algorithm paves the way for distributed training of deep neural networks in data sensitive applications when raw data may not be shared directly.
Maximum-Entropy Fine-Grained Classification
Sep 20, 2018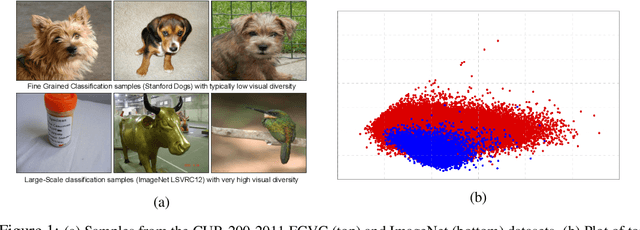
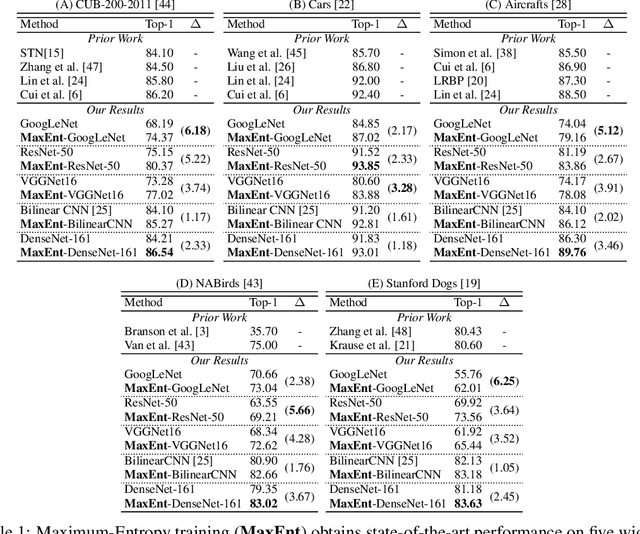
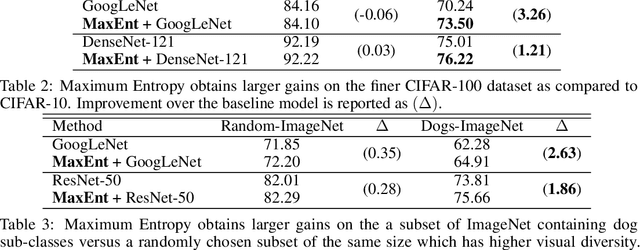
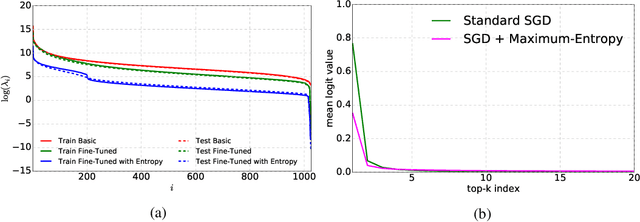
Fine-Grained Visual Classification (FGVC) is an important computer vision problem that involves small diversity within the different classes, and often requires expert annotators to collect data. Utilizing this notion of small visual diversity, we revisit Maximum-Entropy learning in the context of fine-grained classification, and provide a training routine that maximizes the entropy of the output probability distribution for training convolutional neural networks on FGVC tasks. We provide a theoretical as well as empirical justification of our approach, and achieve state-of-the-art performance across a variety of classification tasks in FGVC, that can potentially be extended to any fine-tuning task. Our method is robust to different hyperparameter values, amount of training data and amount of training label noise and can hence be a valuable tool in many similar problems.