 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoDaCam: Software-defined Cameras via Single-Photon Imaging
Sep 08, 2023



Reinterpretable cameras are defined by their post-processing capabilities that exceed traditional imaging. We present "SoDaCam" that provides reinterpretable cameras at the granularity of photons, from photon-cubes acquired by single-photon devices. Photon-cubes represent the spatio-temporal detections of photons as a sequence of binary frames, at frame-rates as high as 100 kHz. We show that simple transformations of the photon-cube, or photon-cube projections, provide the functionality of numerous imaging systems including: exposure bracketing, flutter shutter cameras, video compressive systems, event cameras, and even cameras that move during exposure. Our photon-cube projections offer the flexibility of being software-defined constructs that are only limited by what is computable, and shot-noise. We exploit this flexibility to provide new capabilities for the emulated cameras. As an added benefit, our projections provide camera-dependent compression of photon-cubes, which we demonstrate using an implementation of our projections on a novel compute architecture that is designed for single-photon imaging.
Automatic calibration of time of flight based non-line-of-sight reconstruction
May 21, 2021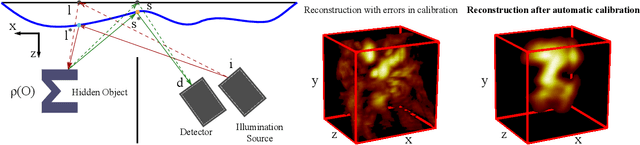



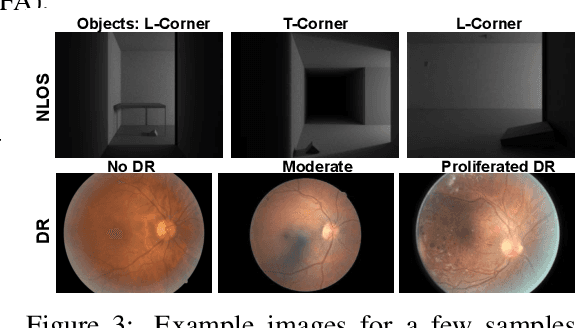
Time of flight based Non-line-of-sight (NLOS) imaging approaches require precise calibration of illumination and detector positions on the visible scene to produce reasonable results. If this calibration error is sufficiently high, reconstruction can fail entirely without any indication to the user. In this work, we highlight the necessity of building autocalibration into NLOS reconstruction in order to handle mis-calibration. We propose a forward model of NLOS measurements that is differentiable with respect to both, the hidden scene albedo, and virtual illumination and detector positions. With only a mean squared error loss and no regularization, our model enables joint reconstruction and recovery of calibration parameters by minimizing the measurement residual using gradient descent. We demonstrate our method is able to produce robust reconstructions using simulated and real data where the calibration error applied causes other state of the art algorithms to fail.
Recent Advances in Imaging Around Corners
Oct 12, 2019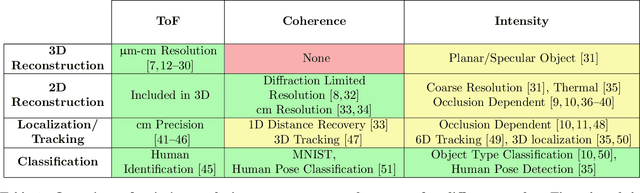
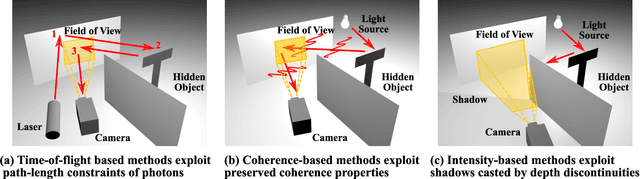
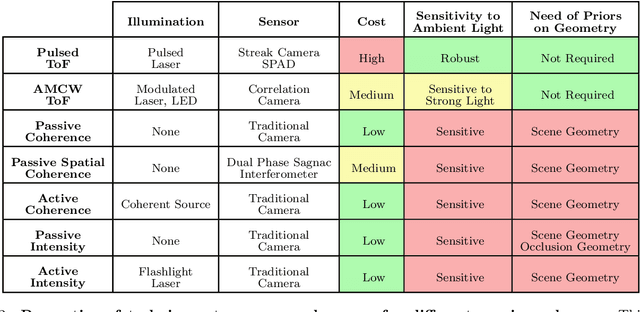
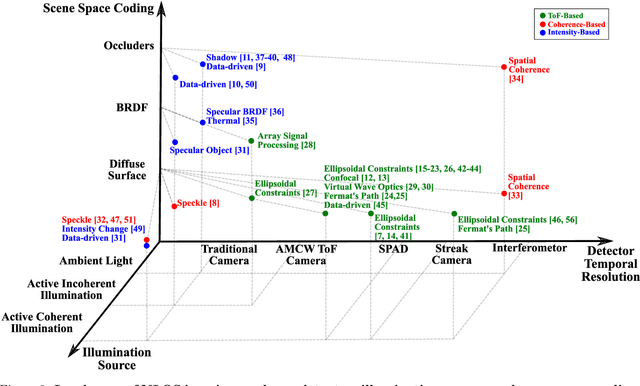
Seeing around corners, also known as non-line-of-sight (NLOS) imaging is a computational method to resolve or recover objects hidden around corners. Recent advances in imaging around corners have gained significant interest. This paper reviews different types of existing NLOS imaging techniques and discusses the challenges that need to be addressed, especially for their applications outside of a constrained laboratory environment. Our goal is to introduce this topic to broader research communities as well as provide insights that would lead to further developments in this research area.
ExpertMatcher: Automating ML Model Selection for Clients using Hidden Representations
Oct 09, 2019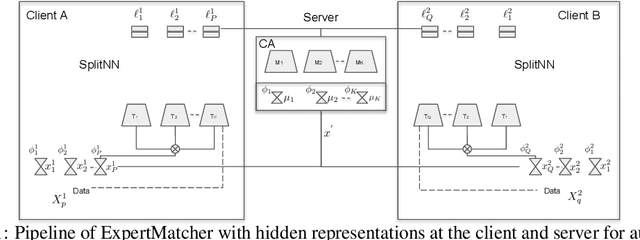


Recently, there has been the development of Split Learning, a framework for distributed computation where model components are split between the client and server (Vepakomma et al., 2018b). As Split Learning scales to include many different model components, there needs to be a method of matching client-side model components with the best server-side model components. A solution to this problem was introduced in the ExpertMatcher (Sharma et al., 2019) framework, which uses autoencoders to match raw data to models. In this work, we propose an extension of ExpertMatcher, where matching can be performed without the need to share the client's raw data representation. The technique is applicable to situations where there are local clients and centralized expert ML models, but the sharing of raw data is constrained.
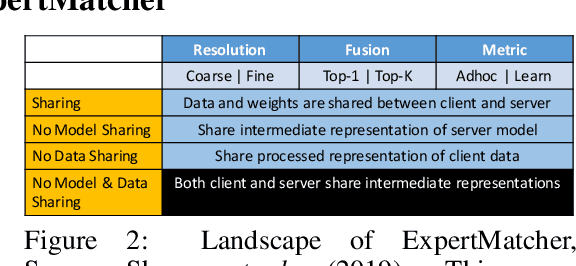
ExpertMatcher: Automating ML Model Selection for Users in Resource Constrained Countries
Oct 05, 2019
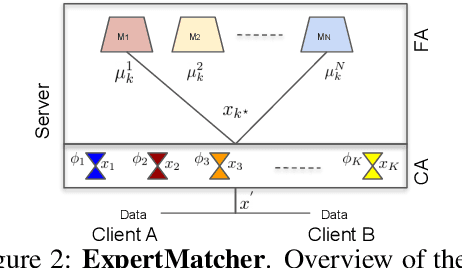
In this work we introduce ExpertMatcher, a method for automating deep learning model selection using autoencoders. Specifically, we are interested in performing inference on data sources that are distributed across many clients using pretrained expert ML networks on a centralized server. The ExpertMatcher assigns the most relevant model(s) in the central server given the client's data representation. This allows resource-constrained clients in developing countries to utilize the most relevant ML models for their given task without having to evaluate the performance of each ML model. The method is generic and can be beneficial in any setup where there are local clients and numerous centralized expert ML models.
Data Markets to support AI for All: Pricing, Valuation and Governance
May 14, 2019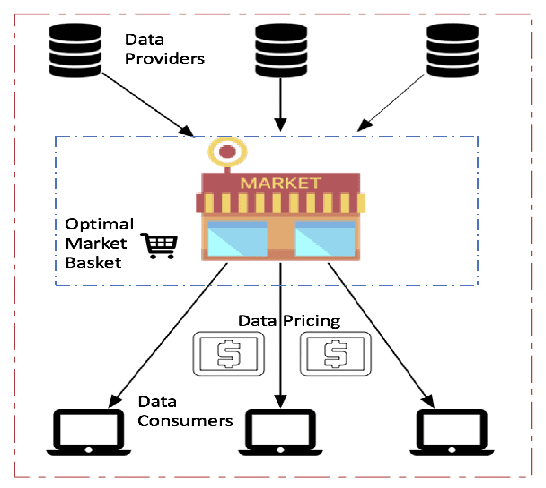

We discuss a data market technique based on intrinsic (relevance and uniqueness) as well as extrinsic value (influenced by supply and demand) of data. For intrinsic value, we explain how to perform valuation of data in absolute terms (i.e just by itself), or relatively (i.e in comparison to multiple datasets) or in conditional terms (i.e valuating new data given currently existing data).
No Peek: A Survey of private distributed deep learning
Dec 08, 2018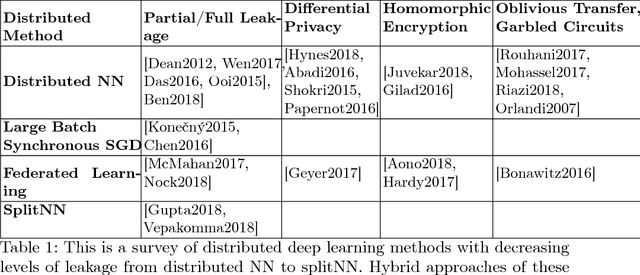
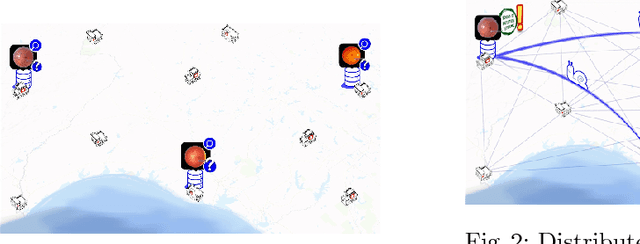
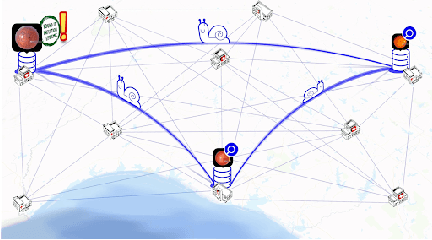
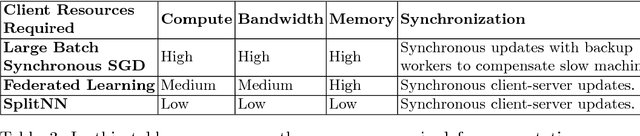
We survey distributed deep learning models for training or inference without accessing raw data from clients. These methods aim to protect confidential patterns in data while still allowing servers to train models. The distributed deep learning methods of federated learning, split learning and large batch stochastic gradient descent are compared in addition to private and secure approaches of differential privacy, homomorphic encryption, oblivious transfer and garbled circuits in the context of neural networks. We study their benefits, limitations and trade-offs with regards to computational resources, data leakage and communication efficiency and also share our anticipated future trends.
Split learning for health: Distributed deep learning without sharing raw patient data
Dec 03, 2018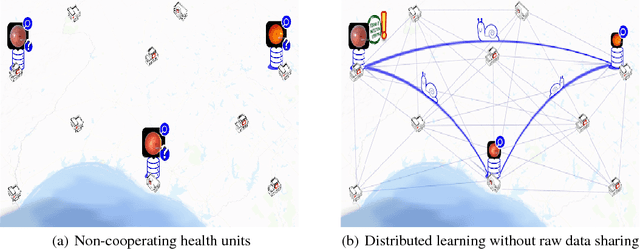

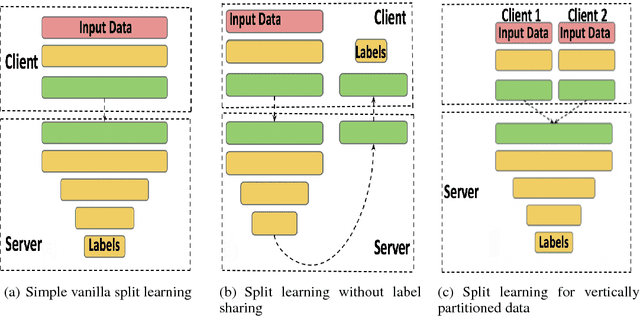

Can health entities collaboratively train deep learning models without sharing sensitive raw data? This paper proposes several configurations of a distributed deep learning method called SplitNN to facilitate such collaborations. SplitNN does not share raw data or model details with collaborating institutions. The proposed configurations of splitNN cater to practical settings of i) entities holding different modalities of patient data, ii) centralized and local health entities collaborating on multiple tasks and iii) learning without sharing labels. We compare performance and resource efficiency trade-offs of splitNN and other distributed deep learning methods like federated learning, large batch synchronous stochastic gradient descent and show highly encouraging results for splitNN.
3D Traffic Simulation for Autonomous Vehicles in Unity and Python
Oct 30, 2018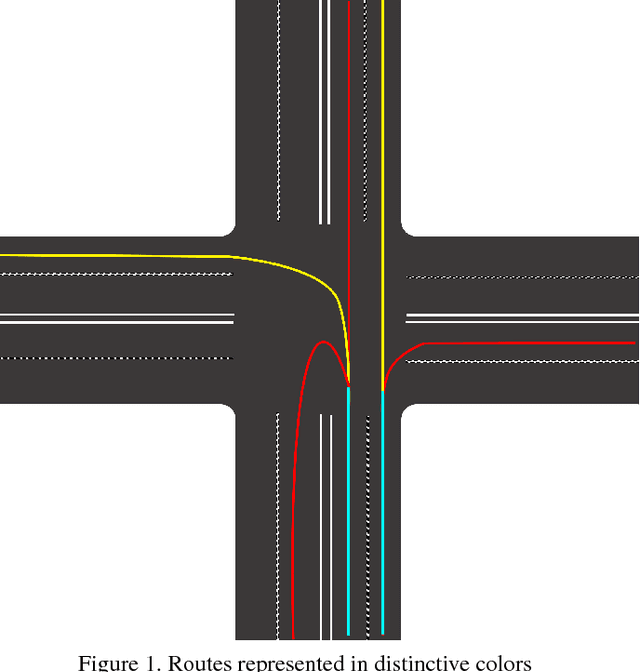
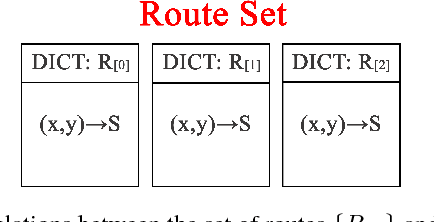

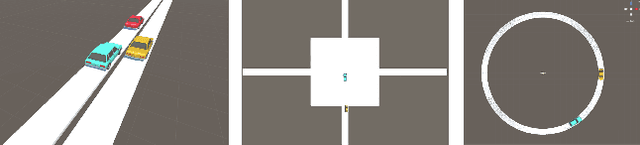
Over the recent years, there has been an explosion of studies on autonomous vehicles. Many collected large amount of data from human drivers. However, compared to the tedious data collection approach, building a virtual simulation of traffic makes the autonomous vehicle research more flexible, time-saving, and scalable. Our work features a 3D simulation that takes in real time position information parsed from street cameras. The simulation can easily switch between a global bird view of the traffic and a local perspective of a car. It can also filter out certain objects in its customized camera, creating various channels for objects of different categories. This provides alternative supervised or unsupervised ways to train deep neural networks. Another advantage of the 3D simulation is its conformation to physical laws. Its naturalness to accelerate and collide prepares the system for potential deep reinforcement learning needs.