 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Event Cameras
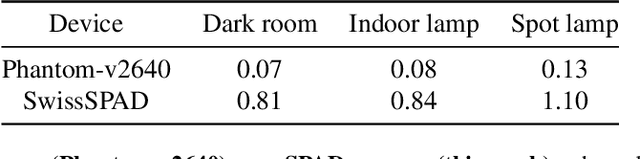
Jul 02, 2024Event cameras capture the world at high time resolution and with minimal bandwidth requirements. However, event streams, which only encode changes in brightness, do not contain sufficient scene information to support a wide variety of downstream tasks. In this work, we design generalized event cameras that inherently preserve scene intensity in a bandwidth-efficient manner. We generalize event cameras in terms of when an event is generated and what information is transmitted. To implement our designs, we turn to single-photon sensors that provide digital access to individual photon detections; this modality gives us the flexibility to realize a rich space of generalized event cameras. Our single-photon event cameras are capable of high-speed, high-fidelity imaging at low readout rates. Consequently, these event cameras can support plug-and-play downstream inference, without capturing new event datasets or designing specialized event-vision models. As a practical implication, our designs, which involve lightweight and near-sensor-compatible computations, provide a way to use single-photon sensors without exorbitant bandwidth costs.
SoDaCam: Software-defined Cameras via Single-Photon Imaging
Sep 08, 2023



Reinterpretable cameras are defined by their post-processing capabilities that exceed traditional imaging. We present "SoDaCam" that provides reinterpretable cameras at the granularity of photons, from photon-cubes acquired by single-photon devices. Photon-cubes represent the spatio-temporal detections of photons as a sequence of binary frames, at frame-rates as high as 100 kHz. We show that simple transformations of the photon-cube, or photon-cube projections, provide the functionality of numerous imaging systems including: exposure bracketing, flutter shutter cameras, video compressive systems, event cameras, and even cameras that move during exposure. Our photon-cube projections offer the flexibility of being software-defined constructs that are only limited by what is computable, and shot-noise. We exploit this flexibility to provide new capabilities for the emulated cameras. As an added benefit, our projections provide camera-dependent compression of photon-cubes, which we demonstrate using an implementation of our projections on a novel compute architecture that is designed for single-photon imaging.
Single-Photon Structured Light
Apr 11, 2022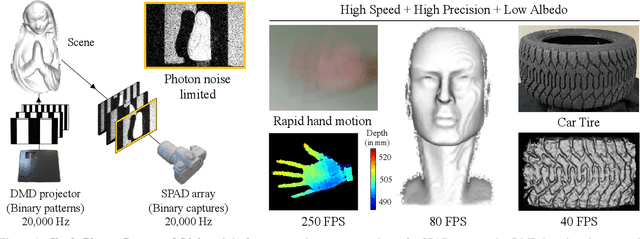


We present a novel structured light technique that uses Single Photon Avalanche Diode (SPAD) arrays to enable 3D scanning at high-frame rates and low-light levels. This technique, called "Single-Photon Structured Light", works by sensing binary images that indicates the presence or absence of photon arrivals during each exposure; the SPAD array is used in conjunction with a high-speed binary projector, with both devices operated at speeds as high as 20~kHz. The binary images that we acquire are heavily influenced by photon noise and are easily corrupted by ambient sources of light. To address this, we develop novel temporal sequences using error correction codes that are designed to be robust to short-range effects like projector and camera defocus as well as resolution mismatch between the two devices. Our lab prototype is capable of 3D imaging in challenging scenarios involving objects with extremely low albedo or undergoing fast motion, as well as scenes under strong ambient illumination.
[Reproducibility Report] Rigging the Lottery: Making All Tickets Winners
Mar 30, 2021![Figure 1 for [Reproducibility Report] Rigging the Lottery: Making All Tickets Winners](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fde178cb7d109a67449d7ba3b850e2c077c10b2ee%2F3-Table1-1.png&w=640&q=75)
![Figure 2 for [Reproducibility Report] Rigging the Lottery: Making All Tickets Winners](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fde178cb7d109a67449d7ba3b850e2c077c10b2ee%2F10-Table1-1.png&w=640&q=75)
![Figure 3 for [Reproducibility Report] Rigging the Lottery: Making All Tickets Winners](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fde178cb7d109a67449d7ba3b850e2c077c10b2ee%2F4-Table2-1.png&w=640&q=75)
![Figure 4 for [Reproducibility Report] Rigging the Lottery: Making All Tickets Winners](/_next/image?url=https%3A%2F%2Fai2-s2-public.s3.amazonaws.com%2Ffigures%2F2017-08-08%2Fde178cb7d109a67449d7ba3b850e2c077c10b2ee%2F12-Table2-1.png&w=640&q=75)
$\textit{RigL}$, a sparse training algorithm, claims to directly train sparse networks that match or exceed the performance of existing dense-to-sparse training techniques (such as pruning) for a fixed parameter count and compute budget. We implement $\textit{RigL}$ from scratch in Pytorch and reproduce its performance on CIFAR-10 within 0.1% of the reported value. On both CIFAR-10/100, the central claim holds -- given a fixed training budget, $\textit{RigL}$ surpasses existing dynamic-sparse training methods over a range of target sparsities. By training longer, the performance can match or exceed iterative pruning, while consuming constant FLOPs throughout training. We also show that there is little benefit in tuning $\textit{RigL}$'s hyper-parameters for every sparsity, initialization pair -- the reference choice of hyperparameters is often close to optimal performance. Going beyond the original paper, we find that the optimal initialization scheme depends on the training constraint. While the Erdos-Renyi-Kernel distribution outperforms the Uniform distribution for a fixed parameter count, for a fixed FLOP count, the latter performs better. Finally, redistributing layer-wise sparsity while training can bridge the performance gap between the two initialization schemes, but increases computational cost.
FlatNet: Towards Photorealistic Scene Reconstruction from Lensless Measurements
Oct 29, 2020

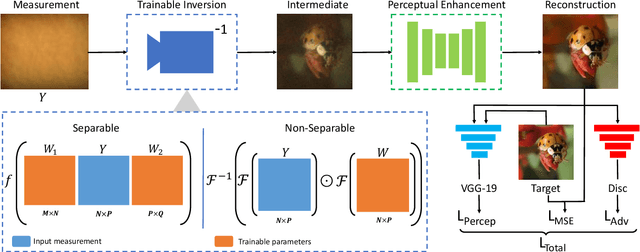
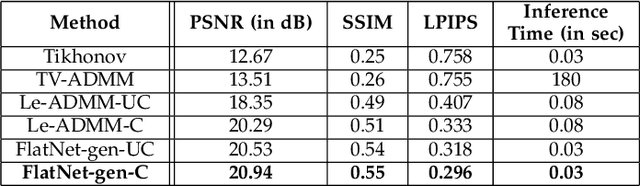
Lensless imaging has emerged as a potential solution towards realizing ultra-miniature cameras by eschewing the bulky lens in a traditional camera. Without a focusing lens, the lensless cameras rely on computational algorithms to recover the scenes from multiplexed measurements. However, the current iterative-optimization-based reconstruction algorithms produce noisier and perceptually poorer images. In this work, we propose a non-iterative deep learning based reconstruction approach that results in orders of magnitude improvement in image quality for lensless reconstructions. Our approach, called $\textit{FlatNet}$, lays down a framework for reconstructing high-quality photorealistic images from mask-based lensless cameras, where the camera's forward model formulation is known. FlatNet consists of two stages: (1) an inversion stage that maps the measurement into a space of intermediate reconstruction by learning parameters within the forward model formulation, and (2) a perceptual enhancement stage that improves the perceptual quality of this intermediate reconstruction. These stages are trained together in an end-to-end manner. We show high-quality reconstructions by performing extensive experiments on real and challenging scenes using two different types of lensless prototypes: one which uses a separable forward model and another, which uses a more general non-separable cropped-convolution model. Our end-to-end approach is fast, produces photorealistic reconstructions, and is easy to adopt for other mask-based lensless cameras.
Deep Atrous Guided Filter for Image Restoration in Under Display Cameras
Sep 01, 2020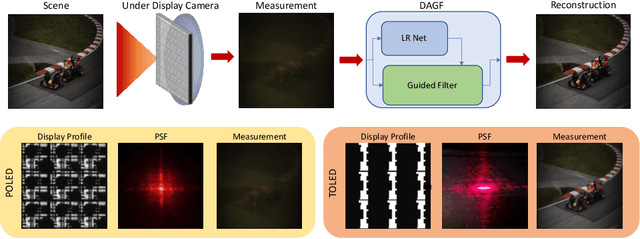
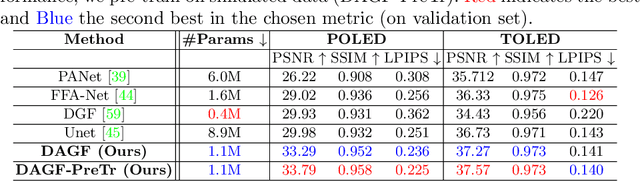
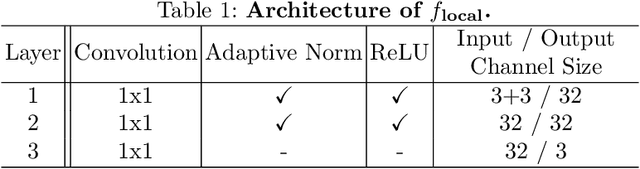

Under Display Cameras present a promising opportunity for phone manufacturers to achieve bezel-free displays by positioning the camera behind semi-transparent OLED screens. Unfortunately, such imaging systems suffer from severe image degradation due to light attenuation and diffraction effects. In this work, we present Deep Atrous Guided Filter (DAGF), a two-stage, end-to-end approach for image restoration in UDC systems. A Low-Resolution Network first restores image quality at low-resolution, which is subsequently used by the Guided Filter Network as a filtering input to produce a high-resolution output. Besides the initial downsampling, our low-resolution network uses multiple, parallel atrous convolutions to preserve spatial resolution and emulates multi-scale processing. Our approach's ability to directly train on megapixel images results in significant performance improvement. We additionally propose a simple simulation scheme to pre-train our model and boost performance. Our overall framework ranks 2nd and 5th in the RLQ-TOD'20 UDC Challenge for POLED and TOLED displays, respectively.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020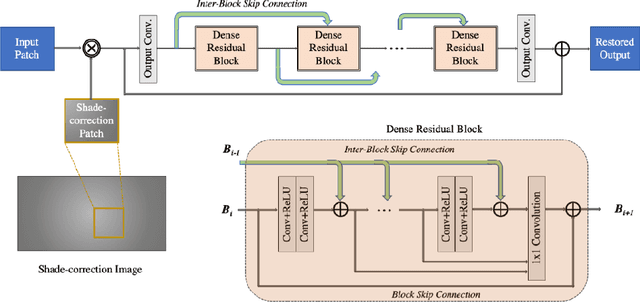
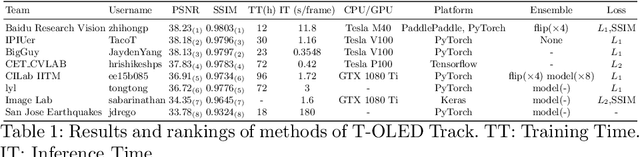
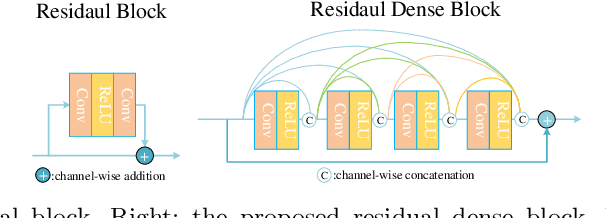
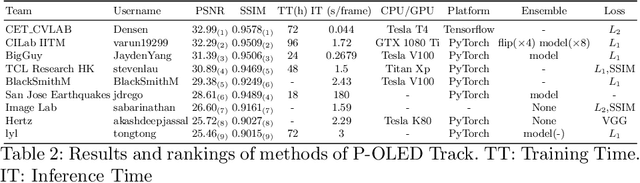
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.