 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartPhotoCrafter: Unified Reasoning, Generation and Optimization for Automatic Photographic Image Editing
Apr 21, 2026Traditional photographic image editing typically requires users to possess sufficient aesthetic understanding to provide appropriate instructions for adjusting image quality and camera parameters. However, this paradigm relies on explicit human instruction of aesthetic intent, which is often ambiguous, incomplete, or inaccessible to non-expert users. In this work, we propose SmartPhotoCrafter, an automatic photographic image editing method which formulates image editing as a tightly coupled reasoning-to-generation process. The proposed model first performs image quality comprehension and identifies deficiencies by the Image Critic module, and then the Photographic Artist module realizes targeted edits to enhance image appeal, eliminating the need for explicit human instructions. A multi-stage training pipeline is adopted: (i) Foundation pretraining to establish basic aesthetic understanding and editing capabilities, (ii) Adaptation with reasoning-guided multi-edit supervision to incorporate rich semantic guidance, and (iii) Coordinated reasoning-to generation reinforcement learning to jointly optimize reasoning and generation. During training, SmartPhotoCrafter emphasizes photo-realistic image generation, while supporting both image restoration and retouching tasks with consistent adherence to color- and tone-related semantics. We also construct a stage-specific dataset, which progressively builds reasoning and controllable generation, effective cross-module collaboration, and ultimately high-quality photographic enhancement. Experiments demonstrate that SmartPhotoCrafter outperforms existing generative models on the task of automatic photographic enhancement, achieving photo-realistic results while exhibiting higher tonal sensitivity to retouching instructions. Project page: https://github.com/vivoCameraResearch/SmartPhotoCrafter.
AgentLTV: An Agent-Based Unified Search-and-Evolution Framework for Automated Lifetime Value Prediction
Feb 25, 2026Lifetime Value (LTV) prediction is critical in advertising, recommender systems, and e-commerce. In practice, LTV data patterns vary across decision scenarios. As a result, practitioners often build complex, scenario-specific pipelines and iterate over feature processing, objective design, and tuning. This process is expensive and hard to transfer. We propose AgentLTV, an agent-based unified search-and-evolution framework for automated LTV modeling. AgentLTV treats each candidate solution as an {executable pipeline program}. LLM-driven agents generate code, run and repair pipelines, and analyze execution feedback. Two decision agents coordinate a two-stage search. The Monte Carlo Tree Search (MCTS) stage explores a broad space of modeling choices under a fixed budget, guided by the Polynomial Upper Confidence bounds for Trees criterion and a Pareto-aware multi-metric value function. The Evolutionary Algorithm (EA) stage refines the best MCTS program via island-based evolution with crossover, mutation, and migration. Experiments on a large-scale proprietary dataset and a public benchmark show that AgentLTV consistently discovers strong models across ranking and error metrics. Online bucket-level analysis further indicates improved ranking consistency and value calibration, especially for high-value and negative-LTV segments. We summarize practitioner-oriented takeaways: use MCTS for rapid adaptation to new data patterns, use EA for stable refinement, and validate deployment readiness with bucket-level ranking and calibration diagnostics. The proposed AgentLTV has been successfully deployed online.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
FAPE-IR: Frequency-Aware Planning and Execution Framework for All-in-One Image Restoration
Nov 18, 2025All-in-One Image Restoration (AIO-IR) aims to develop a unified model that can handle multiple degradations under complex conditions. However, existing methods often rely on task-specific designs or latent routing strategies, making it hard to adapt to real-world scenarios with various degradations. We propose FAPE-IR, a Frequency-Aware Planning and Execution framework for image restoration. It uses a frozen Multimodal Large Language Model (MLLM) as a planner to analyze degraded images and generate concise, frequency-aware restoration plans. These plans guide a LoRA-based Mixture-of-Experts (LoRA-MoE) module within a diffusion-based executor, which dynamically selects high- or low-frequency experts, complemented by frequency features of the input image. To further improve restoration quality and reduce artifacts, we introduce adversarial training and a frequency regularization loss. By coupling semantic planning with frequency-based restoration, FAPE-IR offers a unified and interpretable solution for all-in-one image restoration. Extensive experiments show that FAPE-IR achieves state-of-the-art performance across seven restoration tasks and exhibits strong zero-shot generalization under mixed degradations.
Efficient Speculative Decoding for Llama at Scale: Challenges and Solutions
Aug 11, 2025Speculative decoding is a standard method for accelerating the inference speed of large language models. However, scaling it for production environments poses several engineering challenges, including efficiently implementing different operations (e.g., tree attention and multi-round speculative decoding) on GPU. In this paper, we detail the training and inference optimization techniques that we have implemented to enable EAGLE-based speculative decoding at a production scale for Llama models. With these changes, we achieve a new state-of-the-art inference latency for Llama models. For example, Llama4 Maverick decodes at a speed of about 4 ms per token (with a batch size of one) on 8 NVIDIA H100 GPUs, which is 10% faster than the previously best known method. Furthermore, for EAGLE-based speculative decoding, our optimizations enable us to achieve a speed-up for large batch sizes between 1.4x and 2.0x at production scale.
DSDNet: Raw Domain Demoiréing via Dual Color-Space Synergy
Apr 22, 2025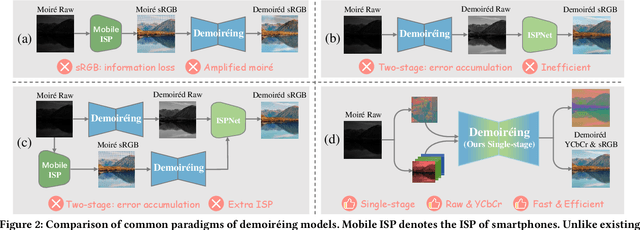
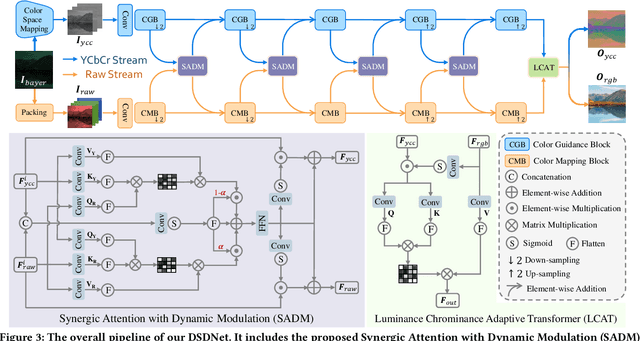
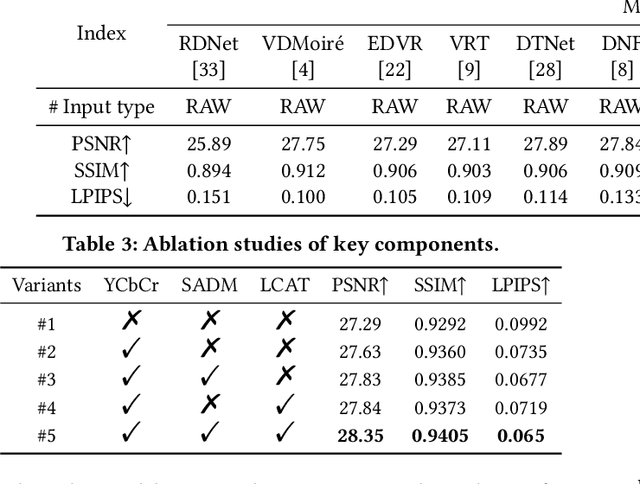
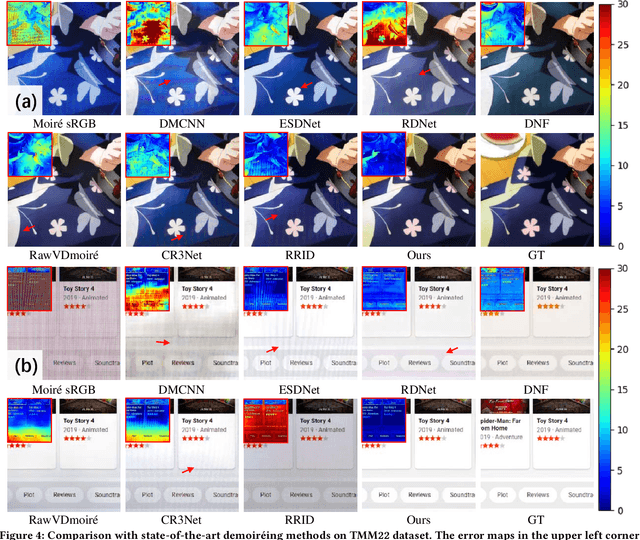
With the rapid advancement of mobile imaging, capturing screens using smartphones has become a prevalent practice in distance learning and conference recording. However, moir\'e artifacts, caused by frequency aliasing between display screens and camera sensors, are further amplified by the image signal processing pipeline, leading to severe visual degradation. Existing sRGB domain demoir\'eing methods struggle with irreversible information loss, while recent two-stage raw domain approaches suffer from information bottlenecks and inference inefficiency. To address these limitations, we propose a single-stage raw domain demoir\'eing framework, Dual-Stream Demoir\'eing Network (DSDNet), which leverages the synergy of raw and YCbCr images to remove moir\'e while preserving luminance and color fidelity. Specifically, to guide luminance correction and moir\'e removal, we design a raw-to-YCbCr mapping pipeline and introduce the Synergic Attention with Dynamic Modulation (SADM) module. This module enriches the raw-to-sRGB conversion with cross-domain contextual features. Furthermore, to better guide color fidelity, we develop a Luminance-Chrominance Adaptive Transformer (LCAT), which decouples luminance and chrominance representations. Extensive experiments demonstrate that DSDNet outperforms state-of-the-art methods in both visual quality and quantitative evaluation, and achieves an inference speed $\mathrm{\textbf{2.4x}}$ faster than the second-best method, highlighting its practical advantages. We provide an anonymous online demo at https://xxxxxxxxdsdnet.github.io/DSDNet/.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Bayesian Neural Networks for One-to-Many Mapping in Image Enhancement
Jan 24, 2025



In image enhancement tasks, such as low-light and underwater image enhancement, a degraded image can correspond to multiple plausible target images due to dynamic photography conditions, such as variations in illumination. This naturally results in a one-to-many mapping challenge. To address this, we propose a Bayesian Enhancement Model (BEM) that incorporates Bayesian Neural Networks (BNNs) to capture data uncertainty and produce diverse outputs. To achieve real-time inference, we introduce a two-stage approach: Stage I employs a BNN to model the one-to-many mappings in the low-dimensional space, while Stage II refines fine-grained image details using a Deterministic Neural Network (DNN). To accelerate BNN training and convergence, we introduce a dynamic \emph{Momentum Prior}. Extensive experiments on multiple low-light and underwater image enhancement benchmarks demonstrate the superiority of our method over deterministic models.
Learning Adaptive Lighting via Channel-Aware Guidance
Dec 02, 2024



Learning lighting adaption is a key step in obtaining a good visual perception and supporting downstream vision tasks. There are multiple light-related tasks (e.g., image retouching and exposure correction) and previous studies have mainly investigated these tasks individually. However, we observe that the light-related tasks share fundamental properties: i) different color channels have different light properties, and ii) the channel differences reflected in the time and frequency domains are different. Based on the common light property guidance, we propose a Learning Adaptive Lighting Network (LALNet), a unified framework capable of processing different light-related tasks. Specifically, we introduce the color-separated features that emphasize the light difference of different color channels and combine them with the traditional color-mixed features by Light Guided Attention (LGA). The LGA utilizes color-separated features to guide color-mixed features focusing on channel differences and ensuring visual consistency across channels. We introduce dual domain channel modulation to generate color-separated features and a wavelet followed by a vision state space module to generate color-mixed features. Extensive experiments on four representative light-related tasks demonstrate that LALNet significantly outperforms state-of-the-art methods on benchmark tests and requires fewer computational resources. We provide an anonymous online demo at https://xxxxxx2025.github.io/LALNet/.
Learning Differential Pyramid Representation for Tone Mapping
Dec 02, 2024



Previous tone mapping methods mainly focus on how to enhance tones in low-resolution images and recover details using the high-frequent components extracted from the input image. These methods typically rely on traditional feature pyramids to artificially extract high-frequency components, such as Laplacian and Gaussian pyramids with handcrafted kernels. However, traditional handcrafted features struggle to effectively capture the high-frequency components in HDR images, resulting in excessive smoothing and loss of detail in the output image. To mitigate the above issue, we introduce a learnable Differential Pyramid Representation Network (DPRNet). Based on the learnable differential pyramid, our DPRNet can capture detailed textures and structures, which is crucial for high-quality tone mapping recovery. In addition, to achieve global consistency and local contrast harmonization, we design a global tone perception module and a local tone tuning module that ensure the consistency of global tuning and the accuracy of local tuning, respectively. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art methods, improving PSNR by 2.58 dB in the HDR+ dataset and 3.31 dB in the HDRI Haven dataset respectively compared with the second-best method. Notably, our method exhibits the best generalization ability in the non-homologous image and video tone mapping operation. We provide an anonymous online demo at https://xxxxxx2024.github.io/DPRNet/.