 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Event Cameras
Jul 02, 2024Event cameras capture the world at high time resolution and with minimal bandwidth requirements. However, event streams, which only encode changes in brightness, do not contain sufficient scene information to support a wide variety of downstream tasks. In this work, we design generalized event cameras that inherently preserve scene intensity in a bandwidth-efficient manner. We generalize event cameras in terms of when an event is generated and what information is transmitted. To implement our designs, we turn to single-photon sensors that provide digital access to individual photon detections; this modality gives us the flexibility to realize a rich space of generalized event cameras. Our single-photon event cameras are capable of high-speed, high-fidelity imaging at low readout rates. Consequently, these event cameras can support plug-and-play downstream inference, without capturing new event datasets or designing specialized event-vision models. As a practical implication, our designs, which involve lightweight and near-sensor-compatible computations, provide a way to use single-photon sensors without exorbitant bandwidth costs.
Streaming quanta sensors for online, high-performance imaging and vision
Jun 02, 2024



Recently quanta image sensors (QIS) -- ultra-fast, zero-read-noise binary image sensors -- have demonstrated remarkable imaging capabilities in many challenging scenarios. Despite their potential, the adoption of these sensors is severely hampered by (a) high data rates and (b) the need for new computational pipelines to handle the unconventional raw data. We introduce a simple, low-bandwidth computational pipeline to address these challenges. Our approach is based on a novel streaming representation with a small memory footprint, efficiently capturing intensity information at multiple temporal scales. Updating the representation requires only 16 floating-point operations/pixel, which can be efficiently computed online at the native frame rate of the binary frames. We use a neural network operating on this representation to reconstruct videos in real-time (10-30 fps). We illustrate why such representation is well-suited for these emerging sensors, and how it offers low latency and high frame rate while retaining flexibility for downstream computer vision. Our approach results in significant data bandwidth reductions ~100X and real-time image reconstruction and computer vision -- $10^4$-$10^5$ reduction in computation than existing state-of-the-art approach while maintaining comparable quality. To the best of our knowledge, our approach is the first to achieve online, real-time image reconstruction on QIS.
Eventful Transformers: Leveraging Temporal Redundancy in Vision Transformers
Aug 25, 2023



Vision Transformers achieve impressive accuracy across a range of visual recognition tasks. Unfortunately, their accuracy frequently comes with high computational costs. This is a particular issue in video recognition, where models are often applied repeatedly across frames or temporal chunks. In this work, we exploit temporal redundancy between subsequent inputs to reduce the cost of Transformers for video processing. We describe a method for identifying and re-processing only those tokens that have changed significantly over time. Our proposed family of models, Eventful Transformers, can be converted from existing Transformers (often without any re-training) and give adaptive control over the compute cost at runtime. We evaluate our method on large-scale datasets for video object detection (ImageNet VID) and action recognition (EPIC-Kitchens 100). Our approach leads to significant computational savings (on the order of 2-4x) with only minor reductions in accuracy.
Event Neural Networks
Dec 02, 2021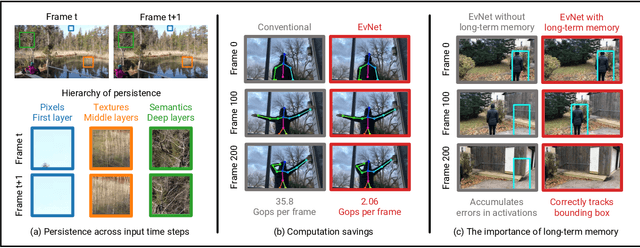
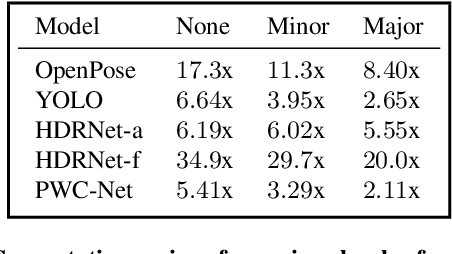
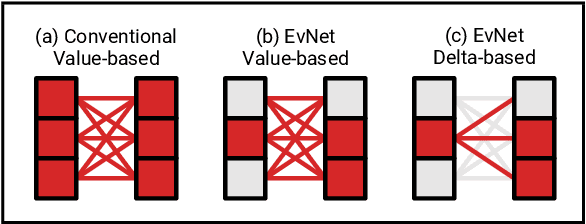
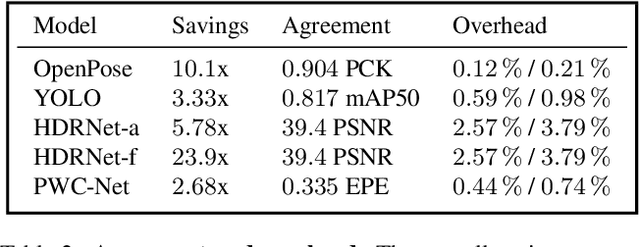
Video data is often repetitive; for example, the content of adjacent frames is usually strongly correlated. Such repetition occurs at multiple levels of complexity, from low-level pixel values to textures and high-level semantics. We propose Event Neural Networks (EvNets), a novel class of networks that leverage this repetition to achieve considerable computation savings for video inference tasks. A defining characteristic of EvNets is that each neuron has state variables that provide it with long-term memory, which allows low-cost inference even in the presence of significant camera motion. We show that it is possible to transform virtually any conventional neural into an EvNet. We demonstrate the effectiveness of our method on several state-of-the-art neural networks for both high- and low-level visual processing, including pose recognition, object detection, optical flow, and image enhancement. We observe up to an order-of-magnitude reduction in computational costs (2-20x) as compared to conventional networks, with minimal reductions in model accuracy.