 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Neural Networks
Paper and Code
Dec 02, 2021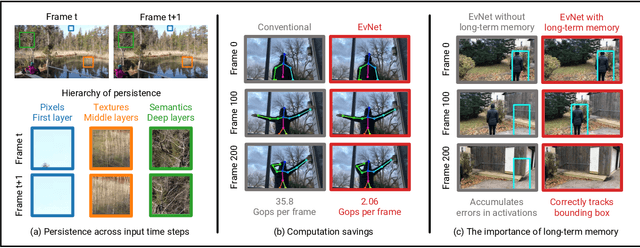
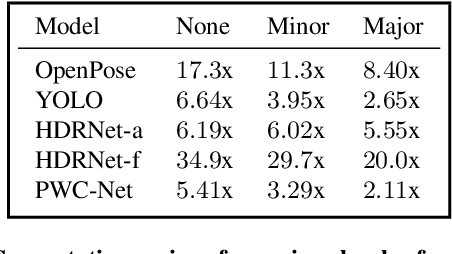
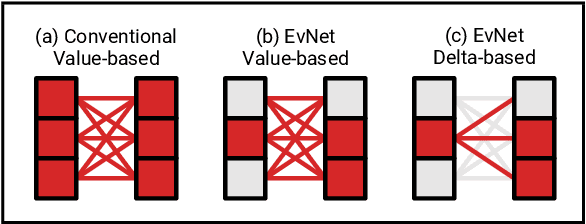
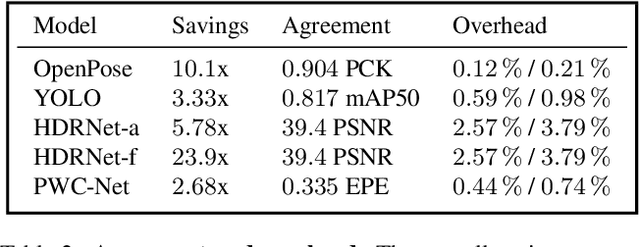
Video data is often repetitive; for example, the content of adjacent frames is usually strongly correlated. Such repetition occurs at multiple levels of complexity, from low-level pixel values to textures and high-level semantics. We propose Event Neural Networks (EvNets), a novel class of networks that leverage this repetition to achieve considerable computation savings for video inference tasks. A defining characteristic of EvNets is that each neuron has state variables that provide it with long-term memory, which allows low-cost inference even in the presence of significant camera motion. We show that it is possible to transform virtually any conventional neural into an EvNet. We demonstrate the effectiveness of our method on several state-of-the-art neural networks for both high- and low-level visual processing, including pose recognition, object detection, optical flow, and image enhancement. We observe up to an order-of-magnitude reduction in computational costs (2-20x) as compared to conventional networks, with minimal reductions in model accuracy.